An unconventional format — PDF, XML or JSON — is just as important a data source as a web page.
Grepsr has been one of the major players in the web scraping game for more than ten years. As a DaaS platform, we extract data from both simple and complex sources while maintaining the highest quality standards every time.
For the data extraction projects that we receive, web pages are the most common data sources. Occasionally, however, we also receive requests from some customers who want their data from offline and unconventional sources such as PDF files, XML and JSON.
Here we take a look at how we collect data from these non-traditional data sources and formats.
PDF files
PDF stands for Portable Document Format. Originally developed by Adobe, they are one of the most popular digital alternatives to paperback documents.
PDF files are one of the most common mediums across organizations to both store documents and communicate information. Their compatibility across multiple devices allows not only easy portability of documents — as their name suggests — but also easy viewing and storage. Whether the content is textual, graphical or scanned, you can save any information in a single place for easy viewing and reading with PDF documents.
Benefits of using a PDF file format
PDF files are extremely useful and efficient, offering a wide range of benefits, some of which include:
- Usability and integrity across multiple devices
- Easy readability and convenient format
- Ability to contain a variety of content — including text, images and even scanned paperback documents
- Protected layout which can preserve watermarks, signatures and other important content

Data collection from PDF files
Unlike other forms of documentations like Word and Excel files, PDF files do not allow easy editing — creating further hassle when it comes to data extraction. Because the original goal of having a PDF file is to have a protected layout, data scraping from them is quite tricky. If not done properly, it can result in extremely unstructured data which restricts the very objective of data extraction — effective analysis. After all, you do not want to end up with unclear, incomplete and incoherent data which will only negate the purpose of having quality data to play with.
Here’s how Grepsr handles PDF data extraction
- When we receive a PDF scraping request, we firstly analyze the document’s formatting and the degree of complexity for data extraction.
- We export the file as a text-friendly format, like a Word document.
- When exported, the document adds a line break at the end of each line. While these new lines are not visually evident, they add a level of difficulty to the scraper when it parses the document.
To combat this, we identify and remove every new line via regular expressions (RegEx), leaving paragraph and section breaks as they are.
- When exported, the document adds a line break at the end of each line. While these new lines are not visually evident, they add a level of difficulty to the scraper when it parses the document.
- Depending on the structure, we then extract data fields as requested.
- Some document layouts (columns, for example) pose an additional challenge. When the data we need is on one of the rows in the first column, parts of the same row on the other columns are also collected with a number of whitespace characters in between (like a tab — 4–5 characters).
In such cases, we split the collected string with the whitespace as the separator and collect the resulting data as arrays. Then each individual string is mapped to its parent field based on the array index. - Similarly, if a PDF contains a long list of information about something like products, the extraction would require more complex and powerful scrapers. This would entail more resources in terms of RAM and storage to cater to the additional memory demands.
- Some document layouts (columns, for example) pose an additional challenge. When the data we need is on one of the rows in the first column, parts of the same row on the other columns are also collected with a number of whitespace characters in between (like a tab — 4–5 characters).
Data parsing from XML sources
XML stands for eXtensible Markup Language. It defines a set of rules that makes a document both human and machine-readable.
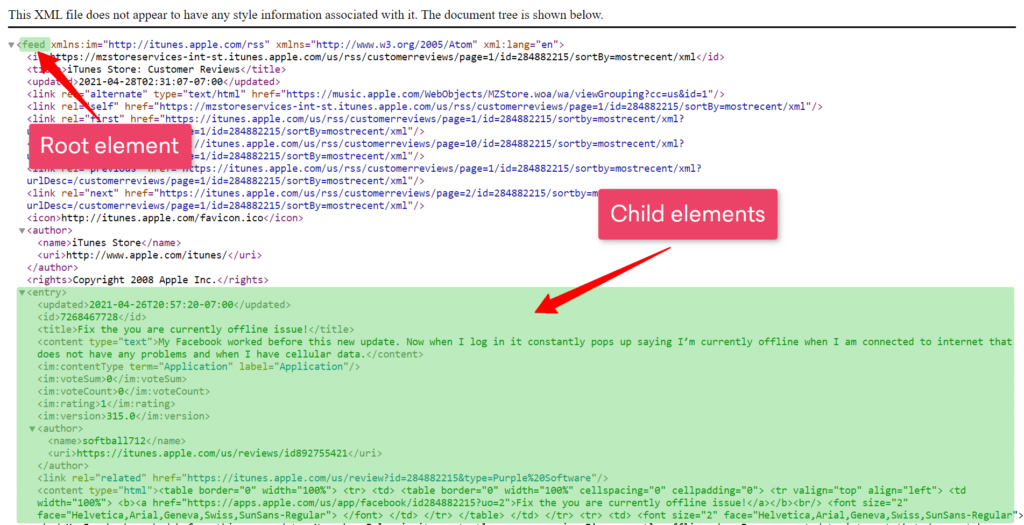
In XML files, data is stored as element trees, with a root (or parent) element which branches into child elements, as shown in the image below. These elements are then extracted based on what is requested.
Additionally, in some of our use cases, the XML files contain sitemaps for websites that contain links to their listings, like products. Once we’ve listed the product URLs, the subsequent extraction process is similar to when we’re collecting any other web data.
However, it isn’t always as simple as that. Categories and sub-categories are sometimes poorly structured in some sitemaps. This adds an additional layer of complexity to an already difficult data extraction source.
Parsing data from JSON format
JSON — JavaScript Object Notation — is a lightweight format for storing and transporting data. It is often used when data is sent from a server to a web page.
Since JSON files contain data in the form of name-value pairs, the information is easy not only for humans to read and write, but also for machines to parse and generate. As a text format that is completely language independent, JSON is the ideal data-interchange format.

Like XML files, data in JSON is structured in parent and child elements, which makes data collection convenient. In most websites, details visible on-screen are most often embedded as JSON in the web page’s JavaScript file. By analyzing the website’s source code, it is possible to determine the JSON resource, extract the required data, and structure and organize them into their respective data fields as requested.
Also read:

As more organizations opt for various methods to store their information, we do not want any enterprise missing out on fulfilling their objectives just because the data they seek is stored in an unconventional format. No one should be losing out on incoming revenue because of not being able to extract data in a structured and editable format.
With Grepsr’s Concierge platform, you can just tell us your requirements and we will extract the data you need from both traditional and non-traditional sources. Visit our website for more information and contact us with your project requirements. Then sit back and relax as we automate the entire data extraction process for you.