

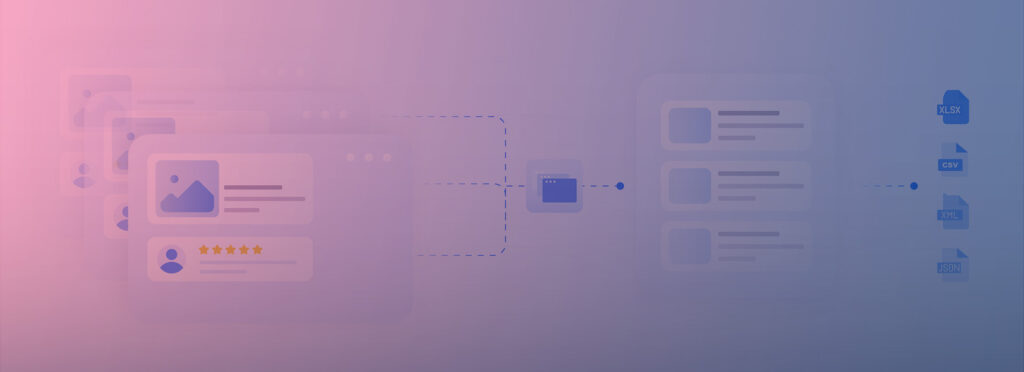
Screen scraping should be easy. Often, however, it’s not. If you’ve ever used a data extraction software and then spent an hour learning/configuring XPaths and RegEx, you know how annoying web scraping can get.
Even if you do manage to pull the data, it takes way more time to structure it than to make the screen scraper work.
It’s the ad-hoc communications and inherently only semi-structured information on the web plus the legalities around it that continues to make web scraping, say… “a less enjoyable experience.”
Stats for Screen Scraping
According to a sample of 20,000 new projects created in Grepsr, as many as 45% were not successfully completed.
The problem wasn’t that people didn’t understand Grepsr’s product or how it worked. It was just that people wanted to get a hold of the data first, and then think about how to structure it or make it usable. This resulted in delays, increased cost, data migration errors, and other issues.
What if we invert the problem, and rather ask: What were the characteristics of the 55% projects which were successfully completed, and what process did they follow?
By now you can probably guess what we’re trying to get at.
Project scoping. Of the 55% projects that were completed, almost all of them had clearly defined requirements — both inputs and outputs.
The benefit of scoping a project thoroughly beforehand is that the end result is often much better. Because the expectations — of both you and the service provider — are established clearly and early on, before any work is done.
Typically, a text document, often called a project brief, is one of the core pieces of a successful project. Having one from the start is probably the single-most important thing you can do to ensure your web scraping project starts and runs smoothly.
Key questions
With that backdrop, let’s get to the crux of this piece.
Here are four important questions to ask when scoping your next web scraping project:
- What is the business use-case behind the project? Do you have clearly defined requirements?
- Have you identified key data sources and the target data fields required?
- Is this a continuous process, or a one-off? Who will run the data movement, and how? Can it be automated?
- Are there requirements for cleansing data, running rules against the source data or against the data once loaded into the target system?
Let’s look at each one in detail.

What is the business use-case behind the project? Do you have clearly defined requirements?
We’ve seen companies realize the most significant benefits from web data projects when they start with business challenges and goals, and quickly narrow them down to clearly defined requirements.
At Grepsr, we create these types of business use cases:
- Faster path to ROI with both tech and services
- Ability to prove the value over home-grown systems
- Scalability to more data sources and use cases
The goal may be clear, but how will you know once you’ve achieved it? It’s important to define what success for your web data project looks like before proceeding.
This is where clearly defining the requirements comes in.
Imagine if it was not just about obtaining any new data from data source(s). But the data had to match certain criteria — for example whether or not it is already in your system, aggregate the necessary fields and finally, organize the data to seamlessly enter your system.
One of our clients had similar requirements. They had figured early on that they needed a data extraction vendor who could automate every step of the process from the moment new data is captured to when it enters their system (and everything in between).
From a crawling perspective, it looked like a lot of web scraping vendors offered a similar service to crawl a website, and it didn’t feel necessarily that any one particular vendor could do something that other ones couldn’t.
John MacDonald
With clearly defined requirements, our client understood that they would require an out-of-the-box functionality than just the features that were offered in the market.
You can read more on their story here.
Flexible pricing models that suit your enterprise needs
Have you identified key data sources and target data fields required?
The first phase of a web data extraction project is to identify and explore the source systems. The most appropriate route for identification is to group data based on the target data fields.
For a lead-gen screen scraping project, the target system is your CRM. Grouping data by company, contacts, roles and other crucial information required that can be imported into your CRM is your target data fields.
In this stage, it is critical to identify which data is required, and where it is, as well as what data is redundant and not required.
Conversely, if the initially identified sources do not contain all of the data required for the target data fields, a gap is identified. In this case, you may have to consolidate data from multiple sources to create a record with the correct set of data to fulfill the requirements of the target system.
Using multiple data sources allows you to add another element of data validation and a level of confidence in your data.
At the end of this phase, you have identified search terms, specific URLs and pages within those source systems and document those. You will also have identified any gaps in the data and, if possible, included extra sources to compensate.
Optimally, you will have broken down the data into categories that enable you to work on manageable and possible parallel tasks.
While you do all of that, keep in mind: You may not need everything.
Often times, the first instinct is to collect massive amounts of data at high frequencies, when a well-constructed sample set of data may be all you need to obtain actionable insight.
Is this a continuous process, or a one-off? Who will run the data movement, and how? Can it be automated?
The choice around continuous screen scraping or a one-off data scraping is dependent on the use-case. For example, a one-off scrape could be for research or academic use — get the data, visualize it or prepare reports, done!
On the other hand, the use case for an on-going scrape could be to automate and fuel parts of business process workflows or apps. Think of price monitoring projects, where it’s vital to get live data at regular intervals for analysis and comparison.
Ideally, a demo or a walk-through of your service provider platform is a good place to begin with. What you should be looking for is their ability to automate on-going crawls and streamline the data ingestion process.
At Grepsr, we offer a scheduling feature that allows to queue up your crawls ahead of time in the same way you would schedule on-going meetings in your Google calendar.
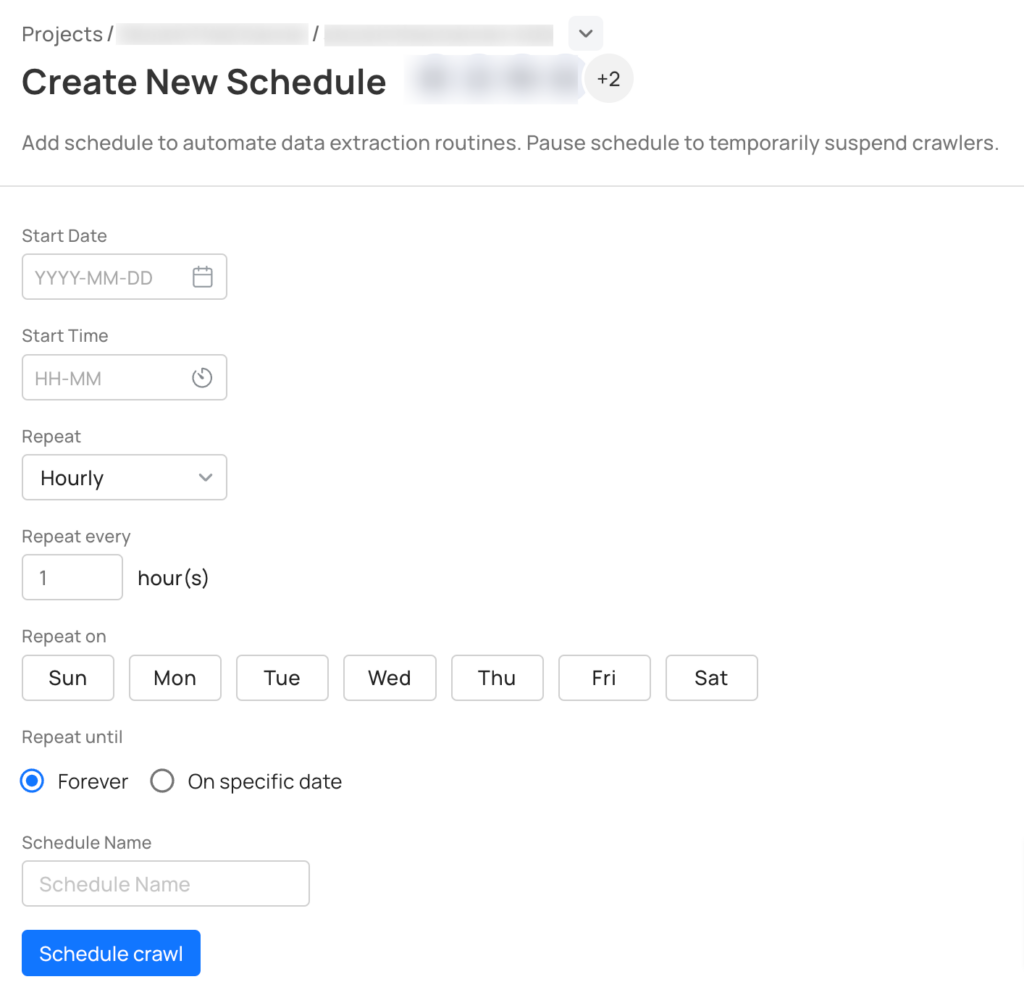
And as soon as the complete data is fetched, our system sends a notification to download the files. Alternatively, you can easily bring the data in your system in near real-time using our powerful APIs. Furthermore, you can use our pre-built data connectors using your everyday business tools.
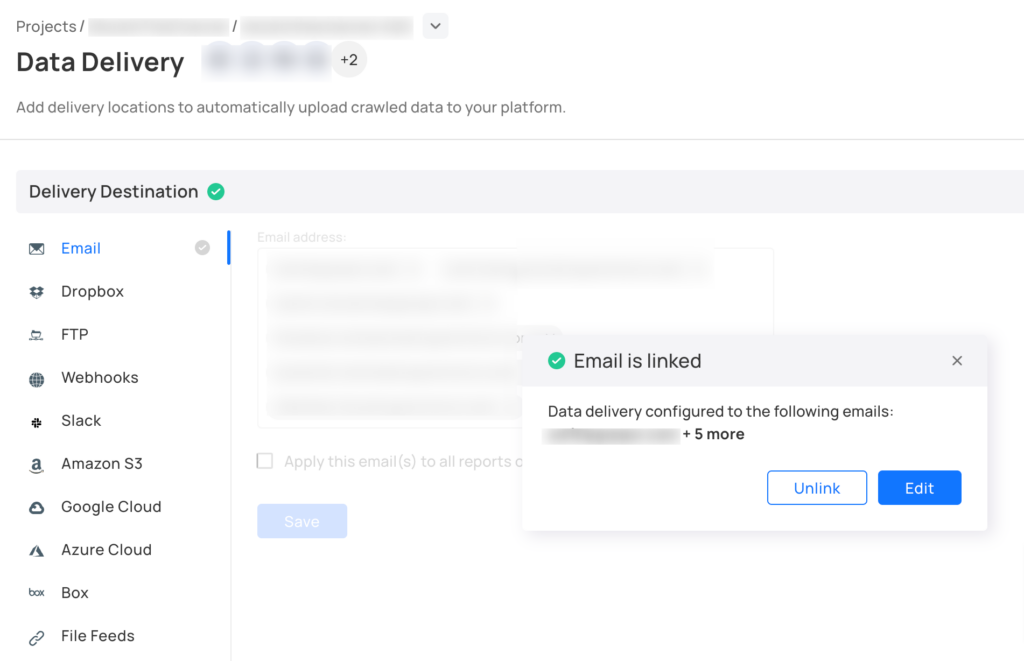
Are there requirements for cleansing data, running rules against the source data or against the data once loaded into the target?
Most screen scraping projects fail or get delayed because the data structure or output format was given an afterthought. Granted, because we want to first get the data in hand and then think about making it usable.
We did a project a couple of months ago, wherein the client forgot to mention that the ‘addresses’ returned should match USPS address standardization otherwise their system simply wouldn’t import any data. We eventually had to use a USPS address verification API causing changes in the project budget and subsequent delays.
At this stage, it is imperative for you and your team to ask questions like: Where will the data end up? In a spreadsheet, a database, or an analytics application? Does it require data cleansing?
Try to lock down a data schema up front. Don’t just focus on getting your hands on the data without thinking through the structure and the format that needs to be in place for data integrity and ingestion.
Conclusion
Often when you’re first getting started with screen scraping, there’s a rush to get data into the system so you can start using it. Eagerness to make use of the data is great, but I hope this post has given you enough reasons to take a moment to consider all the necessary factors and the importance of scoping your scraping project early on.
















































































































































