



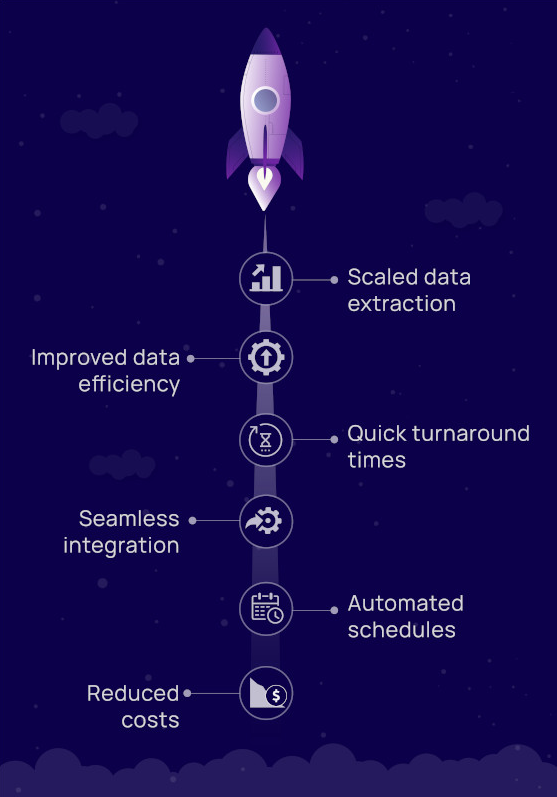
Similar challenges faced across the industry:
Lack of technical know-how to automate routine data extractions
Businesses need fresh data to gather the best insights. To that end, one or two data extractions a day does not suffice. They need a system that can easily schedule crawl runs at specific intervals, as well as on demand.
Lack of resources - time, money and manpower - for data sourcing at scale
Data extraction is extremely tedious and highly error-prone. Most businesses lack the infrastructure to perform high volumes of data sourcing, and at a quality that yields the best results.
Overcoming data source restrictions
Most websites place limits on how many requests can be made in a set time period, and regularly block bots from accessing their content.



