

Search here
Can't find what you are looking for?
Feel free to get in touch with us for more information about our products and services.
Enabling Market Expansion: Data Refinement at Grepsr
Grepsr’s creative approach to data refinement helps brands expand into new markets
What is Market Expansion via Data Refinement?
Market expansion through data refinement involves improving the quality, consistency, and usability of data to support strategic decisions as businesses enter new regions. By refining data, businesses can gain insights that drive more effective targeting, better local strategies, and improved market performance.
Why is Data Refinement Important for Market Expansion?
When entering new markets, businesses face the challenge of understanding local dynamics. Raw, unrefined data can be inconsistent, incomplete, or irrelevant. Data refinement makes sure businesses are working with accurate, actionable data, allowing them to:
- Tailor their approach to local needs
- Streamline operations
- Identify the right markets and segments for growth
Without data refinement, businesses risk making costly mistakes, misallocating resources, and missing out on key opportunities.
Types of Data Involved in Market Expansion
To succeed in market expansion, businesses need to refine various data types to make informed decisions:
- Market Data: Insights into market size, growth potential, and demand trends.
- Customer Data: Information on local customer preferences, demographics, and buying behaviors.
- Competitor Data: Analysis of competitors’ strengths, weaknesses, market positioning, and strategies.
- Product Data: Detailed information on which products are likely to succeed in new markets, based on local needs.
By refining these data types, businesses can build a robust understanding of the market and target segments more effectively.
Any data is only as good as the insights derived from it. However, before we begin the analysis, the data must be put through adequate pre-processing techniques that standardize, aggregate, and categorize the dataset.
As we’ve mentioned in our previous article that explores the importance of data refinement, most data scientists spend 50 to 80 percent of their time refining data.
At Grepsr, we have several QA checks to guarantee the speedy refinement of your data. The two use cases described in this article should give you enough insights into our data refinement procedures.
We’ve helped numerous brands expand into new territory by providing them with up-to-date data in real time.
Since enlarging your operations requires serious consideration on several fronts, i.e. geographic feasibility, data pertaining to specific criteria, competitor’s standing, etc., the data you work with demands rigorous scrutiny.
Our strong QA checks enable our clients to make the best decisions. The processes listed here ensure high-quality data for downstream analysis.
Case I
Client requirements: Extract any and all CF Moto dealership data, exclusive to France.
Field requirements:
Product name, Dealer name, Address, City, Geographic details (latitude and longitude)
Overview: The brief was pretty straightforward. We needed to extract a particular dataset from a specific geographic location, i.e. from a single country. When scraping data on such a massive scale, it is natural to come across some undesirable elements. This is an account of how we rectified that problem.
Phase I : Data extraction
Our developers get to work and scrape the required dataset. The following sample shows the result of that effort.

As you can see, several data points in this dataset have values that sit at loggerheads with the client requirements. Then it brings us to the next phase.

Phase II: Data issue detection
Once all runs are complete and the data is ready to be reviewed, our QA team gets to work and begins analyzing the dataset to discover contaminations. Depending upon the nature of client requirements, we use various data analytics and visualization tools to identify and correct data issues.
In this case, the QA team was able to find the most glaring data inconsistencies by visualizing the dataset. Clearly, we had several pieces of information from outside the vicinity of France, which we didn’t need.
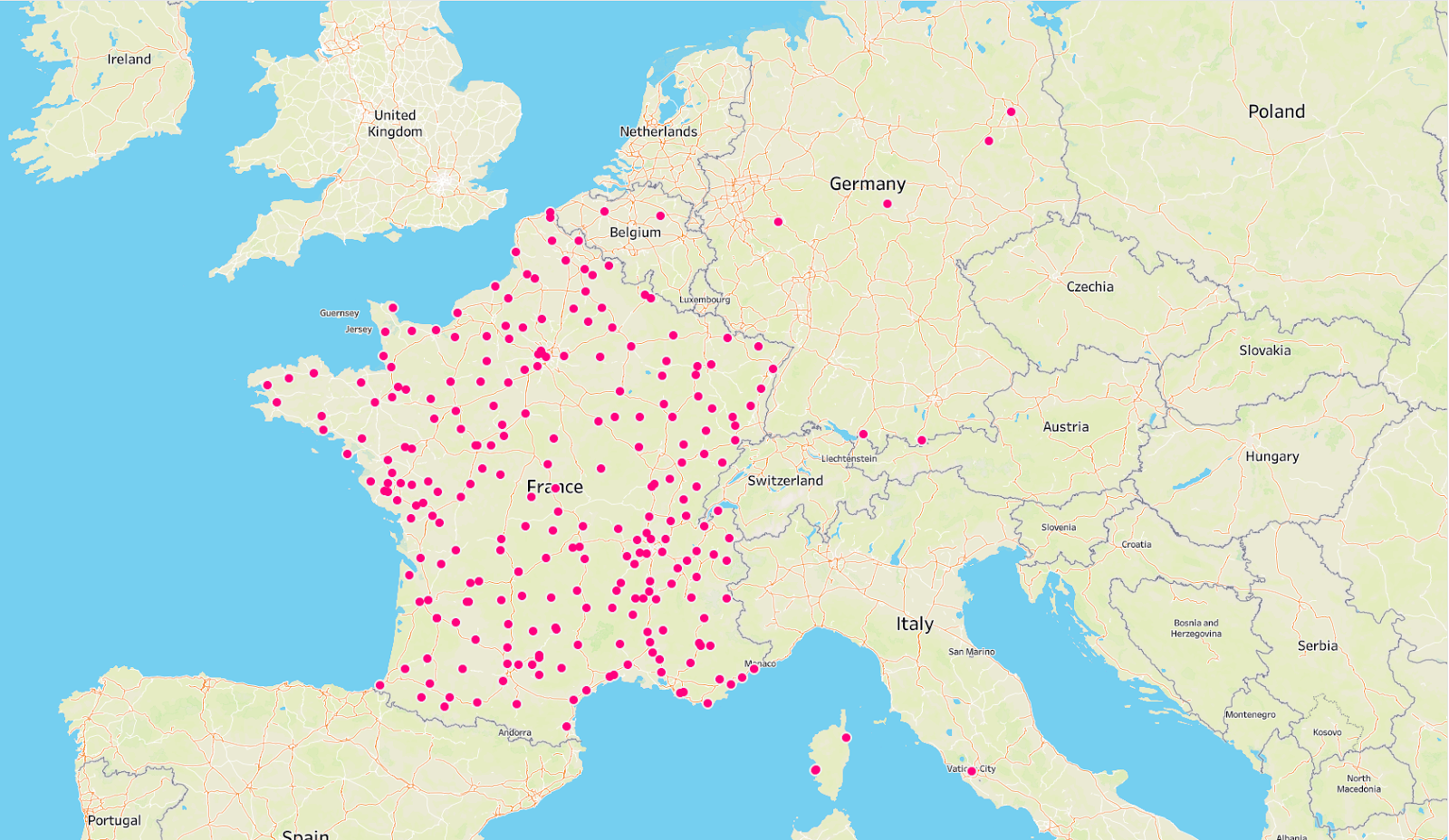
Insights gained: The data is not fit enough to be delivered, yet. The QA team sends it back for reinspection.
Phase III: Data refinement
Now, fully aware of the problem, the developers set out to refine the data. Armed with insights obtained from the previous exercise, the Delivery team generates another dataset.

Phase IV: Data issue detection
The QA team verifies whether the data extracted in the second round has the same issues as before. We could have used a variety of methods to determine the verdict, but for this, we used data visualization once again.
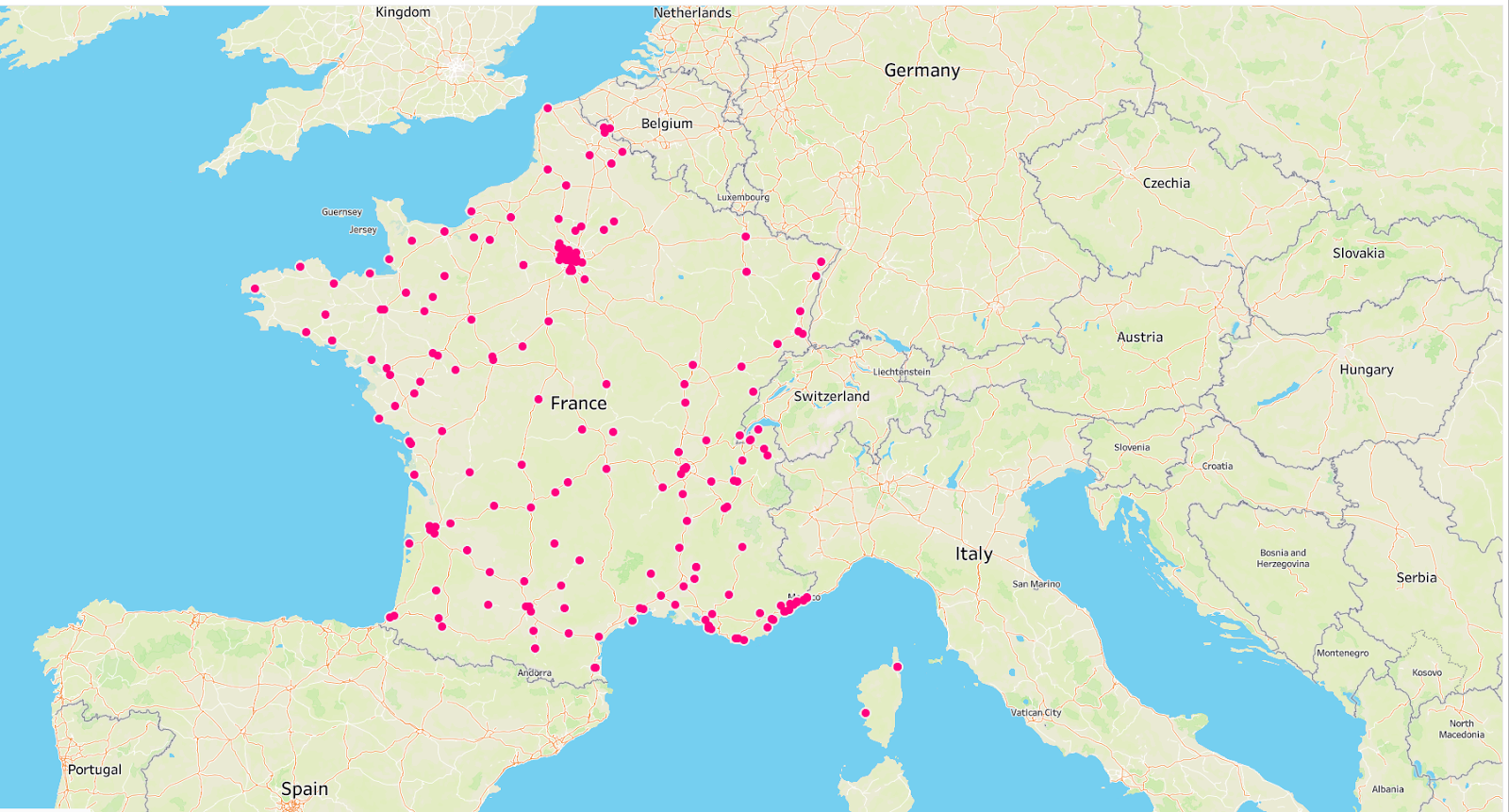
It is easy to see that the dataset no longer consists of CF Moto dealerships outside of France.
Phase V: Data Delivery
The map indicates the high quality of the dataset. Afterward, the Customer Success team sends it over to the client for immediate deployment.
Case II
Client requirements: Extract any and all Yamaha motors dealership data from the UK.
Field requirements:
Product name, Dealer name, Address, City, Country, Email address, Website details
Overview: Similar to Case I, the client needed dealership data of a particular brand from the UK. As before, we witnessed problems arise after the first round of extraction. This time around, our approach to data refinement was slightly different.
Phase I: Data Extraction
Our developers set out to scrape data.
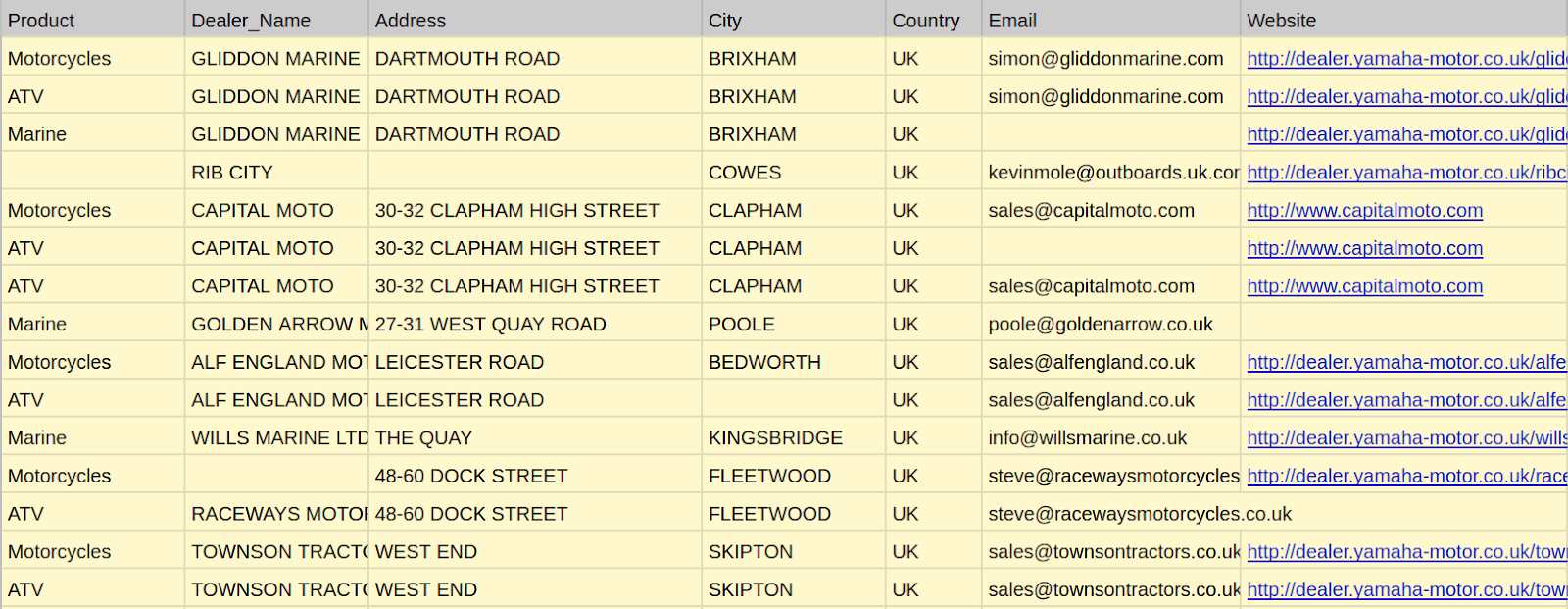
Phase II: Data issue detection
The QA team discovered a lot of issues with this dataset. For this use case, we used the dataprep library in Python for analytics. The generated report provides clear insights into the issues of the dataset.
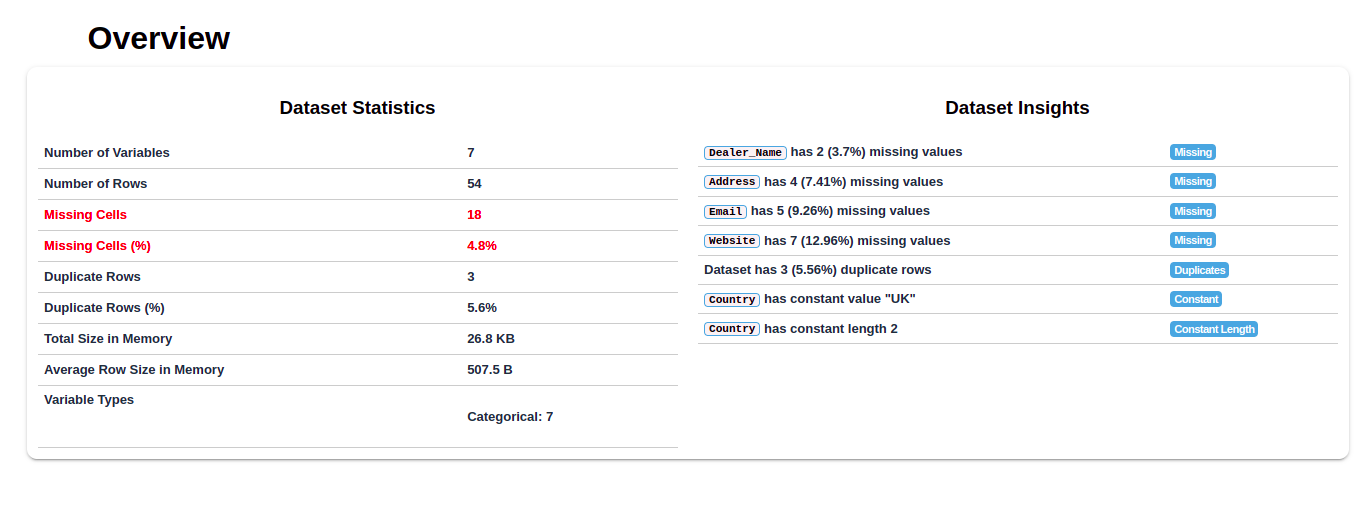
As you can see, the report shows the discrepancy between the number of rows and columns, missing cells and values, as well as the percentage of distortion.
For more in depth analysis, you can also see a visual summary of each variable.
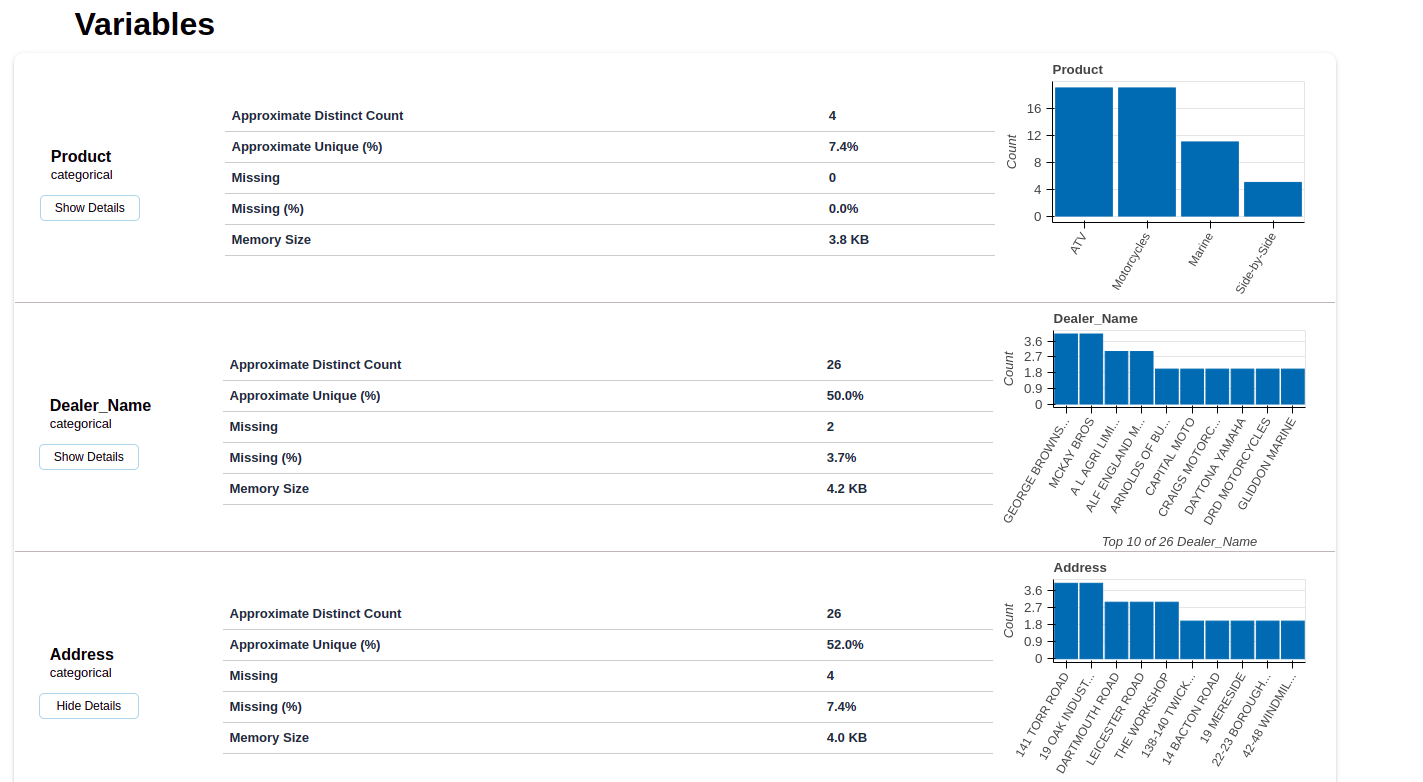
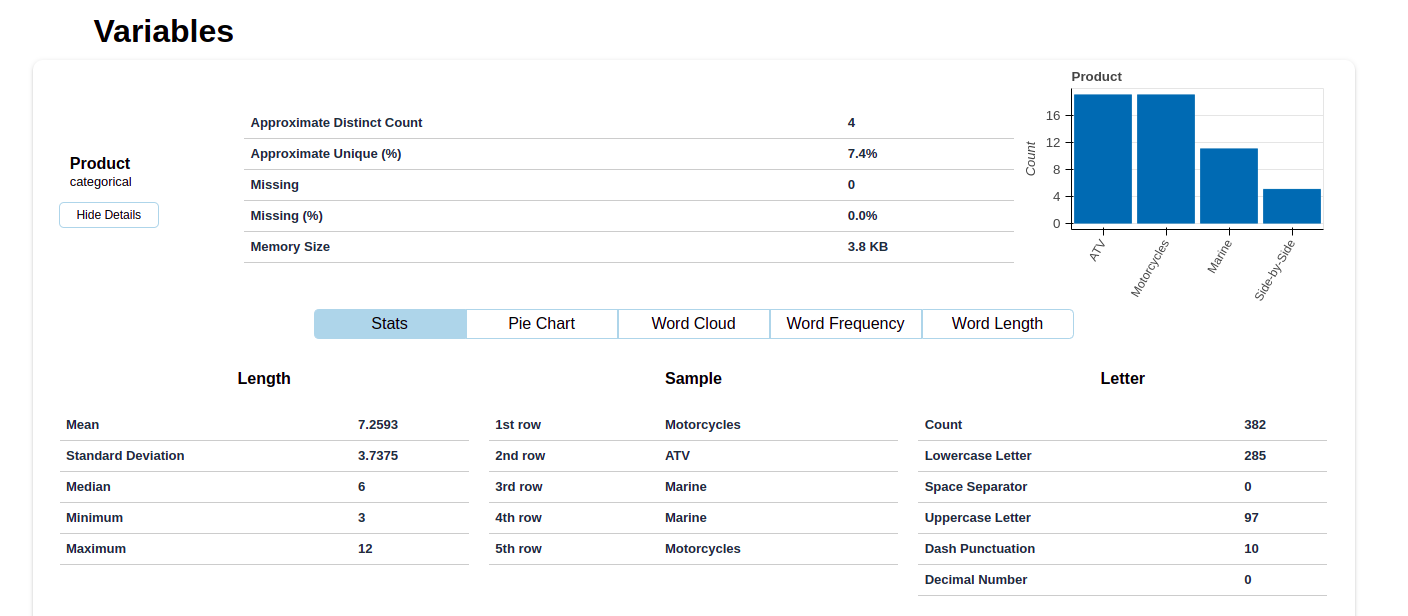
A detailed section for each variable category allows you to view the overall statistics of that particular category.
The QA team located several discrepancies in the dataset. Then, it’s sent to the Delivery team for reinspection. The following bar graph gives them a visual representation of missing values for each variable.
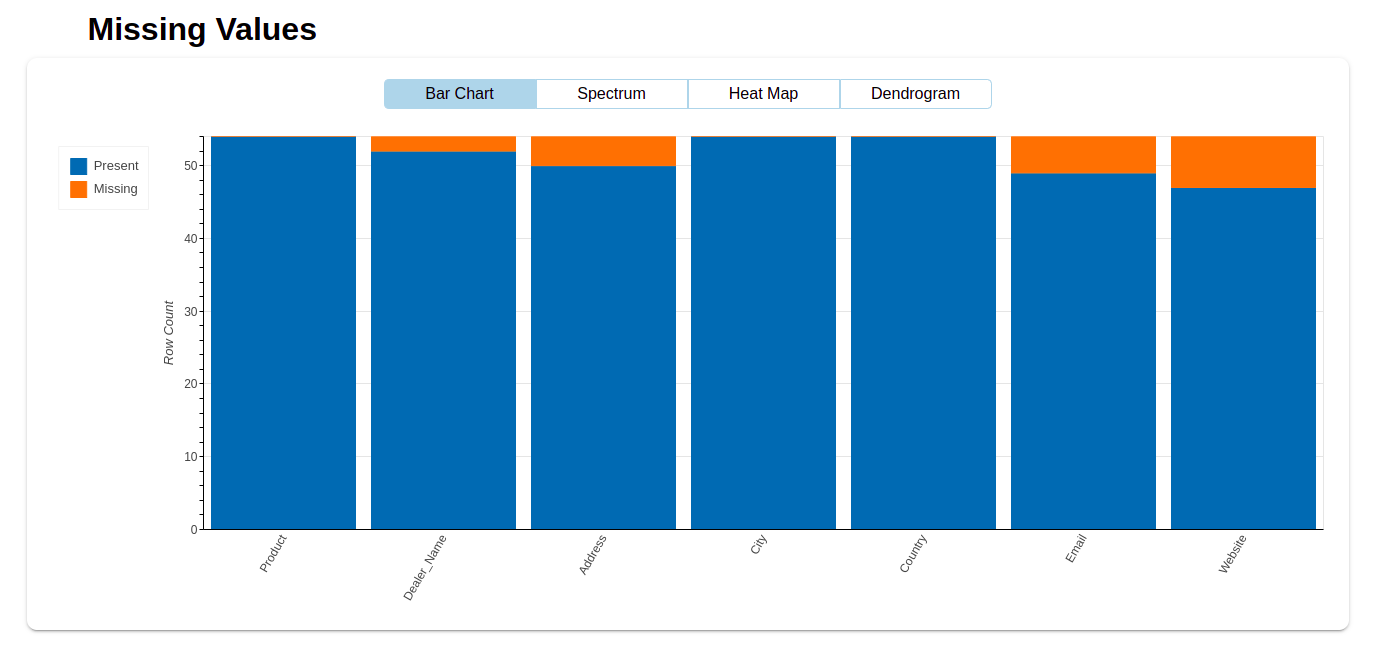
Insights gained: Compared to the issues of Case I, we discovered more problems in the dataset after the first round of extraction. There were a lot of missing values like dealer name, email, and website details.
Phase III: Data refinement
With a clear roadmap laid before the Delivery team, there was nothing left to do but make the necessary changes. Then, the Delivery team sent another dataset to the QA team after the second round of data extraction. Thankfully, there were no errors this time. The following report fully substantiated the accuracy of our data.
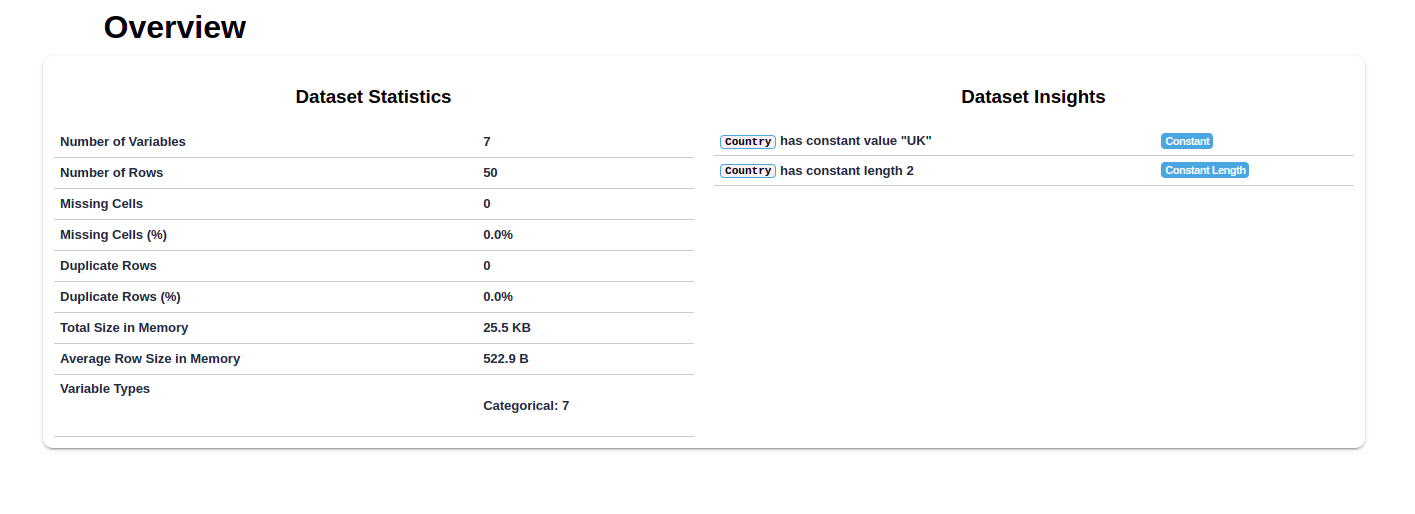
Phase IV: Data Delivery
The Customer Success team now sends the data to the client. Finally, it can be deployed immediately.
To conclude
Most of our clients have one thing in common. Their data requirements are all unique. Naturally, we employ different QA checks to guarantee the integrity of their data.
We perform manual and automated QA processes to ensure the quality of your data. Furthermore, our robust data platform supports multiple data formats and delivery destinations. Seamless integration with popular platforms like Amazon S3, Google Cloud, Azure, etc., is a non-issue.
While data refinement demands a lot of manual work, as long as it delivers high-quality data, nonetheless, we do it for you.
FAQs
What is market expansion via data refinement?
Market expansion via data refinement involves improving the quality of data to make informed decisions that help businesses enter and succeed in new markets.
How does data refinement support market expansion?
By refining customer, market, and competitor data, businesses can better understand the landscape of new regions, tailor strategies, and reduce risks during expansion.
What types of data are refined in the process?
Data related to market size, customer preferences, competitor analysis, and product performance are all key data types that businesses refine for successful expansion.
Why is data refinement important?
Data refinement ensures that businesses work with accurate, actionable insights, reducing the risks of poor decision-making and improving the chances of market success.
How does Grepsr help with data refinement?
Grepsr helps businesses automate data collection, clean and normalize data, and create custom data pipelines tailored to market expansion efforts.
Shaping a prosperous future with data-driven decisions

Web Scraping for Competitive Market Insights: Powering $3 Billion in EBITDA Through Data-Driven Pricing
Setting prices for products is similar to adjusting the sails on a boat. If you don’t read the wind properly, you’ll either be stuck in place or heading in the wrong direction. Data is the wind that helps you steer a steady course. In an economy where every dollar counts, businesses can’t afford to guess […]

Web Scraping for Drug Safety Monitoring: Real-Time Data Extraction for Tracking Side Effects
Quick Summary: Web scraping and public web data extraction can help pharmaceutical companies detect drug side effects faster by monitoring publicly available discussions and medical publications. This case study explains how a pharma company used web scraping to collect real-time signals about adverse drug reactions and turn scattered public information into structured safety data. Imagine […]

Analyzing Celebrity Impact on Consumer Behavior through Social Media Data: Taylor’s Version
This case study takes a deep dive into the powerful influence of global pop star –Taylor Swift. By extracting social media data using carefully selected keywords and hashtags, we analyze patterns and trends that reflect the powerful gravitational pull of her influence on consumers. Continue reading for jaw-dropping insights. The Power of Celebrity Influence Celebrities […]

Boosting Efficiency and Accuracy: The Power of AI Data Validation for E-commerce Growth
In e-commerce, one wrong product detail can cost you a sale, or worse, a customer’s trust. As businesses scale, ensuring the accuracy and consistency of their data becomes an increasingly complex challenge. Similarly, for a growing electronics retailer, managing an expanding catalog of products with manual data validation was a recipe for errors, delays, and […]
How Proactive Communication Scaled a Product Data Extraction Project for a Dental Supplier
The dental products retail industry is thriving in the online business sector. As more dental professionals turn to digital platforms for sourcing products, those who can harness the power of big data are gaining a competitive edge. One of the most effective ways to leverage this data is through product data extraction—the process of automatically […]
How a Leading Consumer Electronics Company Leveraged Automated Customer Review Extraction
Customer reviews serve as the backbone of product development and consumer insights. For one leading consumer electronics brand, these reviews were essential for fueling machine learning models that perform sentiment analysis and inform key business decisions. However, the frequent removal of reviews by platforms due to policy violations creates significant challenges, leaving gaps in the […]

Powering a Booking Intelligence System with Real-Time Hotel Data Extraction
In the travel industry, booking data is the pulse that reveals how markets move. It captures the patterns of demand, competition, and consumer intent like who’s booking, where, when, and at what price. This information fuels dynamic pricing, helps forecast occupancy, and enables travel platforms and hotels to anticipate market shifts rather than react to […]

How ESG Advisory Firms Can Leverage Automated Article Extraction for Smarter Insights
Government websites and official press releases are goldmines for ESG (Environmental, Social, Governance) intelligence. Every update – whether it’s a new regulation, policy amendment, or court directive can shape how ESG advisory firms advise their clients. Yet, these updates are scattered across hundreds of government portals, each with its own format, language, and publishing schedule. […]

Seamless Vehicle Data Extraction for a Leading Automotive Intelligence Provider
In the automotive industry, having access to comprehensive, real-time vehicle information is essential for making informed decisions. However, gathering this data from online sources comes with many challenges, such as security barriers, IP restrictions, and complex firewall configurations. These can significantly disrupt the flow of critical data needed to support key business operations. In this […]

High-Coverage POI Data Extraction For Powering FMCG Market Strategy
Finding the right retail locations is a lot like navigating a city without street signs – you might eventually reach your destination, but not without wasted time, missed turns, and lost opportunities. Points of Interest (POI) data acts as those street signs, offering clear visibility into where consumers shop, dine, and gather. For global brands […]

POI Data Enrichment for a Leading Hospitality Management Company
Data is valuable, but enriched data is priceless. Data enrichment is the process of adding value and further information to an existing dataset to improve its quality, accuracy, and completeness. It involves taking raw, incomplete data and enhancing it with additional and meaningful information from external sources. It turns a basic dataset into something richer, […]

Location Intelligence in Retail: Real Use Cases From Grocery Stores
Do you know what separates successful retailers from the ones that are closing down? One key factor is using location intelligence in retail to make informed decisions. Modern retailers scrape the internet to find out competitor store hours, demographic shifts, and foot traffic patterns to find impactful location strategies. And the numbers back it up. […]

Shaping Organizational Culture with Glassdoor Data
Glassdoor Data offers a detailed look into organizational culture by analyzing employee reviews and ratings. This data provides insights into company dynamics, regional trends, and the impact of major events, helping businesses improve employee satisfaction and cultural alignment. Netflix’s culture deck, crafted by Reed Hastings, champions employee autonomy and creativity, even offering unlimited vacations as […]

How Web Scraping Saved a Vehicle Data Platform
How Grepsr rescued a vehicle data platform from a major OEM block—restoring 100% uptime, 99.9% data accuracy, and real-time API performance for VIN checks and insurance quotes.

Mapping LA Wildfire Impact with POI Data
POI data extraction and reverse geocoding transformed wildfire impact maps into precise addresses, enabling targeted disaster relief.

How a Real Estate Agency Gained Competitive Intelligence with Real-Time High-Quality Datasets
Gathering structured real estate data from various government sites and public records at scale poses significant challenges.

What Is Shipping Data & Why It’s Critical for Logistics Performance
Before the pandemic, the global supply chain relied on predictable inventory flows. There was high schedule reliability, which meant the carriers usually followed the same schedules. This ensured the arrival of inventory in time, replenishment of stores, and constant operation of the factories.

Unraveling Job Market Dynamics: Leveraging Data Analytics for Competitive Edge
The notion of hiring the “right” candidate needs clarification of what’s “right” for your organization. Starting from the alignment of values, motivation, ambition, and technical skills required for the position.

Introduction to Web Scraping & RPA
Web scraping automatically extracts structured data like prices, product details, or social media metrics from websites. Robotic Process Automation (RPA) focuses on automating routine and repetitive tasks like data entry, report generation, or file management.

Car Rental Data Unwrapped: Merry Miles and the Christmas Story in the UK
Delve into the festive drive as we analyze 50K+ car rental records from ‘Sixt – Rent a Car’ during December 2023. From the holiday surges on Christmas Eve to discovering budget-friendly gems like the Kia Picanto, come with us as we decode the Merry Miles of Christmas car rentals in the UK.

NYC POI Data Dynamics: Decoding Impermanence
Geographical locations or POIs are not entities that last for posterity. We collected NYC POI data to decode the various dynamics that may help executives make informed decisions within the backdrop of impermanence.

Revving Up for E-commerce Success in Q4: Leverage Web Scraping
Inflationary pressures, rising prices, and the looming possibility of an impending recession have dealt an unwarranted blow to e-commerce sales over the last three quarters.

Harnessing POI Insights: The Web Scraping Advantage
Points of Interest (POIs) are more than just points on a map. They are filled to the brim with actionable data like addresses, names, contact details, and working hours. POI data also includes images, which add a visual component to the data. With web scraping, you can get the advantage you need to harness POI insights.

Top Six E-commerce Datasets: Web Scraping Use Cases
The irreversible rise of e-commerce has been a similar phenomenon around the world. In 1998, the entirety of the e-commerce market stood at just $5 billion.

Analyzing US Job Postings Data to Understand Job Market & Economy
The US economy was forecast to spiral into a recession in 2023. Yet, despite fears, if current job listings and hiring trends are to be believed, the current economic reality appears to be quite different. The robust nature of the current US job market is proving to be one of the main drivers of the country’s strong economy.