


The internet is a messy, beautiful disaster: home to everything from baby photos to Reddit rants.
No wonder it’s home to a gigantic 175 zetabytes of data.
For NLP models, this chaos is a feast if you can tame it.
But turning the internet into high-quality training data isn’t as simple as Ctrl+C, Ctrl+V-ing information into a dataset.
That’s because the web is full of bias, noise, bot-generated nonsense, and paywalls.
So, how do you collect, clean, and optimize this chaotic mess into training data that creates stellar NLP systems?
How do you handle different website structures and stubborn APIs? Then, how do you turn that into the muscles for a chatbot?
We’ll uncover all of that. And with Grepsr by your side, data extraction will never be a headache. We promise.
Why Web Data for NLP Model Training?
If your NLP model doesn’t have enough high-quality, real-world text data, it’s basically an overconfident parrot – regurgitating what it’s learnt without understanding.
But raw text alone isn’t enough; what makes web data so powerful?
- Scale and diversity: People text, tweet, and rant very differently from how they write research papers. With web data, you get formal, informal, unstructured, and chaotic text at an unprecedented scale.
- Context and relevance – The internet is a linguistic petri dish. It picks up slang, niche jargon, and cultural shifts in real time so that your AI doesn’t sound like it’s stuck in 2010.
- Cost efficiency: Manually curating data is expensive. Data on the web? Feels practically limitless.
Is it all so sweet and easy? No. If you’re not careful, your model might pick up more than just good grammar.
Try Grepsr to extract all kinds of data from the web without the noise. Then, use it for research, NLP training, or whatever. How? Coming to that in a moment.
Structured vs. unstructured web data: What’s worth scraping?
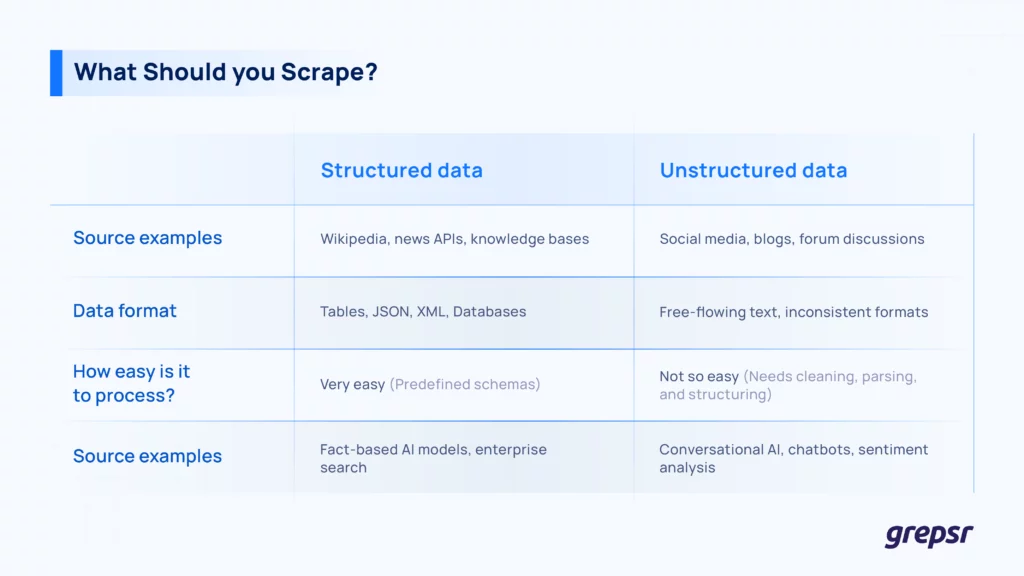
When scraping the web, you’re going to deal with two types of data:
Structured data
This data is organized in a predefined format, often fitting into tables with rows and columns. It follows a fixed schema, which makes it easy to store, query, and analyze.
Examples include:
- Databases (SQL tables, NoSQL documents)
- Spreadsheets
- API responses (JSON, XML )
- Knowledge bases (Wikipedia, Wikidata, government datasets)
Unstructured data
This is raw, free-form text that doesn’t adhere to a fixed format. You’ll find it in social media posts, blog articles, forum discussions, and customer reviews on various sites. In fact, around 80% of the world’s data is unstructured.
It needs preprocessing (cleaning, tokenization, entity recognition, etc.) to be useful for AI models or analysis.
If you’re building a general-purpose NLP model, you’ll want a mix of both.
Large-scale datasets like The Pile, an 825GB corpus sourced from 22 diverse, high-quality text subsets, have shown that data diversity directly improves model performance across different domains.
The ideal web data mix for different uses
Data selection also matters in this regard. What works for one NLP model might be useless for another.
Different sources have different uses:

Now, how do you procure this data in a scalable, accurate, and useful way for training NLP models?
A thread on r/learnmachinelearning from about three years ago asks the same question: Where to snag training data? (See, data collection is still just as confusing!)
Via Reddit
(Spoiler alert: The best way to get web data for NLP and chatbots is Grepsr. More on that later!)
Enough talk! Let’s get into it.
Getting the Right Web Data for NLP
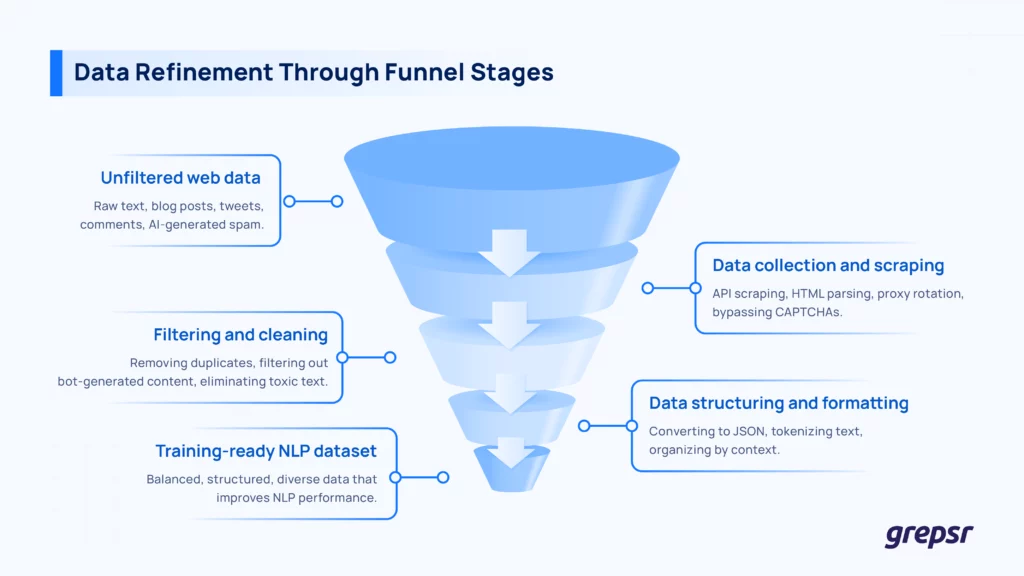
Scraping web data sounds simple in theory. Point a bot at some URLs, pull the data, and call it a day. If only it were that easy.
In practice, scraping for NLP is messing around with rate limits, CAPTCHAs, bad site structures, and the rest.

Via Reddit
So how do you get meaningful, structured, and diverse data for training NLP models without spending weeks fixing HTML soup and filtering nonsense?
1. Choose the right scraping method
There’s no perfect web scraping method. It depends on the source, the structure of the content, and the type of data you need.
Arguably, the cleanest way to collect structured data is API scraping. Platforms like Reddit and news sites offer APIs, but they often have strict rate limits and are expensive.
HTML Parsing is good for extracting text from blogs, forums, and other websites without APIs.
BeautifulSoup, lxml, and similar tools let you manage HTML structures, but you’ll need a plan to handle different site formats.
If JavaScript-heavy sites block traditional scrapers, tools like Selenium or Puppeteer can render pages dynamically. Downsides? It’s slow and gulps resources. To avoid IP bans, rotating proxies and headless browsers mimic human behavior, and make large-scale scraping (somewhat) more feasible.
Fortunately, we have a solution. Grepsr pulls in only relevant, high-quality text from all corners of the internet. You know how traditional scraping takes forever, especially if you’re working with massive datasets.
Grepsr optimizes requests, bypasses rate limits, works in parallel, and slashes turnover times. Get accurate data at scale with Grepsr, just how you want it. With Grepsr, you don’t have to immerse your head in working through Selenium, Puppeteer, or all those ol’ school ways of getting data.
Subscribe to Grepsr and get the data you need, whenever and wherever.

2. Filter out the noise
Once you’ve scraped raw text, separate the signal from the noise. Your filtering process should:
- Get rid of non-text elements: Ads, footers, navigation menus, and everything else that isn’t natural language.
- Detect and delete duplicates: Duplicate content skews training and bloats your dataset.
- Filter out low-quality text: Spam, keyword-stuffed content, and nonsensical AI-generated slop must be discarded before it contaminates training data.
Of course, a solution like Grepsr dramatically reduces the time spent on post-processing, and you get clean, structured text from day one.
Scaling Web Data for Large-Scale NLP Models
Okay, you’ve got your clean, sorted web data.
But what happens when your model needs billions of tokens? What about when your model architecture scales from a few million to hundreds of billions of parameters?

When you are working with web-scale data, you’ll also have to think about storing, managing, and processing it efficiently.
Ready to step in the mud?
- Storage issues: Regular relational databases choke on massive, unstructured datasets. Solutions to help you here include distributed storage systems like AWS S3, or Google Cloud Storage.
- Efficient retrieval: Querying petabytes of text calls for high-throughput systems like Elasticsearch or FAISS (if you’re working with embeddings).
- Parallel processing: Web-scale NLP data pipelines rely on Apache Spark, Ray, or Dask to preprocess datasets in parallel.
At this scale, you’re working with web-scale text ingestion, cleaning, and transformation. Just hope that your system doesn’t freeze or you don’t crash your cloud system!
Using a specialized NLP data management solution like Grepsr is much better. Apart from collecting raw data, Grepsr also delivers structured, queryable datasets so that your NLP model gets the data it needs without infrastructure holding you back.
Now, let’s put this data to good use.
Finally, How Do You Use Your Procured Web Data to Train Your NLP Model?
Now comes the real work: turning your cleaned and structured dataset into a reliable NLP model.
1. Choose the model for your NLP task
The first step is selecting the right model architecture. Pre-trained models are almost always a good starting point. You can find many models on the Hugging Face Model Hub.
(If you’re a large organization that wants to develop its own model, well, that’s a possibility too. Let Grepsr help you with the data there).
If your goal is information retrieval or search, retrieval-based systems like Dense Passage Retrieval (DPR) or BM25 excel at surfacing relevant content from a structured database. These are great for knowledge bases, enterprise search, and FAQ automation but won’t generate new text.
If you want a domain-specific NLP model, such as one for use in legal, medical, or financial applications, it’s almost always a good idea to start from a pre-trained model and refine it on industry-specific text.
This approach, called transfer learning, lets you use powerful base models without needing to train from scratch. You also benefit from lesser compute costs and training time.
And data, count on us to get it on your plate. 🙂
2. Refine the model with your data
Since you’ve already cleaned and structured your dataset, you now need to format it correctly.
For a chatbot, for instance, your dataset should be structured as prompt-response pairs (user question = ideal chatbot reply).
If you’re training a retrieval-based model, you’ll need query-retrieval pairs, where the system learns to fetch the most relevant response from a database.
A training sample looks like this:
Prompt: What are the symptoms of dehydration?
Response: Common symptoms of dehydration are dry mouth, dizziness, and dark urine.
Once your dataset is formatted, you need to tokenize it, i.e., break the text down into units that the model can process.
Most modern NLP frameworks like Hugging Face’s Transformers, make this easy. Be mindful of token limits, though.
Full fine-tuning is usually too expensive for large models.
Instead, you can use parameter-efficient fine-tuning methods like LoRA (Low-rank adaptation) or QLoRA, which reduce the GPU memory need by a lot while maintaining performance.
Grepsr gives you clean, structured datasets in JSON, CSV, which you can easily feed to your NLP training pipeline.
3. Check how your model is performing and optimize accordingly
Once your NLP model is trained, test whether it performs well in real conversations.
How do you do that? Keep an eye on these:
- Perplexity score: Measures how well the model predicts the next word in a sequence. Lower is better.
- Response coherence and relevance: Find out if the model answers the question in a meaningful way.
- Hallucination rate: If your model is making up facts, tweak your dataset balance or apply more supervised fine-tuning.
- Bias and toxicity detection: Run the model through Perspective API, OpenAI’s moderation tools, or custom filters to make sure it doesn’t produce harmful responses.
Human evaluation is also a must. Feed the model real-world queries and assess its responses with your own eyes and mind. If it frequently fails in certain areas, refine it with targeted data.
4. Final optimizations and your NLP model is ready to deploy
After refining and testing, deployment is the final line to cross. If your model is likely to handle sensitive information, an on-premise deployment is best.
Otherwise, cloud-based solutions like AWS and Azure provide enough scalability, though costs can become prohibitive with high traffic.
Some organizations also opt for API-based inference, where the model serves as an endpoint for easy integration with web apps and enterprise software.
Garbage In, Garbage Out, Unless You Do It Right
If you want an NLP model that understands human conversation, including slang, context, and nuance, you need accurate, diverse, and well-structured web data.
And unless you have the time (and patience) to manually sift through the junk, you need a smarter way to collect and organize it.
Instead of wasting weeks dealing with broken HTML, duplicate content, and biased datasets, Grepsr delivers clean, structured, ready-to-train data at scale and without the headaches.
So, what’s it going to be? Spend months wrangling messy data, or get high-quality web data delivered right away? If you’re ready to build smarter NLP models, Grepsr has the data you need.




















































































































































