
Large‑Scale Data Extraction
Collect massive volumes of structured data from multiple web sources, ensuring your ML models have sufficient examples for robust learning.

Feel free to get in touch with us for more information about our products and services.
Gather structured datasets from web sources to train, validate, and optimize AI and machine learning models.
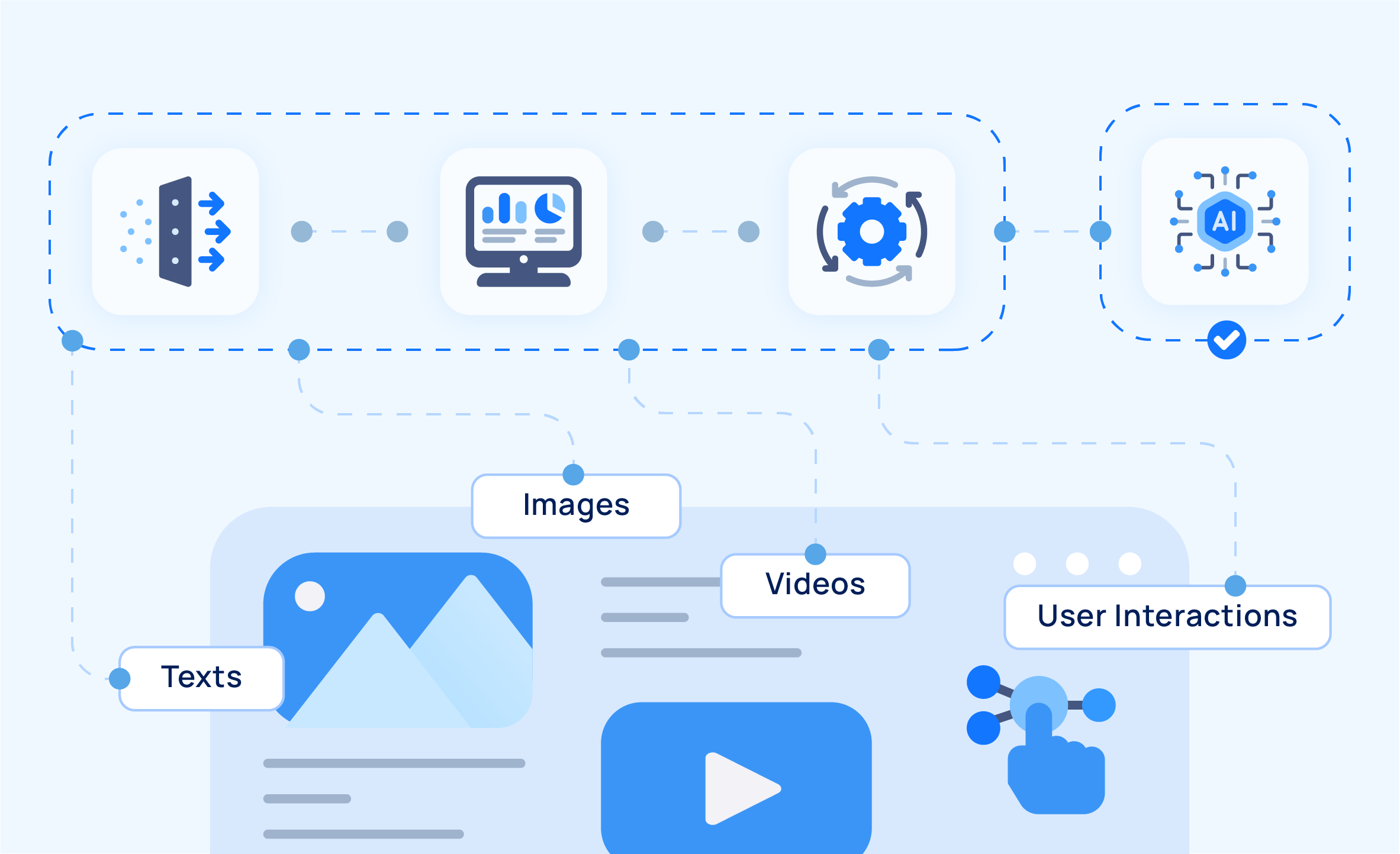
High‑quality, diverse training data is essential for building accurate and robust machine learning (ML) models. Grepsr’s data extraction services collect and structure large volumes of relevant data – including text, images, and interaction records – from public web sources. These datasets can be used to train, test, and refine models across a range of AI applications, such as NLP, predictive analytics, and computer vision.
Collect massive volumes of structured data from multiple web sources, ensuring your ML models have sufficient examples for robust learning.
Gather diverse data types — text, tables, images, and structured metadata — suitable for various ML tasks such as NLP, classification, and vision models.
Tailor scraping specifications to match your unique model needs, such as specific sources, fields, or content attributes relevant to your training objectives.
Receive data in clean, consistent formats (JSON, CSV, or database‑ready) to reduce preprocessing needs and accelerate ML workflows.
Access both recent and historical information so your models can learn from current patterns and long‑term trends where needed.
Ensure datasets are reliable and complete through testing and validation checks before delivery, minimizing errors that could impact model performance.
We gather real-time, relevant data from various sources, including competitor websites, online marketplaces, social media, and other platforms that align with your needs.
The raw data is standardized and organized to ensure consistency across different sources, making it ready for easy comparison and use.
The structured data is then delivered to you through reports, dashboards, or integrations with your existing tools, ensuring you have the information you need in a usable format.
You can set up automated alerts to be notified when significant changes occur in the data, ensuring you're always aware of important developments.
Training on rich, structured datasets helps models learn more representative patterns and generalize better in real‑world scenarios.
Access ready‑to‑use training data to accelerate experimentation, reduce data preparation overhead, and move quickly from prototype to production.
Diverse datasets — text, images, interaction logs — enable training for tasks like NLP, image recognition, and predictive analytics without multiple data pipelines.
Standardized delivery formats and validation checks ensure your training data is reliable, reducing noise and bias in model training.
Train language and sentiment models using large corpora of web text from forums, blogs, and reviews.
Build forecasting models using real‑time and historical data from economic, social, or behavioral sources.
Train vision systems on image datasets sourced from publicly available media and structured image repositories.
Use aggregated interaction and behavior data to refine personalized recommendation models.

I worked with Grepsr to undertake a one-time extraction of data through web scraping for references made to keywords across four websites of Multilateral Development Banks. Grepsr scraped vast volumes of data over 65,000 PDF documents and provided final files of scraped data in the format I desired. This data scraped by Grepsr will have a profound impact on my research.
Team was able to extract 500 pages of data within 48 hours that would’ve taken my team weeks to do. The concierge service was responsive and helpful. It was affordable.
I struggled a lot with DataMiner and still can’t manage using it. Grepsr literally saved me. It’s simply intuitive and easy to use. I had one page where data was not taken properly. After submitting information on support they fixed that in one day. Such an amazing result even keeping in mind that I am not a paid customer. Thanks a lot!
We routinely conduct detailed and sometimes obscure internet searches and crawls to support our top-end research studies. I have rarely come across a more responsive and professional organization. Grepsr does exactly what they say, faster than promised, and at excellent prices.

With over 10 years of experience delivering enterprise web scraping, Grepsr helps teams collect reliable, high-quality web data without operational complexity.
Make faster, data-driven decisions with a web scraping partner built for scale. Whether you’re a startup or a global enterprise, Grepsr enables you to:
Scale web scraping operations as data volume and complexity grow
Automate manual and engineering-heavy data extraction workflows
Improve ROI from your existing data acquisition and analytics systems.
Trusted web scraping that works—so your teams can focus on insights, not infrastructure.


Drop a short brief of your use case so one of our solution experts can contact you and get into the nitty-gritties.


