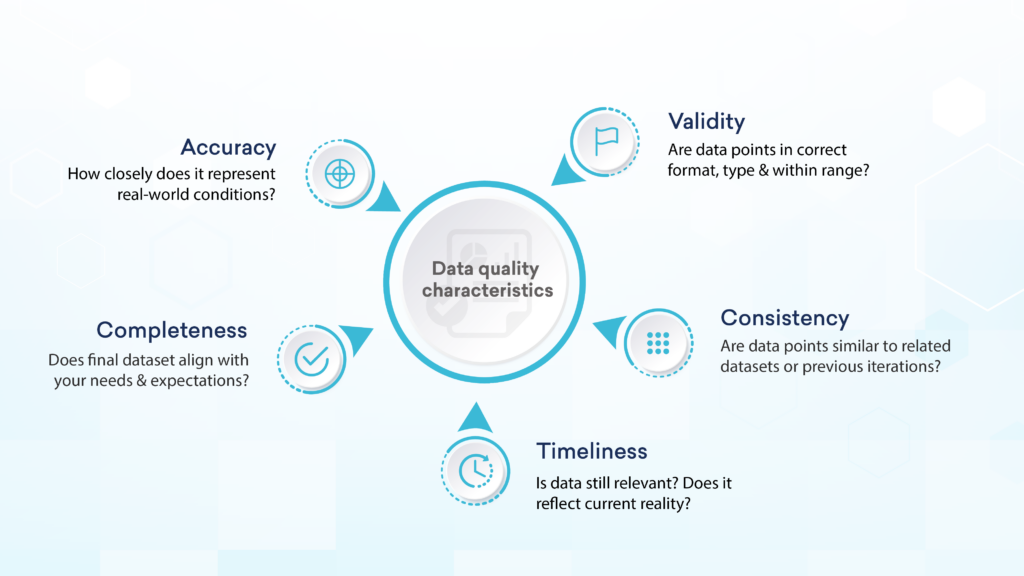
Quick Answer: High-quality data has five essential characteristics: accuracy, completeness, reliability, relevance, and timeliness. These attributes determine whether your data can support effective business decisions, analytics, and operational processes.
Big data is at the foundation of all the megatrends that are happening today.
Chris Lynch, American writer
More businesses worldwide in recent years are charting their course based on what data is telling them. With such reliance, it is imperative that the data you’re working with is of the highest quality. Grepsr provides data as a service to enterprises and individuals in a scheduled and clean way. In this blog, we will explore the attributes that form quality data.
Data is king – so goes the old adage. But to be more precise, we say, “High-quality data is the king of all kings.” But how do you set a mediocre dataset apart from its higher-quality counterpart? There are a few primary characteristics of quality data.
Accuracy
The accuracy of any data refers to how correctly it describes the real-world conditions it aims to represent without being misleading. When you base your next course of action on insights from inaccurate data, your efforts will, in almost all cases, not have the desired effects.
Inaccurate information can cause significant problems for an enterprise with severe consequences. Outdated information, typos, and redundancies are some of the constituents of an inaccurate dataset.
Therefore, accuracy is a major characteristic of data quality for sensible decision-making.
Completeness
When there is no variation in the collected dataset compared to an organization’s needs and expectations, the data can be considered complete. Complete datasets are characterized by their lack of empty or incomplete fields.
Without a complete picture of a situation the data describes, it is difficult to perform accurate analyses. Making decisions based on such flawed insights can adversely impact businesses and waste valuable resources. This makes data completeness an important element of high-quality data.
For example, if marketers work with survey data where some people don’t disclose their age, they won’t be able to target the correct demographic, and their efforts will not yield the desired outcomes.

Validity
This is also one of the characteristics of quality data that has a significant impact. Also referred to as data integrity, a dataset’s validity refers to the process of collection rather than the data itself. A dataset is considered valid when data points appear in the correct format, are of the right type, and the values are within range.
Datasets that don’t match the validation criteria are difficult to organize and analyze, and would therefore require extra effort to align with the rest of the database.
In most cases when a dataset is invalid and needs manual fixing, the extraction process and the source are the primary culprits, rather than the data itself.
Consistency
When dealing with multiple datasets or different periodical versions of the same dataset, corresponding data points must be consistent in terms of data type, format, and content. With inconsistent data, teams get different answers for the same question.
The varied formats of postal addresses across the world are an example of inconsistent data that is difficult to standardize. Likewise, if you’re trying to implement cost-reduction programs on a corporate level, inconsistent data could pose various challenges since the data would need to be manually inspected and corrected.
Hence, maintaining consistency is a key attribute for superior data quality.
Timeliness
In a high-quality dataset, the data is collected as soon after the event it represents as possible. With time, every dataset becomes less accurate, reliable, and useful as it becomes a representation of the past and not the current reality. So to get the best possible output from your efforts, the freshness and relevance of your dataset is one of the most important features.
If you base your decision-making on outdated insights, the results are bound to be inaccurate for the present scenario. Your organization would therefore miss out on all the latest trends and business opportunities.
Since quality data lays the groundwork for the best business decisions, a compromise to any of the above attributes could easily derail the course of your organization’s success. Any action taken based on insights from a low-quality dataset will not have the intended results. You should opt for a solution that comprises all the major traits for high-quality data.
Good quality data has lots of short and long-term benefits to not just businesses and industries, but also governments and policymakers. Adapting to the high-quality data characteristics we just mentioned, you can:
- Make more informed decisions
- Improve customer relations
- Promote more effective content and marketing campaigns
- Increase productivity
- Gain competitive advantage
- Enhance profitability
We’ve taken a look at each in detail in another article linked below.

Related reads:


About Grepsr
Grepsr is a data acquisition platform with 10+ years of experience in extracting all kinds of available web data, at scale. If big data fuels your business, we want our data, technology, and expertise to build the foundation for your organization’s continued success. Let Grepsr empower your team with the most reliable, accurate, and actionable web data.
Get in touch today with your requirements, and we’re sure we can work out a solution for you!
FAQs
What are the 5 characteristics of high-quality data?
The five essential characteristics are: accuracy (correctly represents reality), completeness (no missing fields), validity (proper format and type), consistency (uniform across datasets), and timeliness (current and relevant).
What does data accuracy mean?
Data accuracy means the information correctly describes real-world conditions without being misleading. Inaccurate data—caused by outdated information, typos, or redundancies—leads to flawed business decisions and wasted resources.
Why is data completeness important?
Complete data has no empty or incomplete fields, providing a full picture for accurate analysis. Without completeness, businesses make decisions based on partial insights, which can lead to targeting the wrong audience or missing key opportunities.
What is data validity?
Data validity (or data integrity) means data points appear in the correct format, are of the right type, and have values within acceptable ranges. Invalid data is difficult to organize and analyze, often requiring manual correction.
How does data consistency affect business decisions?
Consistent data maintains uniform format, type, and content across multiple datasets. Inconsistent data causes teams to get different answers to the same question, complicating analysis and requiring manual inspection and correction.
What does timeliness mean in data quality?
Timely data is collected as soon after the event as possible and remains current. Outdated data becomes less accurate and useful over time, causing businesses to miss trends, opportunities, and make decisions based on past rather than present conditions.