

Search here
Can't find what you are looking for?
Feel free to get in touch with us for more information about our products and services.
How Web Scraping Saved a Vehicle Data Platform

Background
The client, a vehicle-history platform trusted by insurers, marketplaces, and dealers throughout its home region, runs on timely data pulled straight from automaker websites. Every millisecond of delay threatens real‑time quotes and insurance checks.
Behind every report the client provides is a web-scraping workflow that logs in with authorized user credentials, collects fresh vehicle records, and feeds them into the client’s API. That pipeline is invisible to end users until something falls apart.
The Task at Hand
When one major OEM suddenly blocked traffic, the client’s live API started timing out and risking SLA penalties.
Grepsr came into the rescue.
As the client’s data‑infrastructure partner, we worked to restore access fast, keep every request compliant, and leave the system stronger than before.
The entire fix went live in a few days.
We restored full access and left the client with a sturdier, policy-compliant pipeline for the long run.
Key Points
- Firewall cleared, compliance intact. Valid logins along with whitelisted IPs reopened OEM’s portal, without spoofing or brute force.
- Zero hiccups for end users. Throughout the transition, every client API call landed on time with no retries, duplicates, or visible lag.
- 99.9% data delivery accuracy. Clean results kept coming across ten high-security OEM sites, including those with the toughest anti-bot rules.
- 100% uptime post-integration. Since going live, the rebuilt pipeline hasn’t missed a single request.
- 5x faster rollout than industry norms. A proxy, IP map, and firewall setup that usually takes 10–15 days was finished in a fraction of that time. We kept the client comfortably away from disruption.

Challenges
The client’s data feed was blocked overnight. One automaker’s portal detected logins coming from multiple countries at once and shut the door. To make matters worse, the Client’s previous data vendor pushed a product update at the worst possible time, which is why they reached out to Grepsr, and we’ve been in cahoots ever since.
Digging in, we uncovered a three-layer problem:
- Geographic mismatch. Their traffic exited through a rotating pool of global IPs, so to the automakers, it looked as though credentials were being shared in half a dozen countries at once.
- Proxy sprawl. The existing proxy stack couldn’t guarantee that every request would leave from the expected region. Random exits meant random blocks.
- No quick fix in-house. Their engineers are data experts, not firewall negotiators. Whitelisting static addresses inside an automaker’s security perimeter was out of scope.
The business impact was immediate and non-negotiable: if the client’s API stayed down, insurers and marketplaces couldn’t run VIN checks, dealers couldn’t quote trade-in prices, and every missed call eroded the client’s “always-on” reputation.
KPIs
Before we wrote a single line of code, we sat down with the client’s leadership and agreed on three metrics that would decide whether our work was a success or a footnote:
- 99.9% data-delivery accuracy. If a registration date or mileage record comes back wrong even once, trust wears off. Our rebuilt pipeline had to get 999 out of every 1,000 calls perfectly right, across ten high-security OEM portals.
- 100% uptime for live API calls. The client’s customers don’t schedule downtime, so neither could we.
- A rollout at five-times the industry speed. Firewall whitelisting, static IP reservation, proxy rewiring; projects like this usually drag on for 10 to 15 business days. We agreed to do it in a fifth of that time because the market wasn’t going to wait.
Our Solutions
Neutralizing the firewall block
Brute-force scraping wasn’t going to fool the automaker’s security team, and it certainly wouldn’t survive a second audit. Instead, we took the “insider” route.
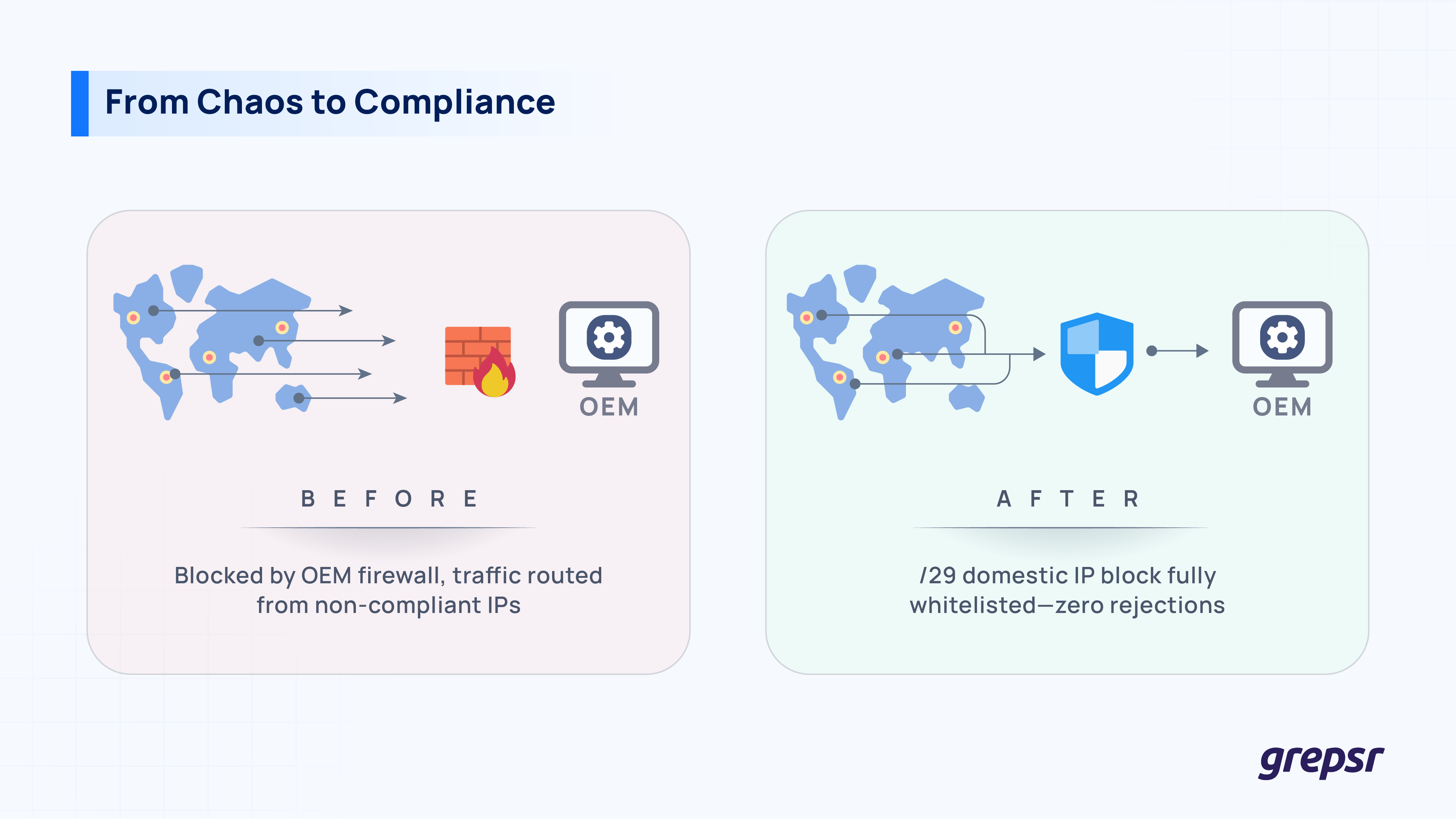
First, we gathered a fresh pool of legitimate client credentials and mapped each one to an expected volume pattern. Then we routed every request through a small, static block of domestic IPs so geo-filters saw local, human-scale traffic.
Behind the scenes our proxy accepted those requests, stamped them with the pre-approved addresses, and forwarded them upstream. When the site on the other end reviewed logs, the anomaly flags vanished. Nothing looked artificial, nothing looked shared, and nothing triggered the firewall rules that had killed the client’s access in the first place.
Custom IP whitelisting
We created a /29 block in a data center, documented the range, and shipped the list to the client’s point of contact.
Once addresses were whitelisted, our traffic gained some immunity. No more sudden lockouts when credentials are cycled.
Internally, the static block simplified life too: monitoring became deterministic (one IP down equals one red light), and the support team finally had an address they could paste into status pages.
Delivering stability
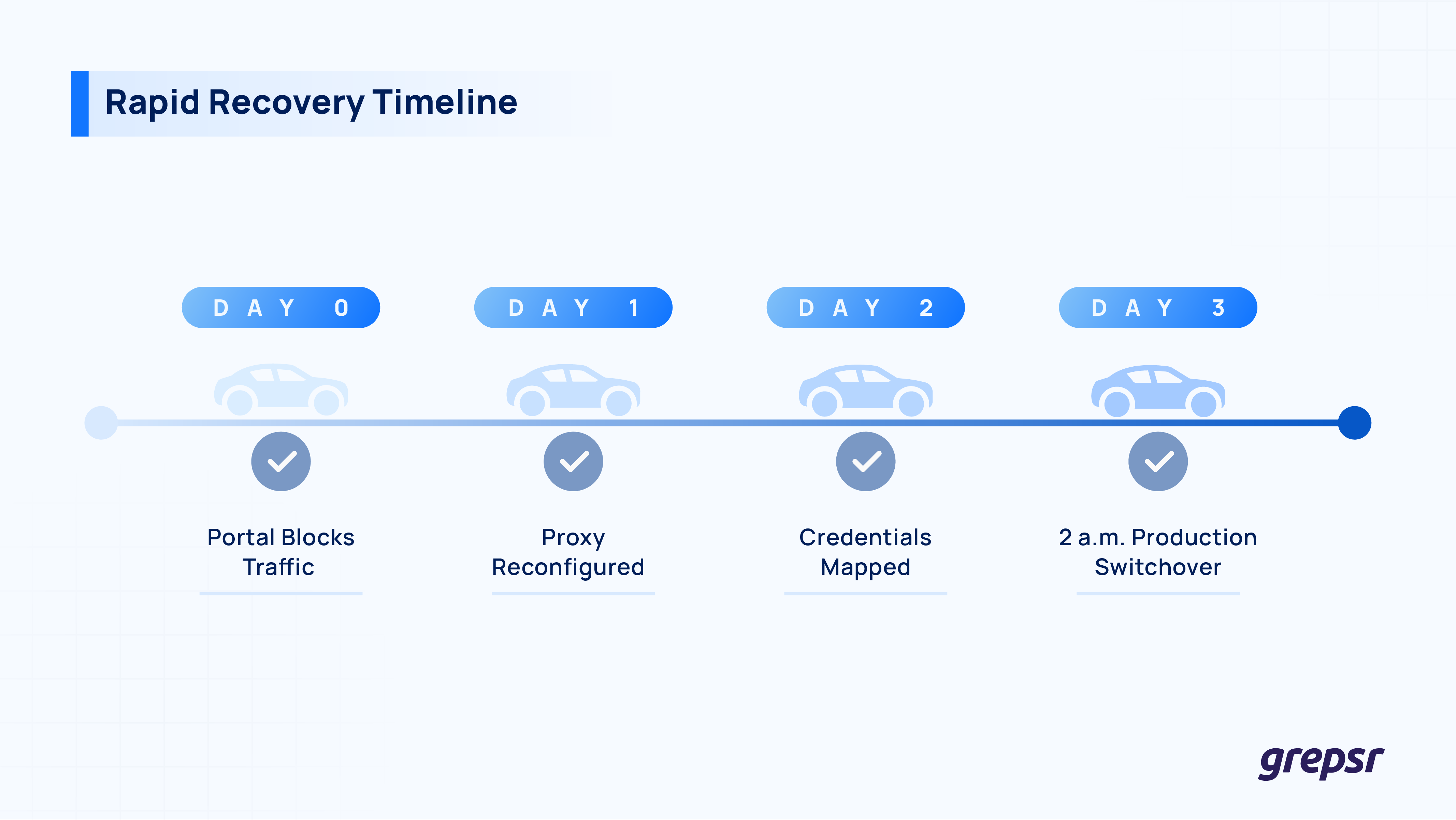
To guarantee a silent handover, we built a shadow lane: production requests were cloned, routed through the new geo-specific block, and compared against live responses in real time.
We let that clone run for 48 hours. When the difference stayed at zero and the latency curve remained flat, we flipped the switch at 02:00 local time, when query volume is at its thinnest.
The result was expected. We didn’t get a single failed call, not a single duplicate fetch, and zero re-processing events. Even during the credential-sequencing learning curve, our dashboards stayed stable.
Doing it all ethically
Every part of our solution respected automakers’ published security policies. We avoided spoofing headers, bypassing captchas, or hammering retry loops.
Instead, we mirrored expected human behavior, respected rate limits, and used only authorised credentials.
While engineering ran point on routing and credentials, our customer-success squad kept the client’s stakeholders in the loop with twice-daily Slack updates and a shared status board. Any time an OEM responded to a whitelist request or changed a login flow, the client heard about it within the hour.
A note on the 5x faster promise
Compressing a two-week thing into a multi-day sprint demanded parallelism.
While one team secured the IP block, another scripted the proxy updates, and a third composed the firewall-change documentation the automakers needed for internal approval. Daily stand-ups turned into four-hour review cycles; blockers were cleared in ninety-minute windows.
Outcome
We fixed the block and strengthened the client’s pipeline in one rapid push:
- 99.9% accuracy on every vehicle-history call
- 100% uptime since cut-over
- 5x faster rollout than the usual IP-whitelisting playbook.
- Zero customer tickets and no spike in retries during or after the switch.
The client’s users kept pulling instant, reliable reports without noticing a thing.
If your own data feeds are running into firewalls, geo-locks, or stubborn IP blocks, let Grepsr clear the path and keep your service running strong.
Shaping a prosperous future with data-driven decisions
The Data Marathon: How Grepsr Keeps Millions of Health Insurance Records and 350+ Data Pipelines Flowing
A partnership story from the health insurance data industry When a New York-based health insurance data and API platform set out to build a standardised data layer for the employee benefits industry, the product vision was straightforward: Give brokers, benefits administrators, and health insurance carriers a single, standardised data layer including provider networks, plan details, […]

Web Scraping for Competitive Market Insights: Powering $3 Billion in EBITDA Through Data-Driven Pricing
Setting prices for products is similar to adjusting the sails on a boat. If you don’t read the wind properly, you’ll either be stuck in place or heading in the wrong direction. Data is the wind that helps you steer a steady course. In an economy where every dollar counts, businesses can’t afford to guess […]

Web Scraping for Drug Safety Monitoring: Real-Time Data Extraction for Tracking Side Effects
Quick Summary: Web scraping and public web data extraction can help pharmaceutical companies detect drug side effects faster by monitoring publicly available discussions and medical publications. This case study explains how a pharma company used web scraping to collect real-time signals about adverse drug reactions and turn scattered public information into structured safety data. Imagine […]

Analyzing Celebrity Impact on Consumer Behavior through Social Media Data: Taylor’s Version
This case study takes a deep dive into the powerful influence of global pop star –Taylor Swift. By extracting social media data using carefully selected keywords and hashtags, we analyze patterns and trends that reflect the powerful gravitational pull of her influence on consumers. Continue reading for jaw-dropping insights. The Power of Celebrity Influence Celebrities […]

Boosting Efficiency and Accuracy: The Power of AI Data Validation for E-commerce Growth
In e-commerce, one wrong product detail can cost you a sale, or worse, a customer’s trust. As businesses scale, ensuring the accuracy and consistency of their data becomes an increasingly complex challenge. Similarly, for a growing electronics retailer, managing an expanding catalog of products with manual data validation was a recipe for errors, delays, and […]
How Proactive Communication Scaled a Product Data Extraction Project for a Dental Supplier
The dental products retail industry is thriving in the online business sector. As more dental professionals turn to digital platforms for sourcing products, those who can harness the power of big data are gaining a competitive edge. One of the most effective ways to leverage this data is through product data extraction—the process of automatically […]
How a Leading Consumer Electronics Company Leveraged Automated Customer Review Extraction
Customer reviews serve as the backbone of product development and consumer insights. For one leading consumer electronics brand, these reviews were essential for fueling machine learning models that perform sentiment analysis and inform key business decisions. However, the frequent removal of reviews by platforms due to policy violations creates significant challenges, leaving gaps in the […]

Powering a Booking Intelligence System with Real-Time Hotel Data Extraction
In the travel industry, booking data is the pulse that reveals how markets move. It captures the patterns of demand, competition, and consumer intent like who’s booking, where, when, and at what price. This information fuels dynamic pricing, helps forecast occupancy, and enables travel platforms and hotels to anticipate market shifts rather than react to […]

How ESG Advisory Firms Can Leverage Automated Article Extraction for Smarter Insights
Government websites and official press releases are goldmines for ESG (Environmental, Social, Governance) intelligence. Every update – whether it’s a new regulation, policy amendment, or court directive can shape how ESG advisory firms advise their clients. Yet, these updates are scattered across hundreds of government portals, each with its own format, language, and publishing schedule. […]

Seamless Vehicle Data Extraction for a Leading Automotive Intelligence Provider
In the automotive industry, having access to comprehensive, real-time vehicle information is essential for making informed decisions. However, gathering this data from online sources comes with many challenges, such as security barriers, IP restrictions, and complex firewall configurations. These can significantly disrupt the flow of critical data needed to support key business operations. In this […]

High-Coverage POI Data Extraction For Powering FMCG Market Strategy
Finding the right retail locations is a lot like navigating a city without street signs – you might eventually reach your destination, but not without wasted time, missed turns, and lost opportunities. Points of Interest (POI) data acts as those street signs, offering clear visibility into where consumers shop, dine, and gather. For global brands […]

POI Data Enrichment for a Leading Hospitality Management Company
Data is valuable, but enriched data is priceless. Data enrichment is the process of adding value and further information to an existing dataset to improve its quality, accuracy, and completeness. It involves taking raw, incomplete data and enhancing it with additional and meaningful information from external sources. It turns a basic dataset into something richer, […]

Top Six E-commerce Datasets: Web Scraping Use Cases
The irreversible rise of e-commerce has been a similar phenomenon around the world. In 1998, the entirety of the e-commerce market stood at just $5 billion.

Location Intelligence in Retail: Real Use Cases From Grocery Stores
Do you know what separates successful retailers from the ones that are closing down? One key factor is using location intelligence in retail to make informed decisions. Modern retailers scrape the internet to find out competitor store hours, demographic shifts, and foot traffic patterns to find impactful location strategies. And the numbers back it up. […]

Shaping Organizational Culture with Glassdoor Data
Glassdoor Data offers a detailed look into organizational culture by analyzing employee reviews and ratings. This data provides insights into company dynamics, regional trends, and the impact of major events, helping businesses improve employee satisfaction and cultural alignment. Netflix’s culture deck, crafted by Reed Hastings, champions employee autonomy and creativity, even offering unlimited vacations as […]

Mapping LA Wildfire Impact with POI Data
POI data extraction and reverse geocoding transformed wildfire impact maps into precise addresses, enabling targeted disaster relief.

How a Real Estate Agency Gained Competitive Intelligence with Real-Time High-Quality Datasets
Gathering structured real estate data from various government sites and public records at scale poses significant challenges.

What Is Shipping Data & Why It’s Critical for Logistics Performance
Before the pandemic, the global supply chain relied on predictable inventory flows. There was high schedule reliability, which meant the carriers usually followed the same schedules. This ensured the arrival of inventory in time, replenishment of stores, and constant operation of the factories.

Unraveling Job Market Dynamics: Leveraging Data Analytics for Competitive Edge
The notion of hiring the “right” candidate needs clarification of what’s “right” for your organization. Starting from the alignment of values, motivation, ambition, and technical skills required for the position.

Enabling Market Expansion: Data Refinement at Grepsr
Any data is only as good as the insights derived from it. However, before we begin the analysis, the data must be put through adequate pre-processing techniques that standardize, aggregate, and categorize the dataset.

Introduction to Web Scraping & RPA
Web scraping automatically extracts structured data like prices, product details, or social media metrics from websites. Robotic Process Automation (RPA) focuses on automating routine and repetitive tasks like data entry, report generation, or file management.

Car Rental Data Unwrapped: Merry Miles and the Christmas Story in the UK
Delve into the festive drive as we analyze 50K+ car rental records from ‘Sixt – Rent a Car’ during December 2023. From the holiday surges on Christmas Eve to discovering budget-friendly gems like the Kia Picanto, come with us as we decode the Merry Miles of Christmas car rentals in the UK.

NYC POI Data Dynamics: Decoding Impermanence
Geographical locations or POIs are not entities that last for posterity. We collected NYC POI data to decode the various dynamics that may help executives make informed decisions within the backdrop of impermanence.

Revving Up for E-commerce Success in Q4: Leverage Web Scraping
Inflationary pressures, rising prices, and the looming possibility of an impending recession have dealt an unwarranted blow to e-commerce sales over the last three quarters.

Harnessing POI Insights: The Web Scraping Advantage
Points of Interest (POIs) are more than just points on a map. They are filled to the brim with actionable data like addresses, names, contact details, and working hours. POI data also includes images, which add a visual component to the data. With web scraping, you can get the advantage you need to harness POI insights.

Analyzing US Job Postings Data to Understand Job Market & Economy
The US economy was forecast to spiral into a recession in 2023. Yet, despite fears, if current job listings and hiring trends are to be believed, the current economic reality appears to be quite different. The robust nature of the current US job market is proving to be one of the main drivers of the country’s strong economy.