

The internet is a visual jungle.
From Instagram stories to product thumbnails on Amazon, our attention is constantly hijacked by images. They’re not just decorative — they influence what we buy, who we follow, and how we feel.
Yet, while businesses scramble for keywords and user clicks, there’s a goldmine hiding in plain sight: images.
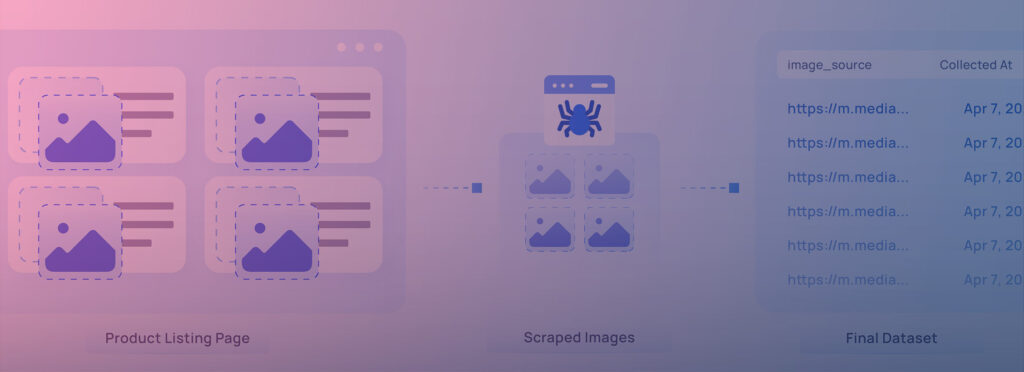
That’s where image scraping comes in — the way of systematically collecting visual data from the web, turning scattered pixels into structured, and actionable insight.

What is image scraping?
Image scraping is the process of collecting public images from websites by writing crawler scripts or using web scraping tools that send requests to the webpage, parse the HTML content, and download the desired image files. They extract the pictures usually from the tags of a page.
Image scraping is essential in multiple industries for competitive reasons. Recently, they have been used in training AI models to recognize and distinguish elements from a huge dataset of labeled images. This way the AI is able to generate unique images following the prompt instructions. Now it is capable of turning normal images into trending art-style images like Studio Ghibli, Pixar Lego, and more.
How is image scraping done?
While there are several tools and techniques available to extract images from websites, we’ll take a look at solutions provided by Grepsr— our very own newly released data extraction tool— Pline.
Pline, powered by Grepsr, is a simple yet powerful instant data scraper tool built for effortless data extraction. It’s a no-code tool that allows users to easily visit any well-structured website and collect data, including text and images.
Before we begin the step-by-step process, let’s first install Pline. This extension is available for free on Chromium browsers, including Google Chrome, via the Chrome Store.
Steps:
1. Visit the website from which you want to collect images, click the Pline Extension, and choose between Automated Data Extraction Mode or Browse and Capture Mode.
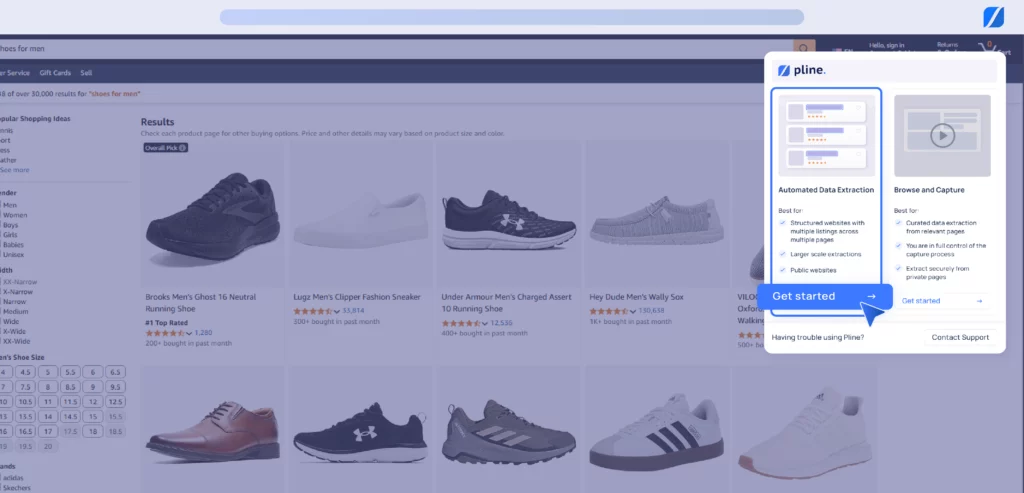
We will use ‘Automated Data Extraction’ Mode for this example, which helps you gather images without manual effort.
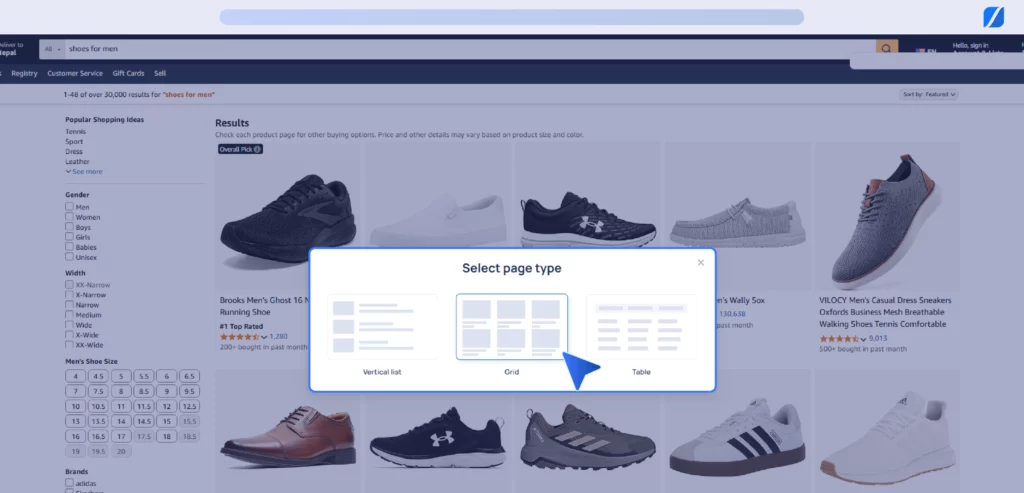
2. Build a Workflow, select the Page Type, and start grouping similar items (Shoe Images ) for Pline to recognize the data to extract.
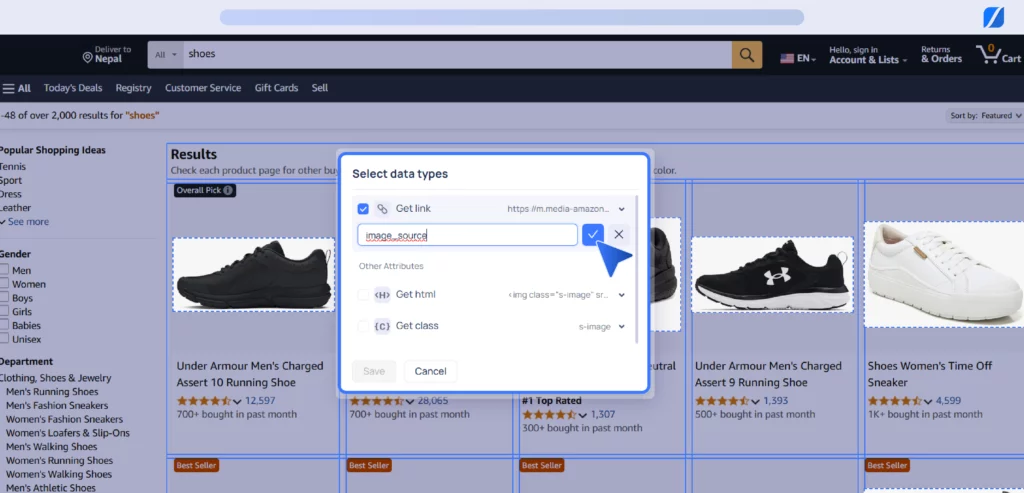
3. To extract images, you must set the data type as ‘Link, ’ provide the appropriate field name, and save it. Then, repeat the process with the proper data types and field names for the remaining data.
4. Once you include all the required data fields, click save and set up the appropriate pagination, and then view sample data.
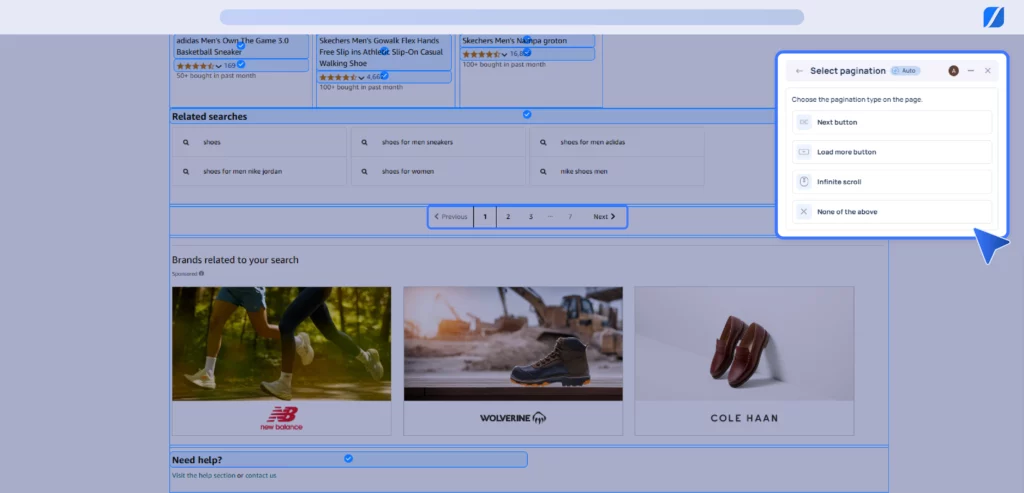
5. Once you are happy with the sample data of scraped images, choose ‘Save and Run’ to run the data extraction immediately. If you want to create the workflow for future purposes, you can select ‘Save Workflow’ to save it and use it later for effortless image data extraction.
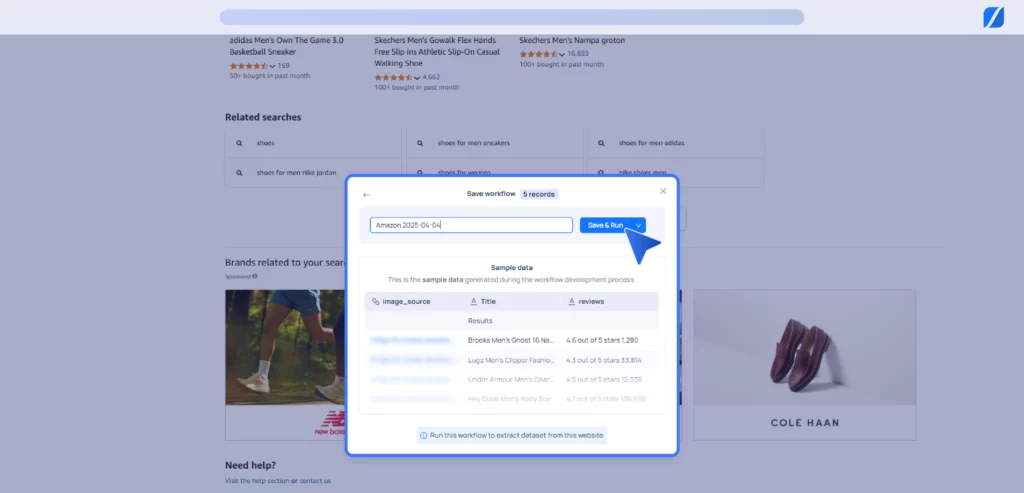
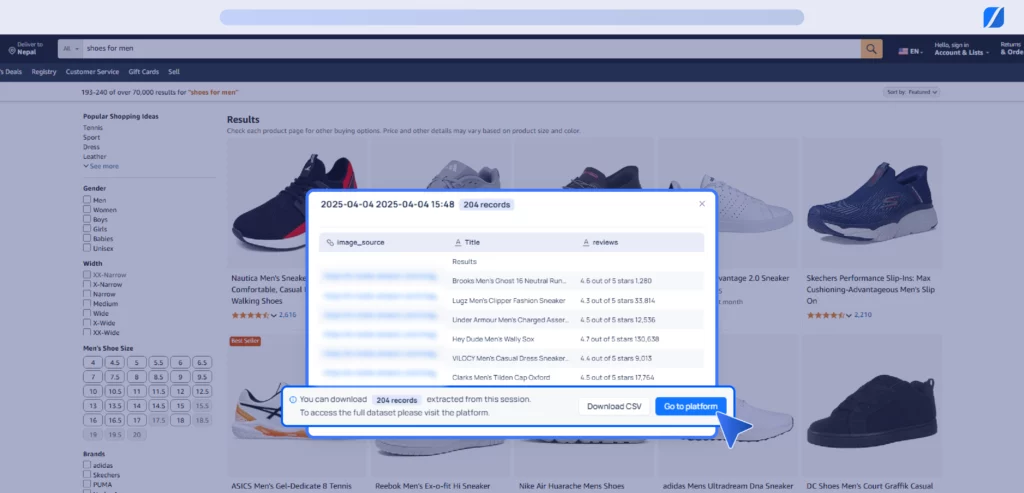
6. After extraction, view the summary of captured image records. Download as CSV or click “Go to platform” for full access and insights.
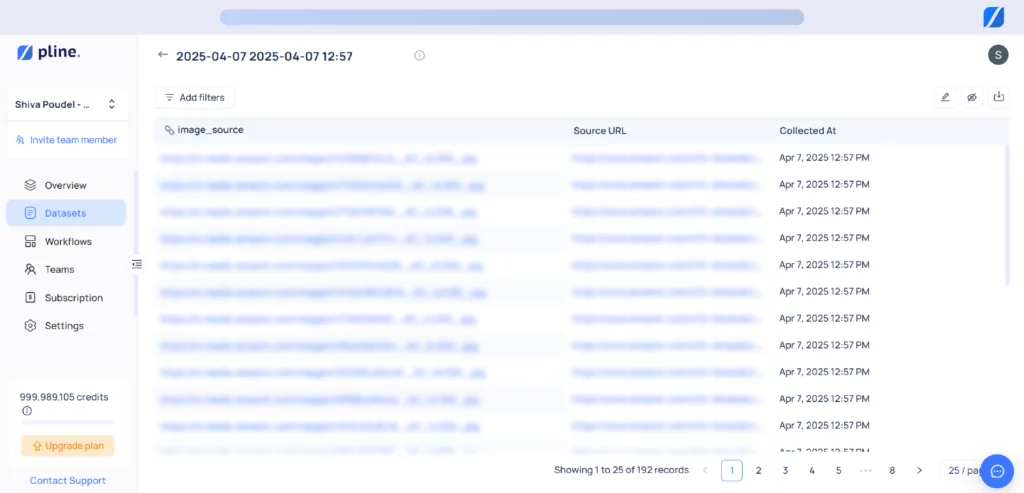
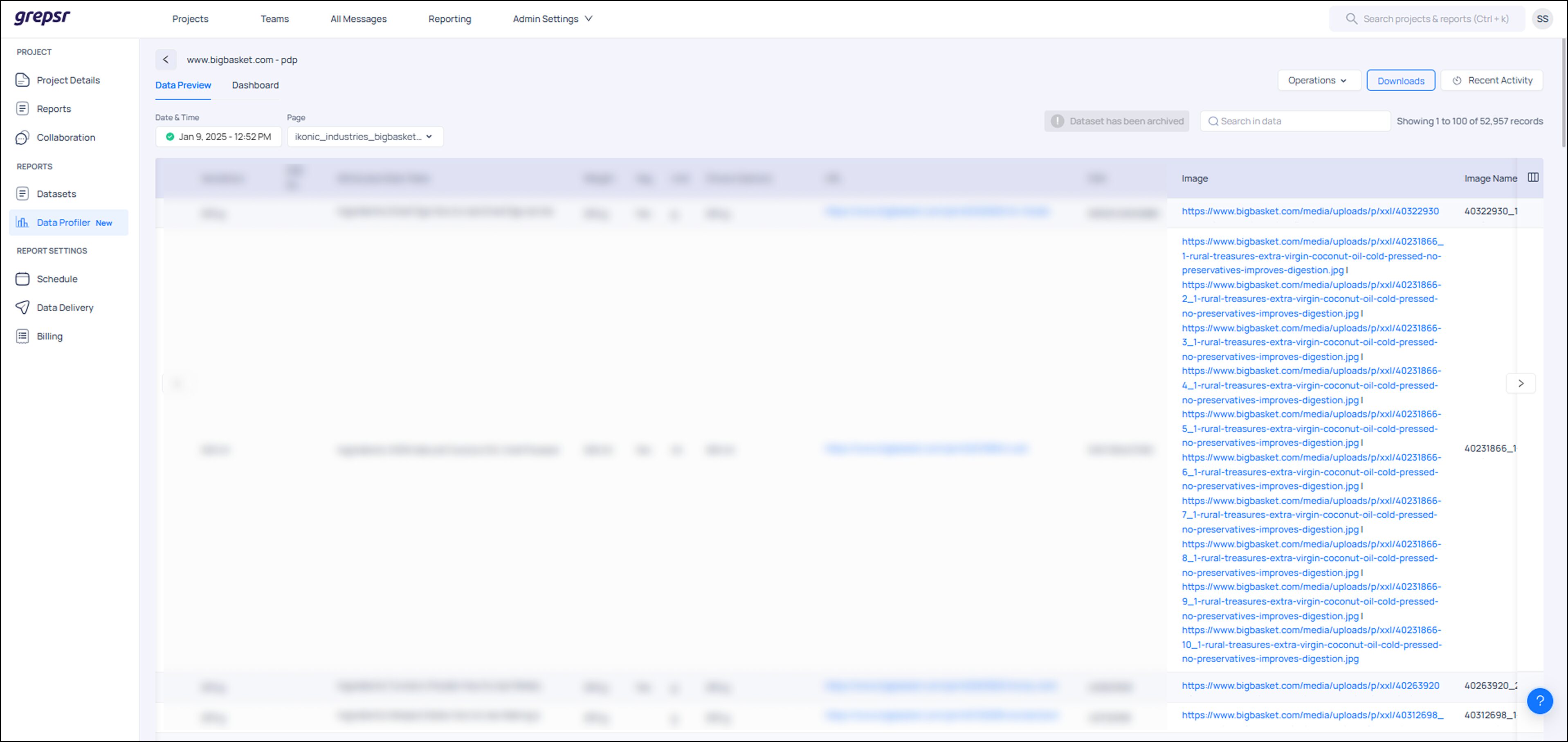
7. The Pline Platform brings together workflows and datasets in a single, organized dashboard. To review your full extraction details and access the final image dataset, navigate to the “Datasets” section on the Pline Platform.
Use cases of image data
E-commerce & Retail – Scrape product images from marketplaces to analyze how competitors present their offerings. Everything from the packaging, angles, background choices, and quality. Then use the data to train visual recognition engines or recommendation systems that suggest similar-looking products.
Market Research & Trend Analysis – Brands scrape fashion, interior design, or food images from social media, blogs, or e-commerce sites (especially from Pinterest, Instagram, and TikTok) to spot visual trends. Then analyze how consumer preferences evolve over time.
Training AI & Machine Learning Models – High-quality datasets are the building blocks of AI and machine learning. Training such models with large volumes of labeled images fuels facial recognition, object detection, and image classification projects.
Real Estate & Travel Platforms – Property & hotel images are collected across platforms like Airbnb, Zillow, or Booking.com to identify high-quality images that get more clicks, views, and bookings.
Developing SEO Strategies – In addition to the image itself, businesses can extract Alt text, captions, tags, image dimensions, and timestamps for each image. This added context enhances visual search, accessibility, and SEO performance.
Grepsr for image data extraction at scale
For a niche data extraction requirement like image scraping, enterprises need more than flexibility — they need efficiency, accuracy, and reliability at scale.
Whether it’s sourcing product visuals across marketplaces, building image datasets for AI, or tracking visual trends across regions. The process calls for robust infrastructure and deep technical experience.
That’s where Grepsr stands out. With over a decade of experience providing data solutions for global enterprises, we go beyond general-purpose web scraping tools like Pline to offer a fully managed, enterprise-grade data extraction service.
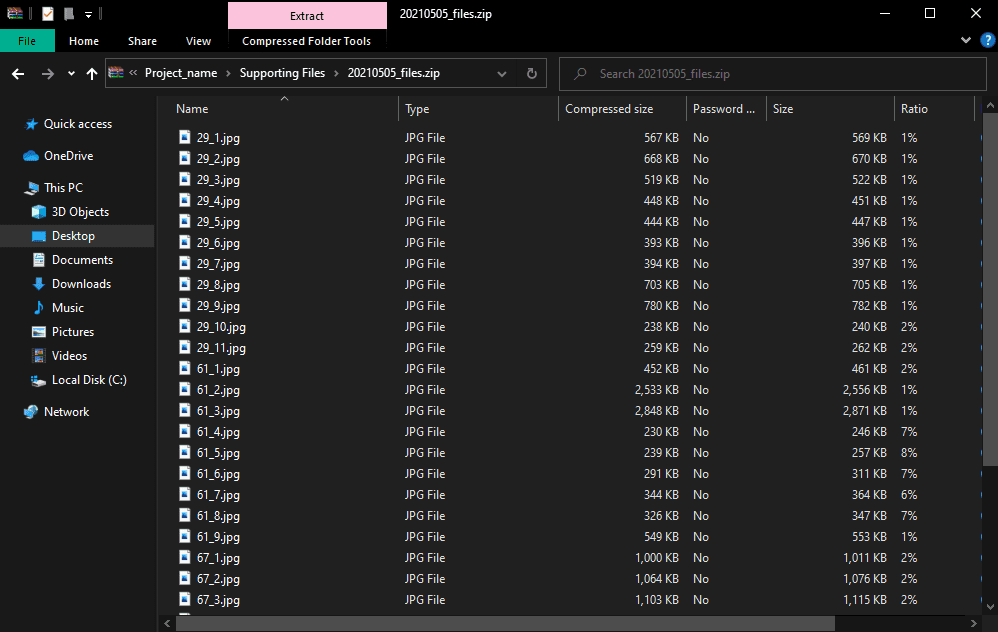
Grepsr’s web scraping service is perfect for bulk image extraction requirements. Such as multiple image URLs for the same item, extracting images as JPG or PNG files, compressing them into zip files, applying a certain file naming format, and so on.
Ready to turn visual content into actionable data?
Talk to our team and see how Grepsr can help you scale image scraping effortlessly!
FAQs
What is image scraping?
Image scraping is the automated process of extracting images from websites using tools that parse HTML and download image files from <img> tags.
How does image scraping work?
- Send requests to the target webpage
- Parse HTML to find image elements
- Extract image URLs
- Download and save images
No-code tools like Pline automate this with point-and-click selection.
What are the main uses of image scraping?
- E-commerce: Analyze competitor product photos
- AI Training: Build datasets for object detection and image recognition
- Market Research: Track visual trends from social media
- Real Estate: Compare property images across platforms
- SEO: Extract alt text and metadata for better search performance
When should I use a managed service instead of a tool?
Use managed services like Grepsr for:
- Large-scale, ongoing extraction
- Custom file formats and naming
- Complex or anti-scraping protected sites
- Enterprise-grade reliability and support
Is image scraping legal?
Generally, yes for publicly accessible images, but you must respect copyright, terms of service, and robots.txt files. However, avoid unauthorized commercial use.
Related reads:






























































































































































