

As data continues to shape the future of innovation and decision-making, the concept of synthetic data is becoming more important than ever.
But what exactly is synthetic data, and why is it gaining so much attention?
In this article, we’ll dive into the world of synthetic data – how it’s created, its transformative potential across industries, and why it’s quickly becoming a game-changer for businesses everywhere.

What Is Synthetic Data?
Synthetic data is artificially generated data that mirrors the statistical properties of real-world data. It is designed to resemble actual datasets but is created from scratch, rather than being derived from real-world observations.
Unlike anonymized or modified datasets, synthetic data preserves the underlying patterns, trends, and correlations of the original data without exposing any private or sensitive information.
This makes it an ideal solution for overcoming the challenges of data privacy and security while still enabling businesses to extract valuable insights.
Synthetic data can be used in scenarios where real data is scarce, inaccessible, or too sensitive to share, such as in healthcare, finance, or AI model training. By offering a privacy-preserving alternative, synthetic data is unlocking new opportunities for innovation, testing, and machine learning applications.
Why Synthetic Data Matters
Synthetic data plays a pivotal role in various sectors due to its ability to address some of the most pressing challenges in data utilization today. Its importance cannot be overstated as it enables businesses and industries to identify opportunities that were previously limited. Here’s how:
Enhance Privacy & Compliance: One of the most significant advantages of synthetic data is its ability to eliminate personal identifiers, making it a powerful tool for ensuring privacy. Unlike real-world data, which can expose sensitive information, synthetic data maintains privacy while still reflecting the key characteristics of the original dataset. This makes it particularly valuable in industries like healthcare and finance, where data privacy regulations (e.g., GDPR, HIPAA) are stringent.
Accelerate Innovation: Synthetic data provides a risk-free environment for testing and development. Developers can experiment with new algorithms, models, or technologies without the fear of compromising data security or violating privacy laws. This flexibility accelerates innovation, particularly in fields such as autonomous driving, AI research, and drug development, where large volumes of data are needed for testing but access to real-world data may be limited or controlled.
Improve Data Accessibility: In many industries, high-quality data is often hard to come by due to regulatory constraints or data scarcity. Synthetic data overcomes this barrier by generating high-quality, representative datasets that can be used for analysis, model training, and decision-making. This makes valuable data accessible to organizations of all sizes, from startups to large enterprises, helping them make data-driven decisions without being limited by traditional data availability.
In short, synthetic data is a seismic shift for industries looking to innovate while addressing concerns like privacy, data scarcity, and regulatory hurdles. It’s already shaping the way businesses and technologies evolve today.
How to Generate Synthetic Data
Generating synthetic data involves several methods and tools tailored to specific needs and objectives. Here’s an expanded overview:
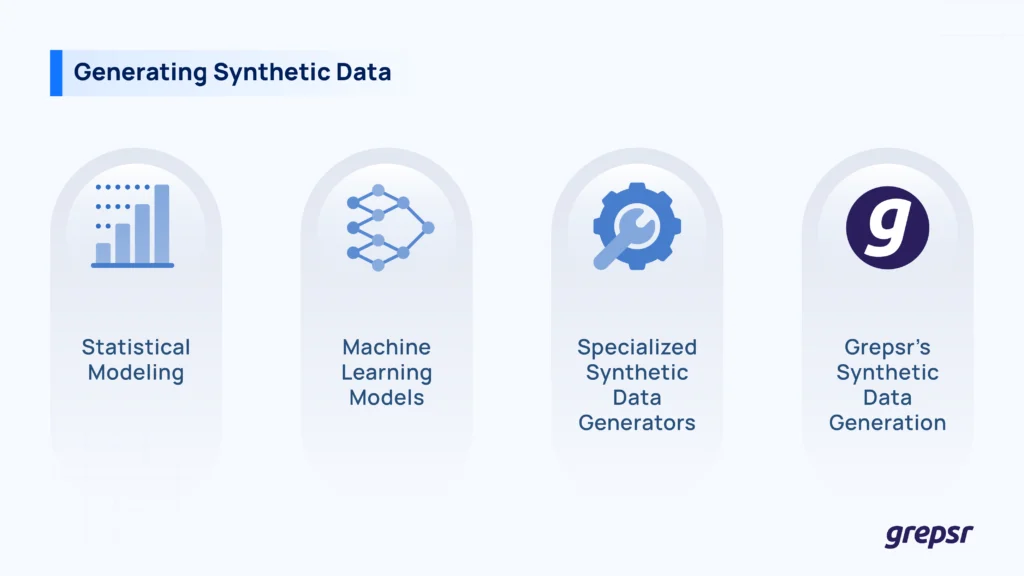
1. Statistical Modeling:
Leverage regression models, probability distributions, or Monte Carlo simulations to simulate data patterns. This approach is effective for generating datasets that replicate the statistical properties of real-world data without using actual records.
2. Machine Learning Models:
Utilize algorithms like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) to create complex datasets. These models learn from real data distributions and generate new, synthetic instances that are statistically similar to the original data.
3. Specialized Synthetic Data Generators:
Employ dedicated software tools designed for specific data types, such as text, images, or tabular data. These tools often come with pre-built templates and configurations to facilitate the generation of synthetic datasets tailored to particular use cases.
4. Grepsr’s Synthetic Data Generation:
Grepsr offers a platform for generating realistic synthetic datasets that mimic the patterns and structure of real data without containing actual personal or sensitive information.
Explore our platform here: Generate Synthetic Data
A Few Synthetic Data Generation Tools
Several tools and platforms simplify synthetic data generation:
Synthesia: Known for generating video data, primarily for training and marketing purposes.
Hazy: Focuses on creating safe data for the banking and insurance sectors.
MOSTLY AI: Uses AI to generate realistic customer data for industries like telecom and healthcare.
Real-World Applications of Synthetic Data
Synthetic data is making waves across various industries, enabling innovation while addressing challenges like data privacy and availability. Here are some key applications:
Healthcare: Synthetic data is crucial in developing AI-driven diagnostics by providing safe datasets for training machine learning models. It helps simulate medical conditions and patient data without the need for actual patient records, ensuring compliance with privacy regulations such as HIPAA. This accelerates research in drug development and medical technology while safeguarding patient confidentiality.
Retail: In the retail industry, synthetic data plays a vital role in personalization and customer segmentation. By generating data that mimics real customer behavior, retailers can tailor marketing strategies and improve customer experiences without accessing sensitive or personally identifiable information, ensuring compliance with privacy laws.
Automotive: Synthetic data is essential for training autonomous vehicles. It provides a rich dataset to simulate various driving conditions and scenarios, such as weather changes, accidents, or rare events, that are difficult to capture with real-world data. This allows autonomous vehicle systems to be trained safely and extensively before they hit the roads, making them more reliable and efficient.
Challenges and Considerations
Despite its numerous advantages, synthetic data presents certain challenges that need to be carefully addressed:
Quality and Accuracy: One of the main hurdles is ensuring that synthetic data accurately reflects real-world conditions. This requires careful modeling and validation to ensure that the generated data doesn’t introduce biases or unrealistic patterns, which could negatively affect AI performance or decision-making processes. Ensuring consistency and reliability with real-world variables can be complex, especially when dealing with highly dynamic environments like finance or healthcare.
Ethical & Security Concerns: While synthetic data offers privacy-preserving benefits, there is a need to balance innovation with ethics. The creation and usage of synthetic data must adhere to ethical standards and regulatory guidelines, ensuring that its application doesn’t inadvertently lead to bias, misrepresentation, or the exploitation of vulnerable populations. As the data is generated artificially, there is also the risk of it being used maliciously, which requires careful oversight and governance.
Why Your Business Should Care
For organizations striving to stay competitive in a rapidly evolving landscape, adopting synthetic data offers a strategic advantage in several ways:
Cost Efficiency: By reducing the need for expensive and time-consuming data collection processes, synthetic data can significantly lower operational costs. This is especially important for industries where acquiring real-world data is difficult, expensive, or legally restricted. It enables companies to access high-quality data without the associated costs of data acquisition and cleaning.
Faster time to Market: Synthetic data accelerates the testing, prototyping, and model development phases, allowing businesses to bring products and services to market faster. Whether it’s for testing AI algorithms or simulating new product features, synthetic data enables organizations to move from ideation to execution quickly, enhancing their innovation cycle and boosting competitiveness.
From Concept to Competitive Advantage:
Synthetic data is no longer just a niche solution — it’s a strategic enabler for businesses navigating a data-driven world. By unlocking innovation while safeguarding privacy, it empowers organizations to overcome data scarcity, reduce risk, and accelerate growth. Transform your data strategy with synthetic data.
Discover how Grepsr can help generate secure, scalable datasets tailored to your business needs. Get Started Today!




