Ever since our founding, Grepsr has strived to become the go-to solution for the highest quality service in the data extraction business. At Grepsr, quality is ensured by continuous monitoring of data through a robust QA infrastructure for accuracy and reliability. In addition to the highly responsive and easy-to-communicate customer service, we pride ourselves in being able to offer the most reliable and quality data, at scale and on time, every single time.
QA procedures in place
Before any project is approved, our customer liaison team understands each request’s details before handing it over to the data engineers. The data team then sets up the crawlers based on these requirements, with the first phase of QA done simultaneously to minimize any potential errors as much as possible.
The Grepsr QA team steps in once they set up the crawlers and begin collecting the data. We have categorized our QA protocols into two types based on the nature of the project requirement — generic and specific.

Generic cases
These are the QA processes that all datasets are subjected to before delivery.
- Firstly, the QA team checks if all client requirements are fulfilled in terms of the website(s), data fields and frequencies (in case of recurring crawl runs).
- The QA team then checks whether the dataset contains any duplicate rows and dedupes it.
- Next, we assess the data for any missing values. The QA team determines whether this is an issue on our end or by nature of the data source.
- The team also checks whether each the values in each data field matches the expected data type, like numeric (integer, float, etc.), currency, email and so on.
- Another important criteria in our QA checklist is to see whether data fields and corresponding values are being properly mapped. In other words, we check if values are being populated in the correct columns.
Specific cases (per-project checks)
Depending on our clients’ requests for specific projects, we conduct various custom data quality assessments in addition to the generic checks mentioned above.
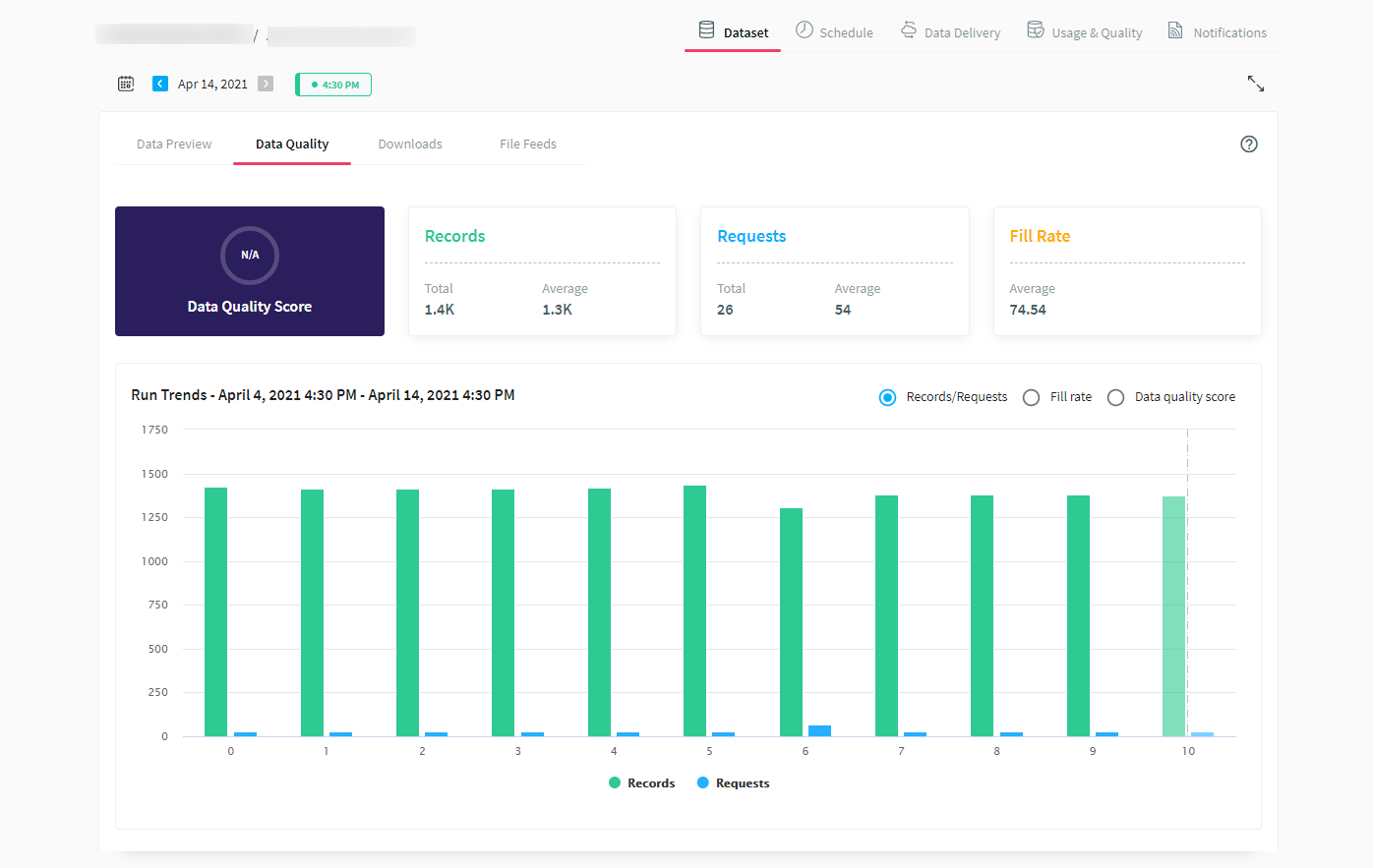
Records & requests counts
A record is each row of data in a datasheet. Records count is often the first metric that anyone would look at on our platform to understand the health of their dataset. Similarly, in terms of data extraction, requests are the instructions that a crawler sends the source website to elicit a response — i.e. a record, in our case.
Internally, we look at the record and request counts for each 24-hour period and compare them with the average counts from the last 7 days. The QA team and engineers receive an alert if the count is below a certain percentage threshold of the usual counts.
Pattern verification
Some data field values are expected in certain formats — specific characters, character lengths, prefixes, suffixes, etc. Our QA team uses RegEx (regular expressions) to determine the values’ pattern, filter the anomalies and suggest fixes, if required.
Examples:
- Amazon product ASINs that are unique blocks of 10 letters and/or numbers.
- Dates in
DD-MM-YYYYorMM-DD-YYYYformats.
Addresses
You can present addresses in various different formats — from single-line to multi-lines, or as in the case of US addresses, with state names abbreviated or in full. Depending on what our clients’ requirements are, and how they’re shown on our data source (website), we take the necessary courses of action.
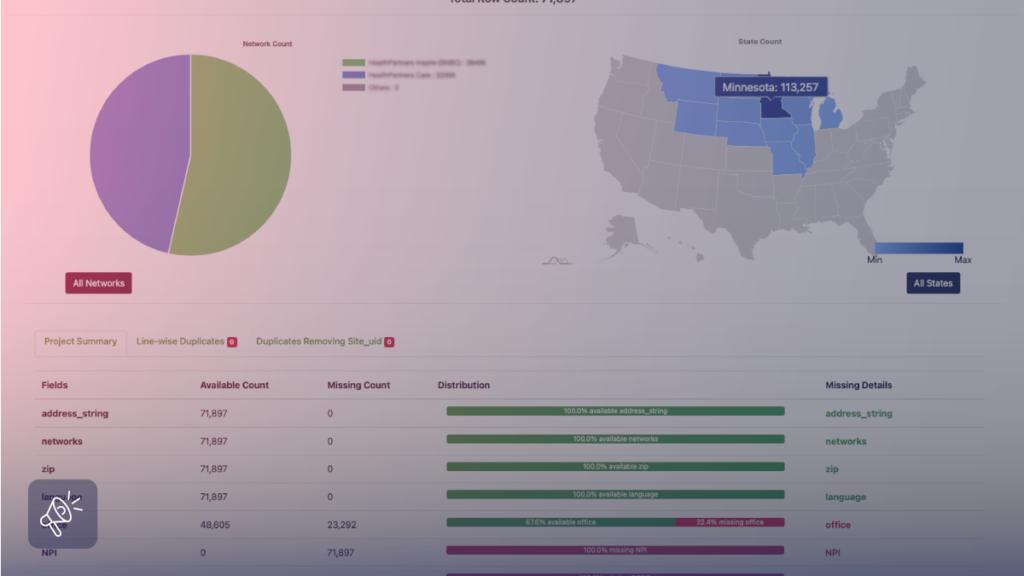
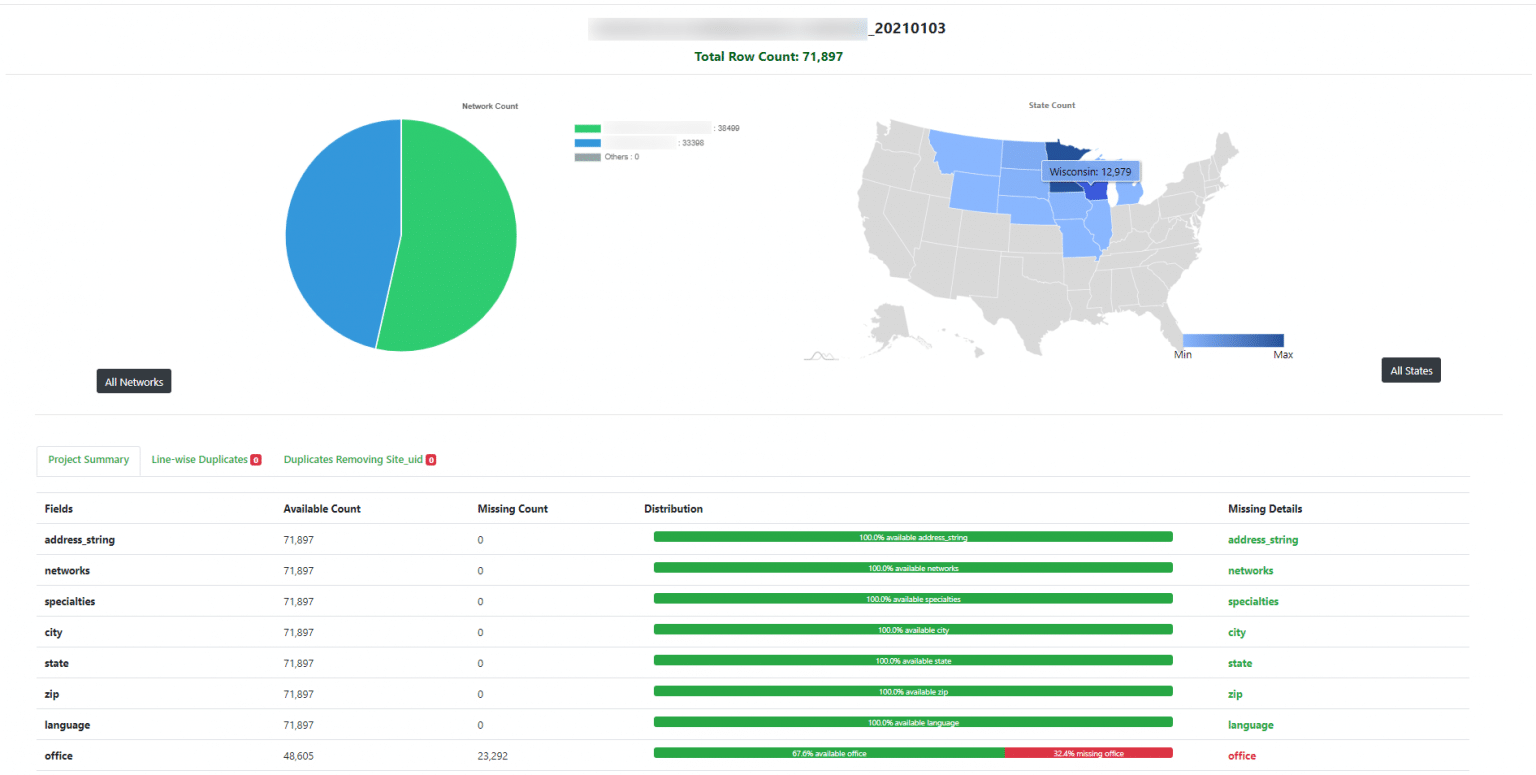
Location-specific data
For datasets that contain location-specific information, such as store locations across a country, we have a visualization tool in place where we display state-wise numbers. This helps us understand the completeness of the data, record counts for each data field and identify duplicates.
Images/Files
The QA team checks whether the images and other files we extract are as per the request. Either they download them as URLs or compress them into zip files.
In addition, if a customer requests the files to have their names in a certain format, then we check the filenames as well.
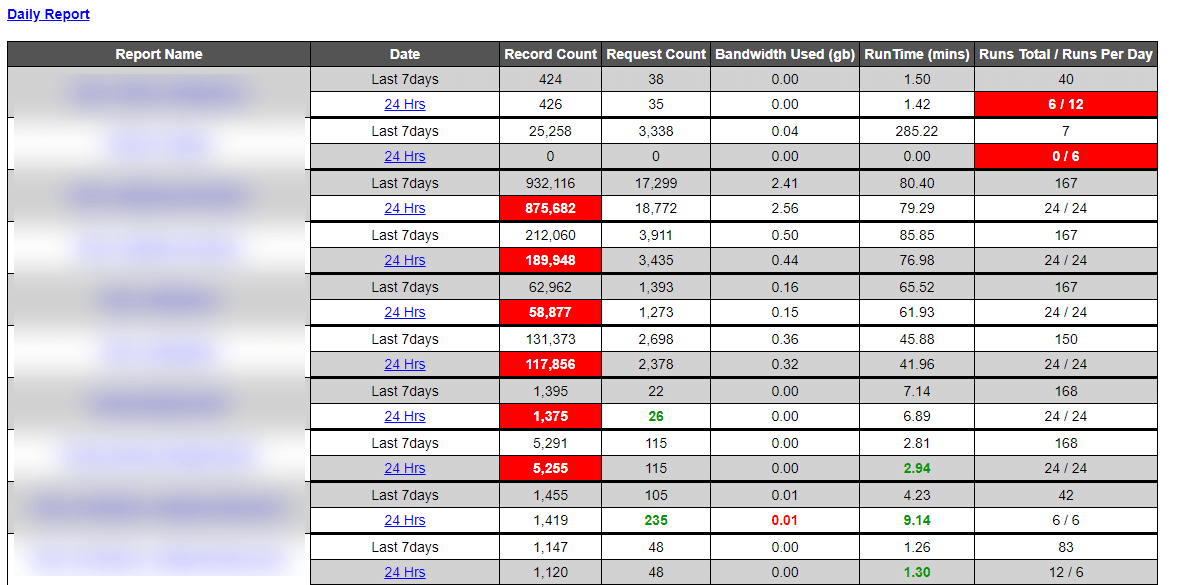
Crawler runtimes
Runtime refers to the total duration of any crawl run from start to finish.
We compare the time taken for the latest crawl to complete with the average runtimes over the past 24-hour period or week. An alert goes to the QA team if the latest runtime is abnormally longer or shorter.
Scheduled runs
The Scheduler is one of the most useful features within the Grepsr app. As such, it is important that the QA team regularly checks whether scheduled crawlers are running as expected and as many times a day as scheduled.
In addition to the regular manual checks on projects with recurring crawl runs, there is also an automatic notification mechanism in place. It alerts the team via email or text if and when a scheduled run skips.
Probable causes
While we endeavor to always empower our customers with the highest quality and reliable data, there are certain factors beyond our control that occasionally prevent our crawlers from collecting data as expected. The most common reasons that we know of are as follows:
- The source website may be temporarily down.
- The website may have changed its layout and structure since the last successful run.
- The website may be using an anti-crawling technology that blocks our crawlers from accessing it. Once we diagnose this issue, we use
- Some websites restrict access to certain countries and regions, or display different content based on the location where the site is being accessed from. In order to access these geo-restricted content, we use proxies to fetch the data that matches our clients’ location.
- Occasionally, there are duplicates and some information missing in the website itself.
- Since our web crawlers are build for specific websites and layouts, any real-time change on their end is hard to keep track of. This might cause a crawl run to stop abruptly, resulting in a “failed” run.
- Sometimes, the data that we see on a website is different when accessed via APIs.
Related read:

Summary
Thus, this is how we ensure the highest quality data through top-notch QA infrastructure with team expertise at Grepsr.
Despite the various obstacles websites place on our scrapers during extraction, the expert team here at Grepsr is able to collect and deliver on our client’s needs efficiently and reliably. Each dataset we extract is subject to rigorous quality checks and processes before we consider it ready for delivery.
Our mission is to always empower our customers with the highest quality reliable data. We want our data, expertise and technology to be the stellar foundation which you can build upon for continued success.