Over the last twenty years, Amazon has established itself as the world’s largest ecommerce platform having started out as a humble online bookstore. With its presence and influence increasing in more countries, there’s huge demands for its inventory data from various industry verticals. Almost all of the time, this data is acquired via web scraping and similar techniques.
As a data-as-a-service (DaaS) platform, we collect, transform, and deliver data for millions of ASINs and search terms at a very high frequency for many brands, manufacturers, sellers and agencies. Our clients use this data to monitor the constant changes occurring on Amazon that can have a significant sales impact.
Since web data extraction is a specialized segment within the technology industry, we often replace existing scraping companies or internal processes that do not have the necessary technologies, people, and processes in place to scrape data from Amazon at scale. Contact us today with your Amazon-specific data requirements.
Our Amazon scrape data is used in a variety of ways, including:
- Competitive intelligence
- M&A analysis
- B2B lead generation
- Stock availability
- Pricing, content, images, search results (Share of Search — including organic and paid placements)
- Advertising spend analysis/decision-making
- Consumer sentiment via ratings, reviews, and Q&A, etc.
Scraped data from Amazon is pulled from the lens of the consumer which is often substantially different from data provided by various Amazon APIs. One analogy of ecommerce related scrape data is that it is the online equivalent of a brick-and-mortar mystery shopper.
Overview of the challenges
We exceed our customer’s expectations in terms of data quality despite the many challenges associated with scraping data from a site like Amazon. Some of these challenges include:
- Many different formats of product page listings/templates that are constantly being tweaked/updated along with UX A/B testing of new layouts, ad placements, etc. that Amazon is always testing
- Different product variations (one product page but multiple colors, sizes, flavors, etc. available), different layouts for product variations, and consistent changes in the approach to displaying variations
- Collecting data at scale while avoiding web Captchas and IP blacklisting
- Inconsistent versions and features of Amazon across the growing list of countries in which Amazon has a presence
- A significant investment in technical infrastructure to accurately collect Amazon data at scale

But first, what is web scraping?
Web scraping is the process of extracting publicly available data from a website and putting the collected data into a structured format such as Excel, JSON, or CSV for the purposes of analysis and decision-making.
Web scraping is like web indexing or crawling, the process used by search engines like Google or Bing to help make information on the web easier to find. However, the key difference between web scraping and web indexing is the structured format of web scraped data compared to the unstructured format of web indexing.
From a legal standpoint, laws and terms of use that govern web indexing are also applicable to web scraping.
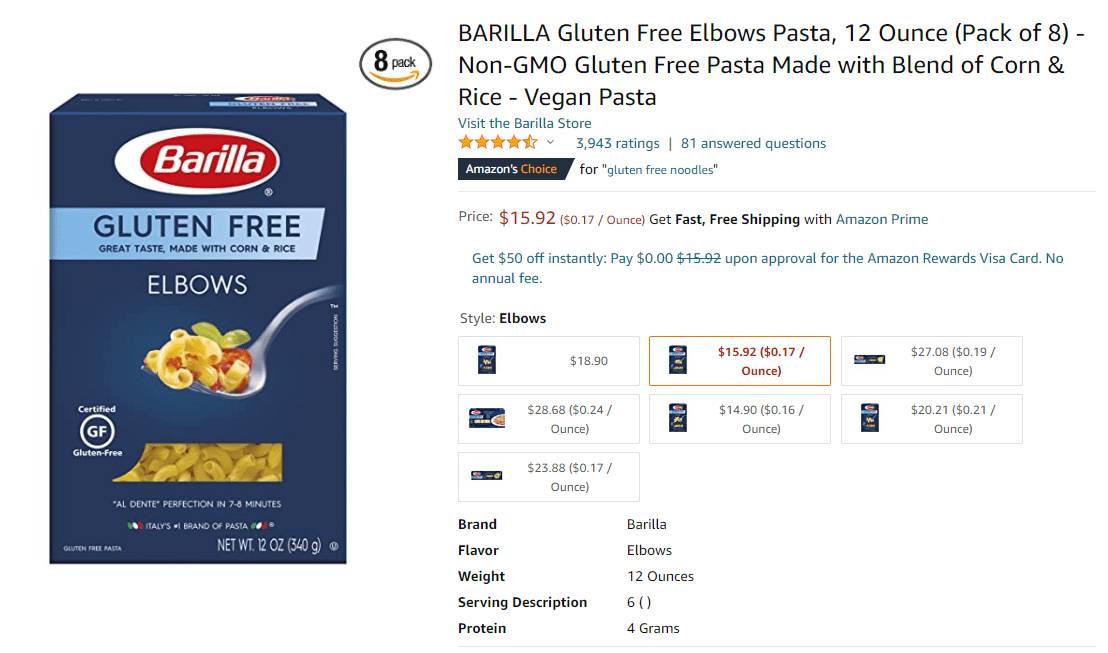
Product pages and search results have varying page structures
A lot of products on Amazon have different layouts, attributes and HTML tags due to the many templates in use on the site to add and update product content. This is often done to cater to different types of products that may have different key attributes and features that need to be highlighted.
In addition, since Amazon has been around for over 20 years now, the site has gone through many different redesigns but not all products have been migrated to newer template layouts. Templates also vary significantly during the item setup process on Amazon based on the category or product group of newly added ASINs.
In addition, Amazon sites vary significantly by geography, with the US market typically being the first to roll out and test new features and functionality, and other markets getting upgraded at later times. A screenshot of a sample template is shown below.
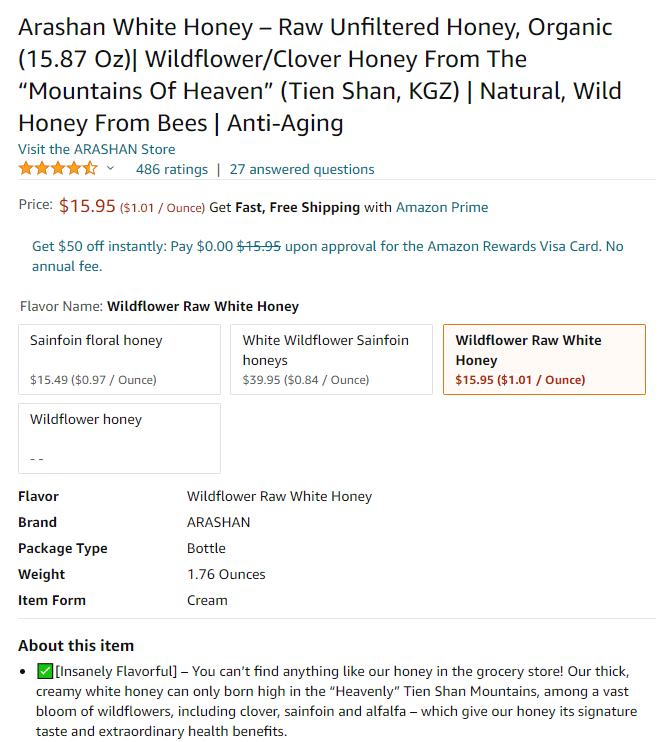
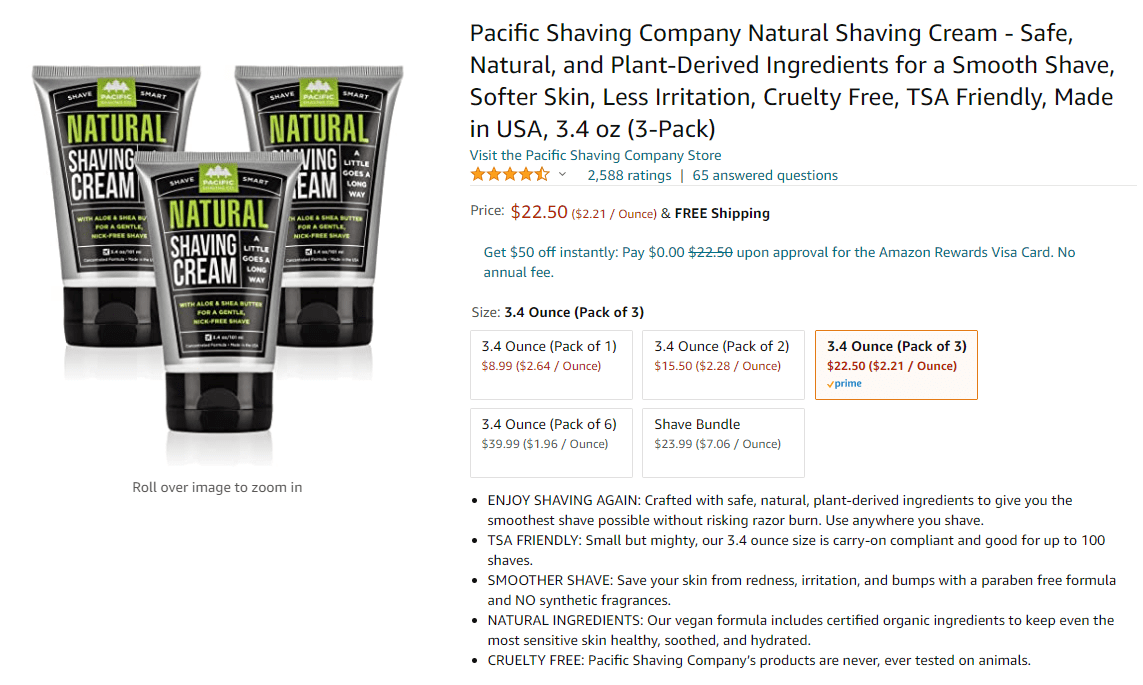
Different product variations
Variant product detail pages are single product pages which allow consumers to easily browse and purchase multiple products. Some good examples are:
- Diapers/nappies available in multiple sizes
- Lipsticks available in a variety of colors
- Pasta available in a variety of types
Amazon was one of the first online retailers to provide this functionality and continue to evolve it. From a scraping standpoint, these variations are similar to the templates mentioned above but again are displayed on the site in many different ways. In addition, ratings & reviews are often rolled up and counted towards all available variations instead of against one version of the product.
Although when we scrape review content for our clients, we display review totals and review content at the ASIN level in our data to better discern product feedback at the individual product level. Related to variations, Best Seller Rank information used to be displayed for all ASIN variations but now the same information is shown for each variation, and there have been lots of recent updates related to the format and count of the Best Seller Rank assignments displayed on product pages.
Web Captchas, blocking and blacklisting
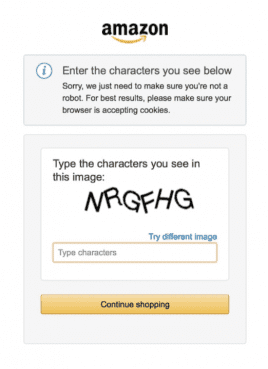
Amazon is very good at distinguishing between scrapers and human actions. When scrapers are detected on Amazon and/or a user makes 400+ similar page requests in a single session, steps are taken to verify if the traffic is coming from a human or from a machine. The first step in the process is to show a Captcha screen, like the one on the left, requiring unique codes to be entered before displaying additional products or search results. If an IP address continues to make Amazon page requests without verifying the Captcha, the IP address will be blocked or blacklisted from accessing Amazon.
To avoid these blockages, we try to make our crawlers’ browsing behavior seem more human than robotic as much as possible. Some of the workarounds that we employ are:
- Avoid repetitive and predictable actions
- Constantly rotate IP addresses
- Send page requests at random intervals
- Spoof the User Agent on the crawler headers to avoid Amazon’s generic anti-crawl response
This approach makes it harder to identify a scraper by accessing a small number of pages from one IP address before switching to another. From our customers’ perspective, the end result is an unbroken stream of quality data.
Amazon features across geographies
When browsing an Amazon country variant from a different location, there’s significant disparity in the product listings, search results and product detail pages. For example, when browsing amazon.com — the US platform — from Germany, Amazon only lists items that ship to Germany. Also, attributes like price and availability are only displayed when a US zip code is entered as the delivery address.
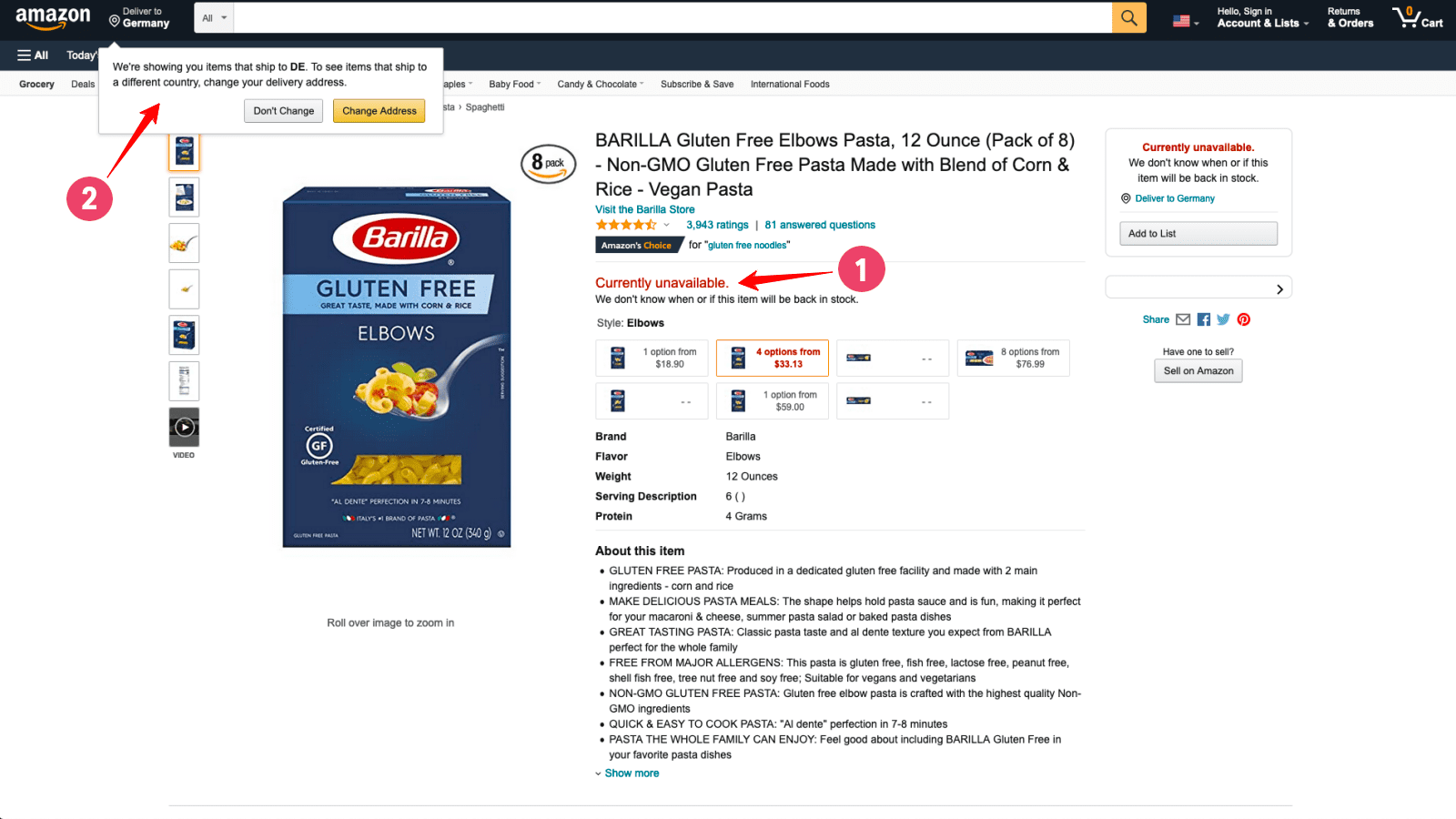
1 – Pricing information not disclosed. Item is shown as unavailable.
2 – Amazon prompting the visitor to enter a US delivery address.
Amazon does prompt users to change their location during the first browsing session, but coding this into a crawler isn’t always feasible. To overcome this, we use the IP addresses of the country whose Amazon platform we’re collecting data from.
Significant investment in technical infrastructure
In order to handle large volumes of datasets of Amazon products from their worldwide variants, we’ve invested in the highest end cloud storage platforms with high capacity memory resources and high efficiency network pipes and cores. This also helps us avoid memory issues and over-burden our local resources, so we can speed up our clients’ access to their datasets.
In addition, we’ve recently added more specialists to cater to the ever-increasing demands, while also implementing various advanced machine learning algorithms to make Amazon data sourcing as efficient and quick as possible.
Summary
Web data acquisition is a specialized area of expertise in itself. Some businesses may get by with an in-house team of just a few people when dealing with lower scale data requirements. But when your datasets are huge, like Amazon product information that ranges in millions of records every day to billions every month, you’ll need a specialized solution to take care of the data collection. Add to that the complexities discussed earlier, and your in-house team will almost certainly run into memory losses, IP blocking and empty dataset issues without adequate measures and resources in place.
This is where Grepsr can be your perfect asset. With over a decade of experience, we’ve extracted product data from not just Amazon and all of its geographic variants, but also numerous other ecommerce platforms. Our team of experts have handled and overcome all sorts of obstacles and challenges during the acquisition process to deliver the highest quality service to our customers.
Get in touch today with your requirements. We’re sure we can work out a solution for you!