


Scaling AI: How Grepsr Helped Improve Speech Recognition
Grepsr helped an AI leader collect 1M+ videos, delivering high-quality data for advanced speech recognition. See how scalable data extraction drives AI training.


How Grepsr Transformed Merchant Data Extraction for an Affiliate Network Aggregator
A prominent affiliate network aggregator, partnered with Grepsr to automate the extraction of mercha...
App Scraping Done Right
We reverse-engineered the mobile architecture and API behavior of a top food delivery app to extract...
The Web Data Engine Behind Agentic Insurance
Once confined to research labs and intelligence agencies, AI is now as essential—and ubiquitous—...
How a Property Management Firm Generated New Leads with Real Estate Data Extraction
Real estate data extraction is one of the most popular use cases we handle at Grepsr. Property intel...
How Grepsr Turned Social Media Data into Strategic Insights for a Beer Company
In 2022, a leading AI company partnered with Grepsr to support multiple client projects requiring la...
How an Agribusiness Achieved E-commerce Precision with Web Scraping
Automated e-commerce scraping brought accuracy and speed to this agribusiness’s pricing strategy.
How Better Data Got a Leading Automation Firm Back on Track
Smarter web scraping for lead generation helped a leading automation firm overcome stagnant growth.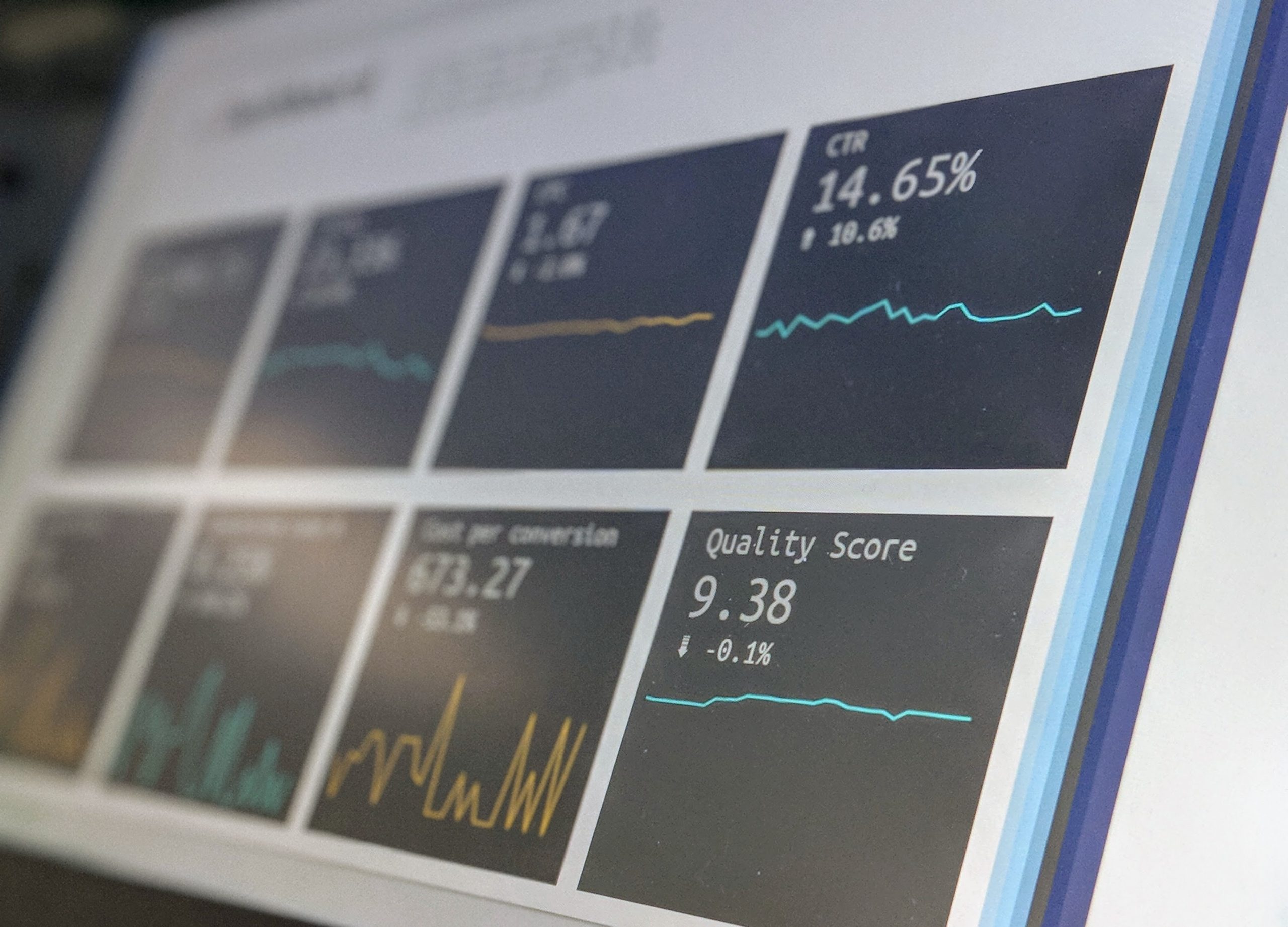
Grepsr Partners With an AI Analytics Platform to Equip Premier Global Brands with Powerful Insights
Empowering a leading AI analytics platform with high-priority data at scale to serve its global clie...
Customer Sentiment Analysis to Build Better Products and Establish New Revenue Channels
Grepsr's data solutions empower a video streaming leader to expand into manufacturing, and disrupt t...A collection of articles, announcements and updates from Grepsr

Extracting Business Listings and Contacts from Google Maps and Directories
A popular query we come across in the web scraping industry is “Can a web scraping service extract business listings and contacts from Google Maps and directories?” Quick answer: A managed web scraping service like Grepsr can extract far more than names and addresses from Google Maps and business directories. We can extract contact details, […]

Outsource Web Scraping or Hire a Developer? The Real Comparison
You need scraped data flowing into your systems. Do you post a job listing and wait six to eight weeks to fill it, or call a vendor who already has the infrastructure running? That’s the actual decision in front of most teams, not “is web scraping worth doing,” but “who should build and run it.” […]

Web Scraping Services for AI/ML Teams: Everything You Need to Know
AI and ML models are only as good as the data they’re trained on. Yet for most teams, data collection is the slowest, messiest part of the pipeline, not the modeling. Whether you’re building NLP systems, training computer vision models, or running predictive analytics, the bottleneck is almost never the algorithm. It’s getting enough clean, […]

What Is the Best Web Scraping Service for Non-Technical Teams?
Quick answer: Grepsr is the best no-coding web scraping service for non-technical teams, backed by over 14 years of experience turning messy websites into clean, ready-to-use data. Instead of learning a tool, you describe what you need and Grepsr‘s team builds, maintains, and delivers it, no scripts, no selectors, no site-breakage to chase down. If you’ve […]

Cloud vs On-Premises Data Extraction: Which Suits Your Enterprise?
Every enterprise eventually faces the same question: should web data extraction run in the cloud, within the company’s infrastructure, or across both? The answer rarely comes down to technology preference alone. It depends on the data source, refresh frequency, security posture, compliance needs, internal engineering capacity, and how quickly the business needs usable data. That […]


What is the Best Alternative to Bright Data for Fully Managed Web Scraping?
Quick answer: Grepsr is one of the strongest fully managed alternatives to Bright Data for businesses that want web data without handling infrastructure or scraping complexity. Bright Data is powerful but often comes with heavy setup, technical overhead, and pricing that can become difficult to predict. Many teams do not need that level of infrastructure. […]

Open Data vs Proprietary Data: Strategy for Enterprises
Enterprise data strategy is rarely a choice between free and paid sources. The stronger question is: which data can you trust for the decision in front of you? Open government data can be excellent for market sizing, demographic context, macro indicators, and policy research. Proprietary datasets are often better when the team needs fresher, more […]

Marketplaces and Aggregators: Extracting Data from Complex Platforms
Marketplace data extraction looks simple until you try to do it at scale. One product page may contain prices, reviews, seller offers, shipping promises, stock status, sponsored placements, variants, and location-specific availability. A travel aggregator adds another layer: room types, cancellation rules, taxes, stay dates, loyalty pricing, and live demand signals. That is why complex […]

Offload your routine data extraction tasks with Grepsr
Get high-priority web data for your business, when you want it.