In the current era of big data, every successful business collects and analyzes vast amounts of data on a daily basis. All of their major decisions are based on the insights gathered from this analysis, for which quality data is the foundation.
One of the most important characteristics of quality data is its consistency, which is when corresponding data fields are of the same type and in a standard format across datasets. This consistency is achieved by data normalization — a process that ensures and improves company-wide success.
What is data normalization?
Data normalization is the systematic process of organizing unstructured data into a consistent, standardized format that eliminates redundancies and anomalies across datasets.
For enterprises handling big data, normalization transforms raw web-scraped information into clean, analyzable data that powers accurate business decisions.
If you look up web scraping on Google, it is most often defined as a technology that allows you to extract web data and present it in a structured format. Big data normalization is the process that organizes this unstructured data into a format, and makes subsequent workflows more efficient.
Generally speaking, it refers to the development of consistent and clean data. Its main goal is to reduce and eliminate redundancies and anomalies, and to organize the data so that, when done correctly, it is consistent and standardized across records and fields.
Why Do Enterprises Need Data Normalization?
It is critical for any data-driven business that wants to succeed and grow, must regularly implement it in their workflow. It removes errors, and anomalies, and simplifies the usually complicated information analyses. This results in a well-oiled and functioning system full of quality, reliable and useable data.
Since it makes your workflows and teams more efficient, you can dedicate more resources towards increasing your data extraction capabilities. As a result, you have more quality data entering your system and get better insights on important aspects, thus enabling you to make more low-risk, data-backed decisions. Ultimately, you see major improvements in how your company is run.
Related read:

How it works
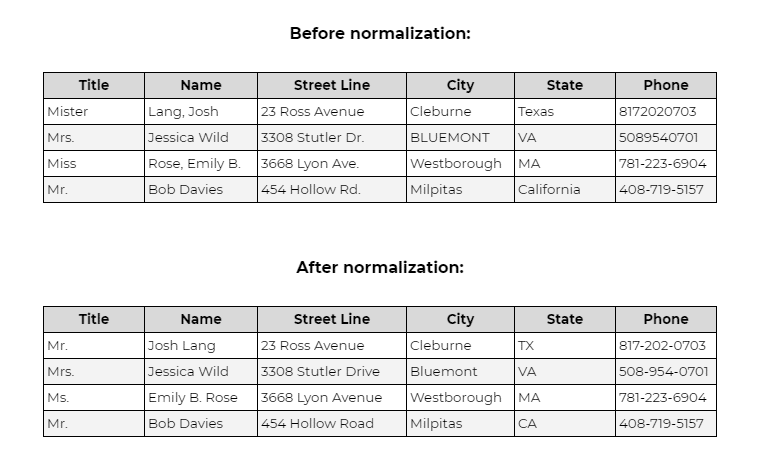
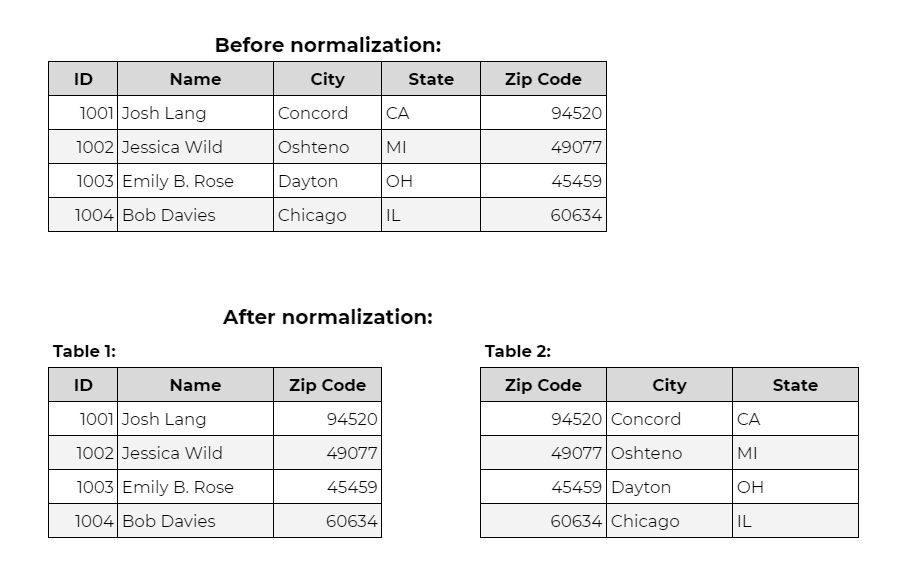
The basic idea is to create a standard format for data fields across all datasets. Here is an example of a dataset before and after:
Apart from this basic standardization, the experts have defined five “normal forms”. Each rule places each entity type into a number category based on the complexity levels.
For simplicity, we’ll look at the basics of the three most common forms — 1NF, 2NF and 3NF — in this post.

What is First Normal Form (1NF)?
In the first normal form, each cell must have a single value and each record must be unique. This ensures there no duplicate entries.
1NF rules:
– Each column contains atomic (indivisible) values
– Each column contains values of a single type
– Each column has a unique name
– The order of rows does not matter
Example: A contact table with “555-1234, 555-5678” in the phone column violates 1NF. After normalization, each phone number becomes a separate record.
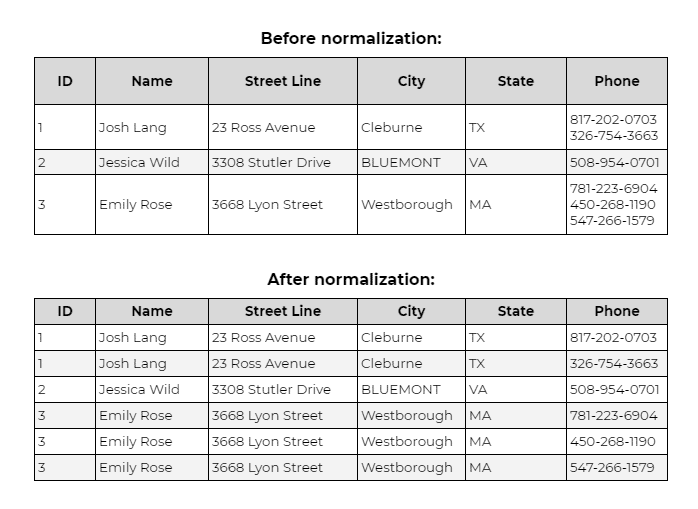
What is Second Normal Form (2NF)
For data to fulfil the 2NF rule, it should firstly comply with all 1NF requirements. Then, it must have only ‘primary key’ (ID in the example below), for which all subsets of the data are placed in different tables. Relationships among entities can be created via ‘foreign keys’.
2NF rules:
– Must satisfy all 1NF requirements
– All non-key attributes must depend on the complete primary key
– Partial dependencies are moved to separate tables
Example: In an order table with composite key (Order_ID, Product_ID), storing Product_Name violates 2NF because Product_Name depends only on Product_ID, not the full key.
The solution: create a separate Products table where Product_Name depends on Product_ID alone.
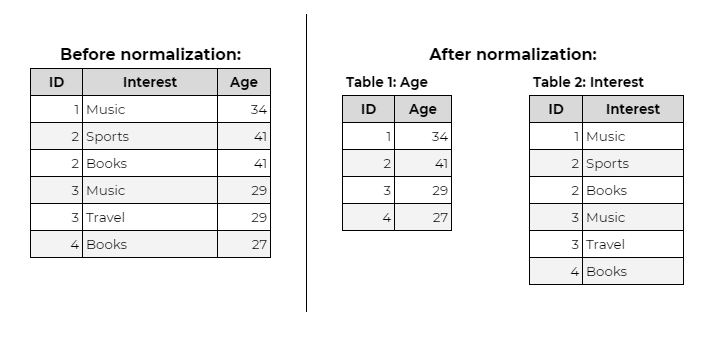
What is Third Normal Form (3NF)
In the 3NF rule, the data should firstly satisfy all 2NF conditions. Then, it should only be dependent on the primary key (ID). If there is a case of change in the primary key. Then it involves moving all the associated and impacted data to a new table.
3NF rules:
– Must satisfy all 2NF requirements
– No non-key attribute depends on another non-key attribute
– Every non-key attribute depends directly on the primary key
Example: A customer table with columns Customer_ID, ZIP_Code, and City violates 3NF because City depends on ZIP_Code (non-key) rather than Customer_ID (primary key).
The solution: create a separate ZIP_Codes table linking ZIP_Code to City.
If you’d like a more detailed explanation of the normal forms, you can find it here.
What Are the Key Benefits of Data Normalization?
In addition to the merits mentioned above, the following are some of the other major benefits of normalizing any data:
Improved consistency
With it, all your data and information are stored in a single location. This reduces the possibility of inconsistent data. This in turn improves the quality of your dataset, thus strengthening your foundations, so teams can avoid unnecessary risks during decision-making.
More efficient data analysis
In databases crammed with all sorts of information, it can eliminate duplicates and organize unstructured datasets. This removes all unnecessary clutter, freeing up spaces to drastically improve processing performances.
As a result, all important systems load quicker, and run smoother and faster, allowing analysts to process and analyze more data and gain more valuable insights than ever before.
Better and faster data-driven decisions
Thanks to normalization, teams and analytical systems process more data with ever-increasing efficiency. Moreover, with already-structured data available, they spend little to no time in modifying and organizing data. Such datasets are easy to analyze, so you are able to reach more meaningful and insightful conclusions much quicker, saving valuable time and resources.
Improved lead segmentation
Lead segmentation is one of the most effective methods to grow your business, and normalization simplifies it manyfold. It is easier to segment your leads based on industries, job titles, or any other attribute. You are then able to create specific campaigns and tailor experiences based on the specific needs of each target segment.
With data becoming increasingly valuable to companies and brands worldwide, it is imperative to prioritize its quality to reap lasting benefits. Normalization ensures consistency across all of your datasets, so everyone in your organization is on the same page to move seamlessly towards achieving the common goal.
Hence, data normalization should not merely be one of the options or tools at your disposal, but one of the first processes that you employ to take your company to the next level.
About Grepsr
At Grepsr, we always strive to provide the highest quality data to our customers. The basic aspects of data normalization — deduplication, standardization, etc. — are always the first parts of our QA process. The datasets we deliver are therefore reliable and actionable straight out-of-the-box, so you’re able to quickly gather insights and charter the path of continued success.
Our normalization process includes:
Automatic standardization: Converting dates, phone numbers, addresses, and prices to consistent formats specified by your requirements
Deduplication: Identifying and removing duplicate records across multi-source data collection using fuzzy matching algorithms with 95%+ accuracy
Schema mapping: Transforming varied source data structures into your target database schema with normalized table relationships
Validation rule: Applying custom business rules to ensure data consistency across all fields and records
Quality metrics: Providing detailed reports on data accuracy, completeness, and consistency for every delivery
FAQs
What is the difference between normalization and denormalization?
Normalization organizes data into multiple related tables to eliminate redundancy, while denormalization deliberately introduces redundancy by combining tables to improve read performance. Denormalization is used in data warehouses and analytics databases where query speed matters more than storage efficiency.
When should you not normalize data?
Avoid normalization in read-heavy analytics databases, data warehouses, and reporting systems where query speed is critical and data updates are infrequent. Denormalized structures in these scenarios reduce complex joins, improving query performance by 5-10x for analytical workloads.
Does normalization slow down database performance?
Normalization can slow down complex queries requiring multiple table joins, but speeds up updates, inserts, and simple queries. For transaction-heavy systems (OLTP), normalized structures typically perform better overall. For analytics-heavy systems (OLAP), denormalized structures often perform better.
How does normalization reduce data redundancy?
Normalization reduces data redundancy by storing each fact in exactly one location and using foreign keys to reference it from other tables. Instead of storing customer addresses in 15 different tables (redundancy), normalized databases store addresses once in a customers table and reference it via Customer_ID.
What is the highest normal form?
The highest recognized normal form is Sixth Normal Form (6NF), which addresses temporal data and interval relationships. However, most enterprise databases stop at Third Normal Form (3NF) or Boyce-Codd Normal Form (BCNF) as higher forms offer diminishing returns and increased complexity.