


Data has now become something of a currency in the twenty-first century. But, when you think of data, does web scraping come to your mind? We’re here to tell you it should.
The best ideas are the most simple, much like web scraping. Take a loud speaker for example.
On the outside, a speaker is a mysterious object playing music with precision even real concerts fail to emulate. Technically, it’s nothing more than a voice coil creating magnetic fields around it.
When an electric signal passes through the coil, the magnetic field it generates interacts with the permanent magnet.
As a result, the attached cone and voice coil moves back and forth, messing with the air, and causing compressions and rarefactions in the air molecules.
This change in pressure emanates as sound waves.
What might have seemed like sorcery to a seventeenth-century person is actually a neat trick.
Automate data extraction with web scraping
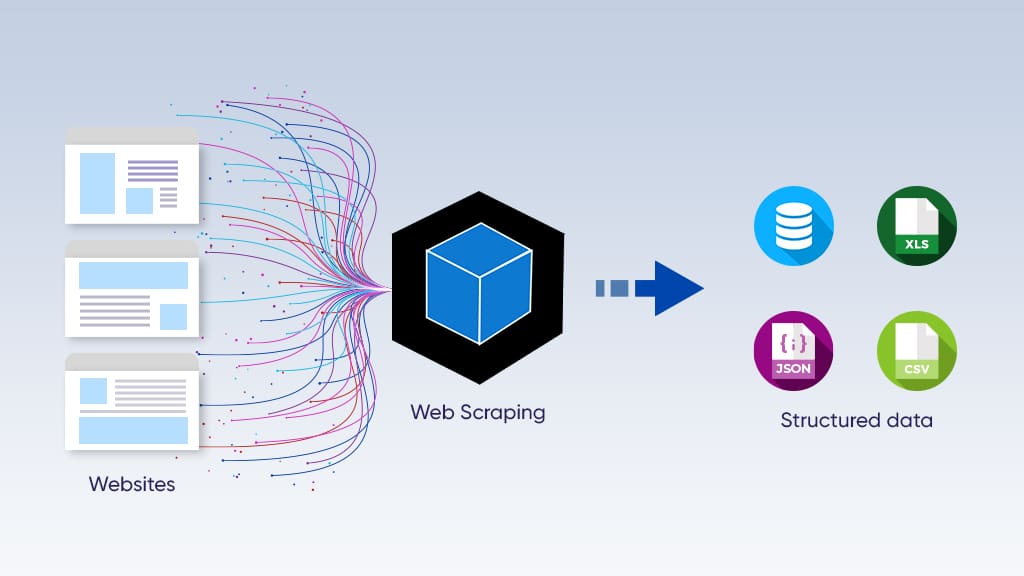
In the same vein, web scraping is the cornerstone of the most influential tech giant of today – Google. It scrapes data from all over the world and presents it to the people who are looking for a set piece of information. Neat, isn’t it? Perhaps we are oversimplifying here. Or, are we?
Some of the biggest brands in the world leverage web data to develop products and services that not only earn them dollars in the millions (if not billions), but also creates an impact matched by few.
Whether to predict economic recessions or create the next big cultural sensation, web data comes in handy. The more data you have, the better your chances at success.
Now, you have two options: copy and paste each data point into a spreadsheet and pass down the task to your grandchildren as a multi-generational endeavor.
Or, you can automate data extraction with web scraping. Get the data fast. Obtain the insights faster, and make informed decisions before your competitors catch a whiff. We recommend you choose wisely.

Web scraping – The crawler guides, the scraper extracts

Web scraping is the process of automating data extraction from a website. Then, data extraction involves organizing the information in a structured legible dataset.
When you visit a webpage, you send an HTTP request to the server. Basically, you are asking to be let in.
In automated data extraction, a computer program called the crawler is tasked with sending the request. It is responsible for exploring the web by following links and discovering specific web pages. When granted access by the web server, the crawler saves several links from the response. It adds those links to a list that it acknowledges for visitation next.
The crawler goes through this process iteratively until a predefined set of criteria is met.
However, the scraper is responsible for extracting particular data from the links visited by the crawler. It parses the HTML and scrapes the data in a desired format, be that CSV, JSON, or a simple Excel sheet.
Bear in mind that writing the crawler is the easiest part of data extraction.
Crawler maintenance? Not very much.
Most websites change their structures frequently. As data requirements increase, crawler maintenance wins a special place in the data project. It takes up most of the costs associated with your overall data extraction.
Similarly, the disposition of scrapers needs to change according to the nature of the source website. For instance, you may need to write a different scraper for scraping Google and Amazon. We do that to account for the semantic variations in the websites.
You can think of the crawler as a military general taking his soldiers (the scraper) to battle. The crawler creates strategies and identifies targets, whereas the soldiers execute the strategy. In web scraping, the scraper extracts the data under the guidance of the crawler.
Read five reasons why you need an external data provider here.

Web scraper: build or buy
The DIY web scraping solution
Websites are virtual shops in the World Wide Web. Wix is there to offer website development services while Amazon sells products.
Owing to their different goals, information is stored in a way that best fits the purpose of the website. When your data needs are minimal, you can easily code a web scraper yourself and collect the data through a predictable web scraping process.
You can use Python libraries like BeautifulSoup, and Scrapy for web scraping. Pandas and Polars are some from a similar ilk that are extremely helpful to process data scraped from websites.
If you are looking to build small-scale web scrapers, consider going through our how-to guides on data extraction with Python and PHP below.


A word of caution – you can hamper the performance of your source websites when you begin collecting data at scale. Sending too many requests to the server can negatively impact its performance. Afterall, most websites have a specific purpose for existing, i.e., to serve their readers and customers, and casual browsers from time to time.
Furthermore, you run the risk of using up most of the power of your own computer systems, chiefly storage and RAM. You wouldn’t be able to properly utilize other applications in your program until the completion of your data extraction project.
Not all people prefer going the build route. If you have zero experience in coding, you are in luck. Check out our free web scraping tool here. It’s a browser extension you can easily install. Further, the web scraping tool provides an intuitive point-and-click interface for easy data extraction.
Problems with large-scale data extraction
Let’s say you need to monitor thousands of product prices on Amazon. Since prices change quite frequently, it becomes necessary to keep up with the price fluctuations.
Add other e-commerce websites such as eBay, Target, and Walmart to the mix, and you have a lot of web scraping mess on your hands.
To add to that, websites change their structures frequently and apply various anti-bot measures. Other than activating the robots.txt file, which informs the web scraper which content they can and cannot access, they also employ advanced anti-bot measures like IP-blocking, Captcha, and honeypot traps.
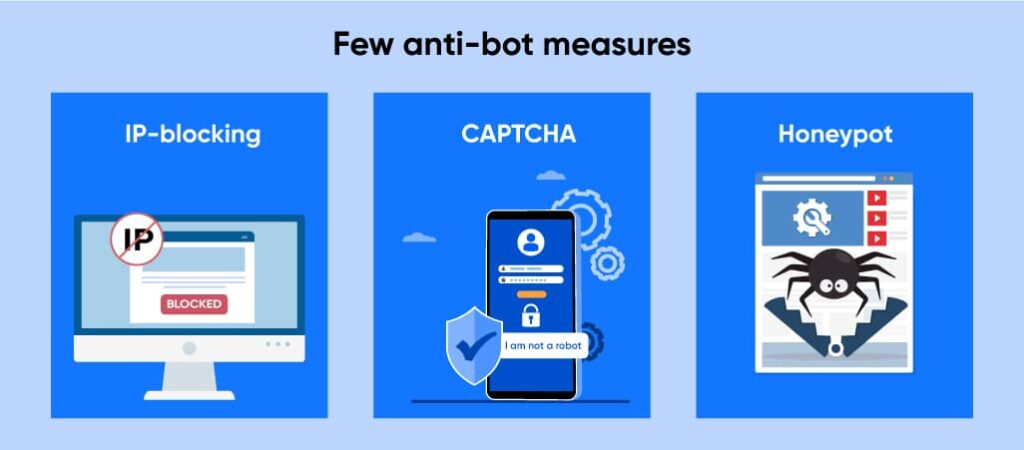
- IP-blocking: The web host monitors the visitors accessing their website. They block IP addresses that make too many requests.
- Captcha: Websites apply the Completely Automated Public Turing Test for Telling Computers and Humans Apart to block bots from accessing their content.
- Honeypots: Typically, websites add imperceptible links on their web pages. Something a human could tell apart.
To navigate these challenges efficiently, businesses and data scrapers are increasingly considering CAPTCHA proxies as a potent solution to overcome CAPTCHAs, ensuring uninterrupted access to precious web data critical for strategic decision-making.
All of that without calling the legality of web scraping into question. As a rule of thumb, you should never extract data that is not publicly available. Read about the legality of web scraping here.

The managed data extraction solution
Now that we’ve established the problems associated with large-scale data extraction, we can finally learn about its remedy.
Grepsr is one of the few and most reliable managed data extraction service providers available for global data needs. We provide a no-code tailor-made solution for web data extraction.
It’s a concierge service designed to shield users from the nitty-gritties of the web scraping process. We come with a targeted focus on quality, and a decades worth of experience behind us.
Grepsr’ data extraction and data management platform is built for enterprise web scraping needs.
Primarily, our large-scale data management platform is characterized by the following features:
- Web scraping automation: Implement timely updates on web scrapers and handle millions of pages every hour.
- Multiple delivery options: Deliver data in the format most suitable to you – Drobox, FTP, Webhooks, Slack, Amazon S3, Google cloud, etc.
- Data quality at scale: Deliver high quality data at scale by relying on a mixture of people, processes, and technology.
- Easy automation & integration: Set up custom data extraction schedules, and automate routine scrapes to run like clockwork.
- Responsible web-scraping: Round-the-clock IP rotation and auto throttling to avoid detection, and prevent harm to the web sources.
Final words
If you are new to web scraping, then we trust that by now you have everything you need to get started.
If you are a seasoned professional, feel free to contact us for a no-strings-attached data consultation. Maybe we will uncover angles you have not thought of before.
As for the applications of data extraction, we have not even scratched the surface in this article. Nevertheless, you can go to our industries section to learn how web scraping can be beneficial to your industry niche.
From e-commerce to journalism, web scraping is an efficient and effective way to get access to actionable data. From an intuitive viewpoint, web scraping may not be the first thing that comes to your mind.
But then again, it’s the simple ideas that often catch you off-guard.



















































































































































