Quick Answer: Web scraping with PHP is the process of using PHP scripts to extract data from websites by sending HTTP requests, parsing HTML responses, and storing structured information.
This tutorial demonstrates how to scrape IMDB’s top 250 movies using Guzzle (for HTTP requests) and PHP HTML Parser (for DOM manipulation), resulting in a clean CSV file with movie details.
By the end of this article, you will have sound knowledge to perform web scraping with PHP and understand the limitation of large-scale data acquisition and what your options are when you have such requirements.
What is web scraping?
We surf the web every day, looking for information we need for an assignment or simply to validate certain hunches. Sometimes, you may need to copy some of that data or content from a website and save it in a folder for use later. If you’ve done that, congrats, you have essentially done web scraping. Welcome to the club!
But, when you need massive amounts of data, your typical copy-paste method will prove to be tedious. Data as a commodity only makes sense when you extract it at scale within a context.
Web scraping, or data extraction then, is the process of collecting data from multiple sources on the web and storing it in a legible format.
Data is something of a currency in this day and age, and companies are increasingly looking to be data-driven.
But without a proper framework and data management protocols overarching the entire data lifecycle, the currency of the twenty-first century is as good as an expired coupon. We’ve always maintained that bad data is no better than no data. Read about the five primary characteristics of high-quality data here:

The main scope of this article is to introduce you to the world of data extraction using one of the most popular server-side scripting languages for websites -PHP.
We will use a simple PHP script to scrape IMDB’s top 250 movies and present it in a readable CSV file. Considering PHP is one of the most dreaded programming languages, you might want to take a close look at this one. The difficulty level of web scraping with PHP is just about perspective.
PHP fundamentals for web scraping
The technology that establishes a connection between your web browser and the many websites throughout the internet is complex and convoluted.
Roughly 40% of the web is fueled by PHP, which is reputed to be historically messy, in terms of both logical and syntactical grounds.
PHP is an object-oriented programming language. It supports all the important properties of Object Oriented Programming like abstraction and inheritance which is best suited for long-term scraping purposes.
Although data extraction is relatively easier with other programming languages, most websites today have more than a hint of PHP, making it convenient to write a crawler faster and integrate them with websites.
Before we go any further, let’s briefly outline the content of this article:
- Prerequisites
- Definitions
- Setup
- Creating the scraper
- Creating the CSV
- Final words
Prerequisites: For data extraction using PHP
Firstly we will need to define what we will be doing and what we will be using for this scraping tutorial. Our general workflow will consist of setting up a project directory and installing necessary tools required for data extraction.
Most of these are platform agnostic and can be performed in any operating system of your choice.
Then we will go through each step of writing the scraper in PHP using the mentioned libraries and explaining what each line does.
Finally, we will go through the limitations of crawling and what to do in case of large-scale crawling.
The article will address mistakes one might unknowingly make. We will also suggest a more appropriate solution.
Definitions to get you started with PHP web scraping
Before we get into the thick of the action, let’s cover some basic terms you will come across when reading this article. All the technical terms will be defined here for ease of demonstration.
1. Package manager
A package manager helps you install essential packages through a centralized distribution storage. It is basically a software repository that provides a standard format for managing dependencies of PHP software and libraries.
Though not limited to managing PHP libraries, package managers can also manage all the software installed in our computers like an app store but more code specific.
Some examples of package managers are: Composer (for PHP), npm (for JavaScript), apt (for Ubuntu derivative linux), brew (for MacOS), winget (for Windows), etc.
2. Developer console
It’s a part of the web browser that contains various tools for web developers. It is also one of the most used areas of the browser if we are to start scraping data from websites.
You can use the console to determine the tasks a web browser is performing when interacting with a website under observation. Although there are many sections to pick from, we will be using only Elements, Network, and Applications sections for the purpose of this article.
3. HTML tags
Tags are specific instructions written in plain text enclosed by triangular brackets (greater than/less than sign).
Example:
<html> … </html>
They are used to give instructions to the web browser on how to present a web page in a user-friendly manner.
4. Document Object Model (DOM)
The DOM consists of the logical structure of documents and the way they are accessed and manipulated.
Simply put, DOM are models generated from an HTML response, which can be referenced through simple queries without resorting to complex processing.
A good example would be an interactive book where each complex word is linked to its meaning as soon as one clicks on the word.
5. Guzzle/guzzlehttp
It is an external package used by our scraper to send requests to and from the web server, similar to a web browser. This mechanism is often referred to as the HTTP handshake where our code sends a request (termed GET request) to the IMDB servers.
In response, the server sends us a response body, which consists of a set of instructions with the proper response body, cookies (sometimes), and other commands that run inside the web browser.
Since our code will be running in a sequential form (one process at a time), we will not handle other instructions provided by the IMDB servers. We will focus only on the response text. You can find the documentation for this package here.
6. Paquette/php-html-parser
Like guzzle, this is also an external package used to convert raw response from the web page received by guzzle client into a proper DOM.
By converting into a DOM, we can easily reference the parts of the document received and access individual parts of the document which we are trying to scrape. The source code and documentation for this package can be found here.
7. Base URL
Base URLs are the URLs of websites that point to the root of the web server.
You can get a better understanding of the base URL by reviewing how a folder structure works in the computer system.
Take a folder called Documents in the computer. Now this is what the web server exposes to the internet. It can be accessed by any user requesting a response from the web page.
We can open any new folder in the documents folder. Navigating to the new folder is simply a matter of traversing the Documents/newfolder/path.
Similar to how web pages are maintained based on hierarchy, the base urls are the root of the entire web page’s web document, and any new pages are simply “folders” inside that base URL folder.
8. Headers
Headers are instructions for the web servers to follow rather than our client system. They provide a simple collection of predefined definitions, which allow web servers to accurately decode client responses.
A basic example would be a download windows page, say in Microsoft.com.
With the user-agent header, the web server can easily deduce that the request sent to their server comes from a windows PC. Hence, it needs to send information that is relevant to the platform. The same logic applies for language differences between web pages.
9. CSS selectors
CSS Selectors are simply a collection of text syntax that can pinpoint a document in a DOM without using much processing resources.
It is similar to the table of contents section in a physical book. By looking at the table of content, the reader can skim to the sections he is interested in.
But in contrast to the table of contents, CSS selectors can accept more filters and are able to use that to reduce noise (unimportant data) from the actual data we need to search in the DOM.
They are mostly used in web designing but are mighty helpful in web scraping.
Project Setup for data extraction with PHP
After this point, the article will assume that you have a basic understanding of Object Oriented Programming and PHP. You should have skimmed through the definition presented in the above section.
It will provide you with the basic knowledge necessary to continue along with the tutorial in the following sections. We will now delve into the setup of the crawler.
Composer
Initially, we will install a package manager [1] called composer through the package manager for your systems. For Linux variants, it is simply sudo apt install composer (Ubuntu) or with any package managers in our computer. For more information about the steps to install composer, go to the link here.
Visual Studio Code (or any text editor; even notepad will do)
This is for writing the actual scraper. Visual Studio Code has multiple extensions to help you with the development of programs in different programming languages.
However, it’s not the only one that can be used to follow this tutorial. Any text editor, even basic ones, can be followed to write a scraper.
We highly recommend IDE due to its automatic syntax highlighting and other basic features. It can be installed through the stores of individual platforms.
For Linux, installing through the package managers or Snap or Flatpaks is much easier. For Windows and MacOS installation, visit here.
Now that we have all that we need to write the scraper to extract the details of the top-rated 250 movies in IMDB, we can move on to writing the actual script.
Creating the web scraper
We want to scrape IMDB’s top 250 rated movies to date through this link for the following details:
- Rank
- Title
- Director
- Leads
- URL
- Image URL
- Rating
- Number of reviews
- Release year
But there’s a slight hiccup. Not all the information we need is displayed on the website.
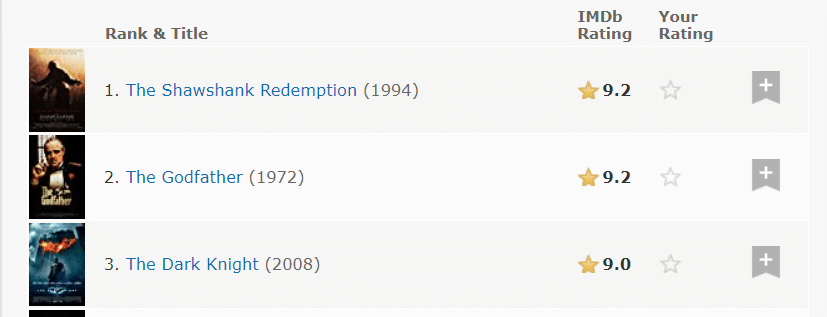
Only Rank, Title, Year, Rating and Image are directly visible.
The initial step of web scraping is to determine what the website is hiding from us.
You could take websites as walls of text sent by the web server. When read by the web browser, the website can display different structures depending upon the instructions provided on the walls of text sent by the web server.
Every hover in each element of the website is simply an instruction to the web browser to follow the text response received from the server and act accordingly.
As a scraper our job is to manipulate this received text and extract all the information that the website wants to hide from us, unless we click on the desired option.
Step 1:
Open the developer tools [2] in the browser to check what the website has hidden from us. To open the developer console, press F12 on the keyboard or Ctrl+Shift+I (Command+Shift+I for Mac). Once you open the developer console you will be greeted with the following screen.
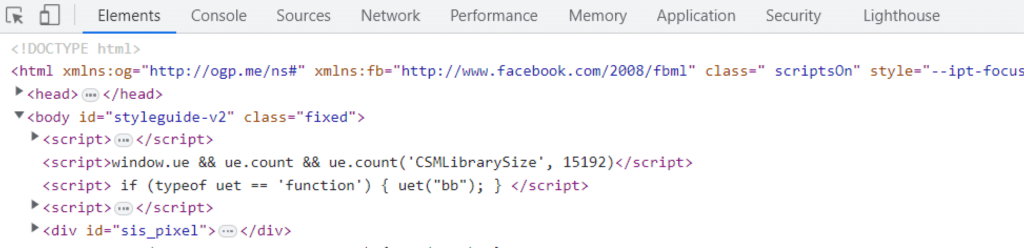
This is basically what the current website has sent over to our system to display the website on the web browser’s canvas.
Step 2:
Now clicking on the Inspect button (Top left arrow key) will start the inspect mode for the website.
This mode is a developer mode that is used to interact with the web page as if we are trying to source the interactive element in the website to its actual instruction source on the walls of text (called response) sent over by the web server of IMDB.
Now we simply click one of the movie names and in the console, we can see what the actual text response was.
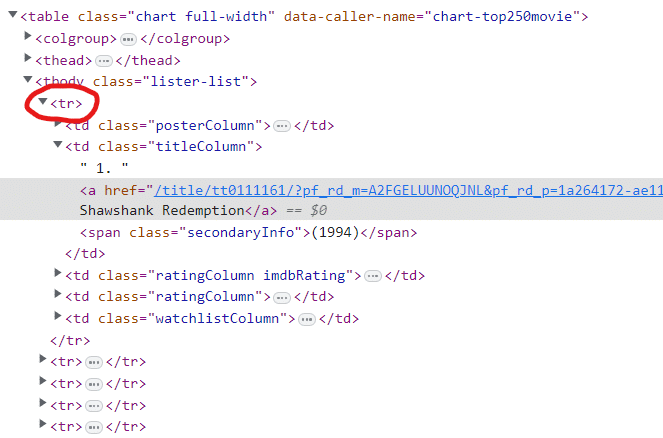
In the image above, we see there are 250 tr tags [3]. Tags in HTML are simply instructions designed for web pages to display the information in a more palatable format.
This piece of information will be useful later.
For now let’s focus on the first tr member in the response. Maximizing all the td elements, we can see more information on each movie listing than what was previously visible on the webpage.
With this information alone, we can now use the page response in our PHP code to scrape all this random information in the page into a proper tabular format, so we can generate actionable data from it.
Armed with this knowledge, we can now move on to do some real coding.
Step 3:
Create a project directory.
Let’s name the folder ‘imdb_com’ for ease of use and reference. Open the folder through the text editor and run a terminal (command prompt) in it.
After the terminal window is open, type in the following:
composer init
What this command does is invoke the composer to start a project in the folder currently active.
In our case, it is the folder we just created, i.e., imdb_com. The composer will ask us for more information. Just skim through the process and add the following packages when prompted by the composer prompt during the initial setup.

Step 4:
Once in the screen shown above, type the following:
guzzlehttp/guzzle
Press Enter and then paste the final package we will require:
paquettg/php-html-parser
Once the package download is complete, we will have a directory for the project as shown below:
Step 5:
Now create a new file and name it ‘imdb.php’ in the same root directory as composer.json file. We will be working on this file for the rest of the tutorial.
To start the scraper, we need to define what the PHP file is. Starting with <?php in the first line is a good start.
Import the autoload function with this keyword:
require_once "vendor/autoload.php";
This line loads the file inside the vendor folder in the root directory. It loads all the files we just installed using composer during the initial phase of running our scraper.
use GuzzleHttpClient;
use PHPHtmlParserDom;
The crawler can now start using the packages we download. Now, the question is : why use both require_once and the above script at the same time?
The answer : Require_once provides the directory which contains the necessary files to use the packages we downloaded with the composer. The ‘use’ keyword asks the program to load in the Client and Dom member of the respective classes in order for us to use these functions in our crawler.
Step 6:
Define an object for the GuzzleHttpClient and PHPHtmlParserDom.
$client = new Client([
'base_uri' => 'https://www.imdb.com',
'headers' => [
'user-agent' => 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36',
'accept' => 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8',
'accept-language' => 'en-US,en;q=0.8'
],
]);This code defines a base URL [7] and headers [8] for the website we are crawling.
$dom = new Dom();
It does the same for the other library we just defined in the initial phases of the crawler.
Step 7:
Now that all our tools are loaded in the crawler, we can get to the heart of the program.
Send a ‘GET’ request to this web page.
Note that we have already defined https://www.imdb.com as a base URL for our crawler. So our actual document path to visit would be chart/top/?ref_=nv_mp_mv250, and thus to send the request, we would have to write the following:
$response = $client->request('GET', '/chart/top/?ref_=nv_mp_mv250');
Since we already have the response sent by the web server in response, we load that response into a text variable and send it to our DOM parser to generate a DOM so that referencing parts of documents will be much faster and easier.
$dom->loadStr($response->getBody());
Step 8:
We visit the web browser’s developer console again with the information we had collected before, i.e. about the 250 tr tags containing all the data we need about the movies.
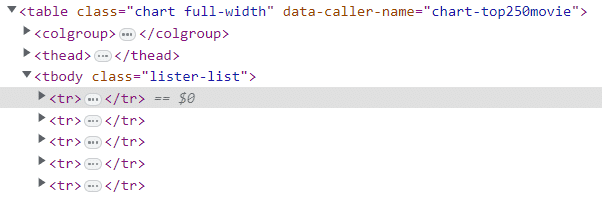
tbody tag. We see that all the movie data we need is contained in the tbody tag. The tbody tag in turn is inside the scope of the table tag.
Rather than processing the entire document since we created a DOM element using the external library, we can reference the table part of the document simply by using CSS Selectors [9].
$movies = $dom->find('table[data-caller-name="chart-top250movie"] > tbody > tr');
Now, we search the entire DOM for a table whose attribute of data-caller-name is chart-top250movie. Once that is found we go one level deeper and find all the tbody tags.
Then, we find all the tr tags by going another level deeper into the tbody tag and finally return all those tags and their members (data) and store it in the movies variable.
You can find more information about various syntaxes of CSS selectors in this link.
Once this is done, all our movie information will be stored inside the movies variable. Iterating over each of the movies will now result in our data of 250 movies information structured in a more proper format.
You can iterate over the movies with:
foreach ($movies as $mId => $movie) {
}Step 9:
Before working on the individual fields, we can introduce a new concept of overriding the DOM elements.
Since the movies variable already has all the information about all the movies we need, reusing the DOM object that has loaded the entire response from the web server is more of an optimization technique employed to reduce the memory footprint of the crawler.
Hence to reuse it, we replace the entire document with only a minuscule part of the document.
We will go into more detail after taking a small segway to another concept. We know that the tr tags contain all the information about the movies.
Copying one tr tag and expanding all the members, we get the following information about each movie (in this case, only the first one).
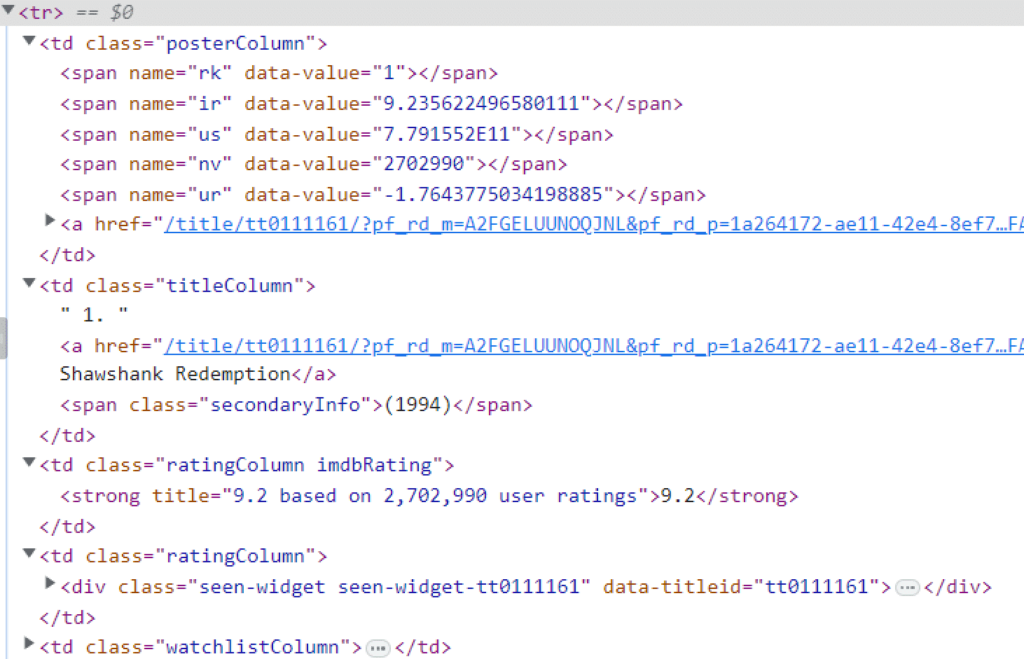
td elements. All the information we need is present in the nested td elements. Now, we can implement the concept of reusing. Since we do not need the entire document anymore, we simply replace this information about the movie contained in the tr tag in the DOM object so we can use the same find() method to scrape the correct information we require. We can do that by using:
$dom->loadStr($movie);
Step 10:
Start filling up the array with the correct key, and value index.
Since we will be replacing the DOM object at many steps throughout the loop it is wise to put all the DOM members in a separate non-replaceable variable first.
$posterColumn = $dom->find('td.posterColumn');
$titleColumn = $dom->find('td.titleColumn');
$ratingColumn = $dom->find('td.ratingColumn.imdbRating');As we can see, rank is present in the main member of the td tag with the class name titleColumn. To extract the rank, write the following code:
$arr['Rank'] = $dom->find('td.titleColumn')->text;
Using only the above code can result in a tiny problem, as the td we just scraped contains not only the rank but also the title of the movie.
Pulling the entire td tag as text also pulls each member of the element not enclosed by tags. Therefore, we use PHP functions to split the entire text with dot (.) and only extract the first data from the array resulting from the split.
$arr['Rank'] = array_shift(explode('.', $dom->find('td.titleColumn')->text));
Now, since we do not know if there are invisible whitespaces in the text we scraped, enclosing it with trim will remove any unwanted whitespaces resulting in a numeric arr[‘Rank’];
$arr['Rank'] = trim(array_shift(explode('.', $dom->find('td.titleColumn')->text)));To extract the attributes from a tag use the getAttributes() method:
$arr['ImageURL'] = $dom->loadStr($posterColumn)->find('img')->getAttributes()['src'];Here, getAttributes generates an array with key value pairs where attribute names are the keys and attribute values are the values. Invoking the individual attribute names, like calling an array member using indexes will return the value we need.
Similarly, filling all the array key values will get you all the information you need about the first movie. Continuing the loop for every one of the 250 movies will result in our crawler scraping all the data we need about the 250 movies.
And whoa, our scraper is almost done!
Creating the CSV
Now that we have created the scraper, it’s time to get the data in a proper format to draw actionable insights from it. To do that, we will create a CSV document. Since CSV creator already exists in the PHP library, we do not need external tools or libraries.
Open a file stream in any directory and use fputcsv in each loop of the scraper we created. It will effectively generate a CSV at the end of our program.
$file = fopen("./test.csv", "w");
foreach ($movies as $mId => $movie) {
fputcsv($file, $arr);
}One thing after running this program, we can notice that the CSV file we generated has no column headers. To fix this we put a condition to dump the keys of the array we generated while scraping in the loop just above the fputcsv line.
foreach ($movies as $mId => $movie) {
if ($mId == 0) {
fputcsv($file, array_keys($arr));
}
fputcsv($file, $arr);
}This way at the start of every loop, only at the first movie the key of that array is used to dump a header file at the start of the CSV file.
The entire code will look like this:
<?php
require_once "vendor/autoload.php";
use GuzzleHttpClient;
use PHPHtmlParserDom;
$fieldsRequired = [
'Rank', 'Title', 'Director', 'Leads', 'URL', 'ImageURL', 'Rating', 'NoOfReview', 'ReleaseYear'
];
$baseUrl = 'https://www.imdb.com';
$pageUrl = '/chart/top/?ref_=nv_mp_mv250';
$headers = [
'user-agent' => 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36',
'accept' => 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8',
'accept-language' => 'en-US,en;q=0.8'
];
$file = fopen("./test.csv", "w");
$client = new Client(
'base_uri' => $baseUrl,
'headers' => $headers,
]);
$response = $client->request('GET', $pageUrl);
$dom = new Dom();
$dom->loadStr($response->getBody());
$movies = $dom->find('table[data-caller-name="chart-top250movie"] > tbody > tr');
foreach ($movies as $mId => $movie) {
$dom->loadStr($movie);
$posterColumn = $dom->find('td.posterColumn');
$titleColumn = $dom->find('td.titleColumn');
$ratingColumn = $dom->find('td.ratingColumn.imdbRating');
$arr = [];
$arr['Rank'] = trim(array_shift(explode('.', $titleColumn->text)));
$arr['Title'] = $dom->loadStr($titleColumn)->find('a')->text;
$names = $dom->loadStr($titleColumn)->find('a')->getAttributes()['title'];
$arr['Director'] = array_shift(explode(" (dir.), ", $names));
$arr['Leads'] = array_pop(explode(" (dir.), ", $names));
$arr['URL'] = $baseUrl.$dom->loadStr($titleColumn)->find('a')->getAttributes()['href'];
$arr['ImageURL'] = $dom->loadStr($posterColumn)->find('img')->getAttributes()['src'];
$arr['Rating'] = $dom->loadStr($ratingColumn)->find('strong')->text;
$ratingText = $dom->loadStr($ratingColumn)->find('strong')->getAttributes()['title'];
preg_match_all("/[0-9,]+/", $ratingText, $reviews);
$arr['NoOfReviews'] = str_replace(",", "", array_pop($reviews[0]));
$arr['ReleaseYear'] = str_replace(["(", ")"], "", $dom->loadStr($titleColumn)->find('span')->text);
if ($mId == 0) {
fputcsv($file, array_keys($arr));
}
fputcsv($file, $arr);
}As a result of our hard-work we will get the following dataset which has all the movies we were looking for. Download the list here.
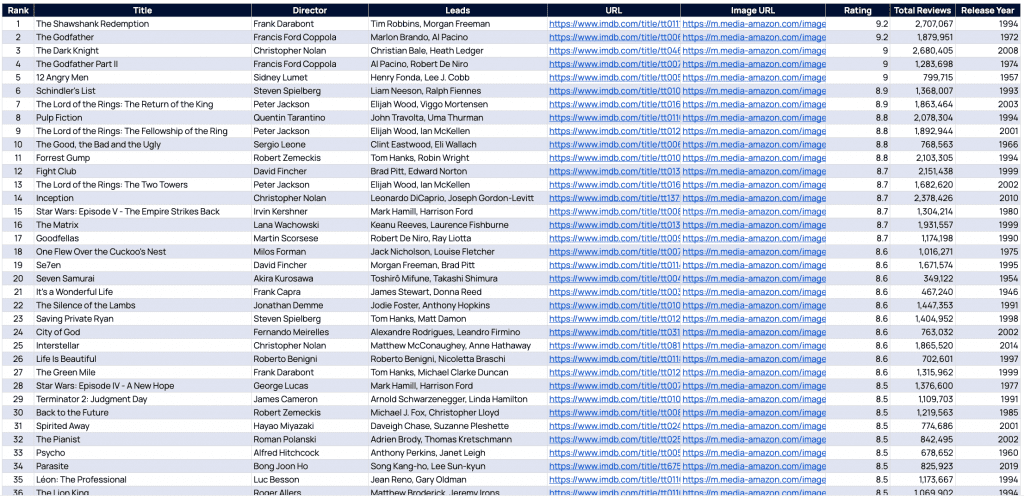
Web scraping with PHP is easy (or not!)
Phew! We covered quite a lot of material there, didn’t we? That is basically how you build a crawler, but we need to understand that web processing is designed with users in mind and not for crawlers.
Data extraction when done haphazardly robs expensive processing time from the web servers and harms their business by preventing the actual users from getting the service.
Which has resulted in source websites employing various blocking techniques to prevent the crawlers from sending requests to their servers.
For small-scale projects, you may go ahead and write the crawler yourself. But, as the scope of the project increases, the complications that arise may be too much for a small team to handle, let alone an individual.
Grepsr, with its years of experience in data extraction has the specialty to extract information from the web without compromising the functioning of the web servers. Read about the legality of web scraping here:

We hope you now have the basic know-how to build a web scraper with PHP. If ever you feel the need to expand your data extraction efforts, don’t hesitate to give us a call. We are happy to help.
FAQs
What is web scraping with PHP?
Web scraping with PHP is the automated extraction of data from websites using PHP scripts that send HTTP requests, parse HTML responses, and store structured information in formats like CSV or databases.
What PHP libraries are best for web scraping?
The most popular are Guzzle (for sending HTTP requests) and PHP HTML Parser (for parsing DOM structures). Alternatively, use Symfony DomCrawler or Simple HTML DOM Parser.
Is web scraping with PHP difficult?
For simple, well-structured websites, PHP scraping is straightforward. However, challenges increase with anti-scraping measures, dynamic JavaScript content, and large-scale extraction requirements.
How do I handle anti-scraping measures in PHP?
Use rotating proxies, mimic browser headers, add delays between requests, and handle CAPTCHAs. For enterprise projects, managed services like Grepsr handle these automatically.
When should I use a managed web scraping service instead of PHP?
Use managed services like Grepsr when you need to scrape at scale (thousands of pages), monitor ongoing data, handle complex anti-scraping measures, ensure legal compliance, or lack in-house technical expertise.
Can I scrape JavaScript-rendered websites with PHP?
PHP alone cannot execute JavaScript. Use headless browsers like Puppeteer (Node.js) or Selenium, or opt for managed services that handle JavaScript rendering automatically.
Related reads: