Never let bad data hurt your brand reputation again — get Grepsr’s expertise to ensure the highest data quality

The price businesses pay every year owing to poor data quality is staggering, to say the least. A research carried out by Gartner estimated that “the average financial impact of poor data quality on organizations is $15 million per year.” Just in the US alone, IBM discovered that businesses suffer a massive loss of $3.1 trillion in revenue annually because of poor data quality.
The devil lies in the details
As the old adage — “The devil lies in the details” — puts so fittingly, the corruption of data occurs at a very fundamental level.
To put this into perspective, we can consider a piece of typical information set containing people’s names, email addresses, physical addresses, social security numbers, and so on. If the dataset is not updated regularly, certain facts about the person may alter significantly over time. For example, if he/she chooses to move from one place to another. Just a few wrong data entries can complicate matters further. In case a vigorous checking mechanism is not put into place, the repercussions of some poor data may grow into an unrestrained juggernaut capable of disrupting supply chains, and destroying the brand image to dust!
“Bad data is no better than no data.”
Mel Netzhammer, Washington State University
In comes the 1:10:100 rule
George Labovitz and Yu Sang Chang proposed the 1:10:100 rule in 1992 that painted a clear picture of the negative impact poor data has on your business. It leaves a word of caution to the decision-makers out there saying “The longer you take to fix your data, the higher your losses will be!”
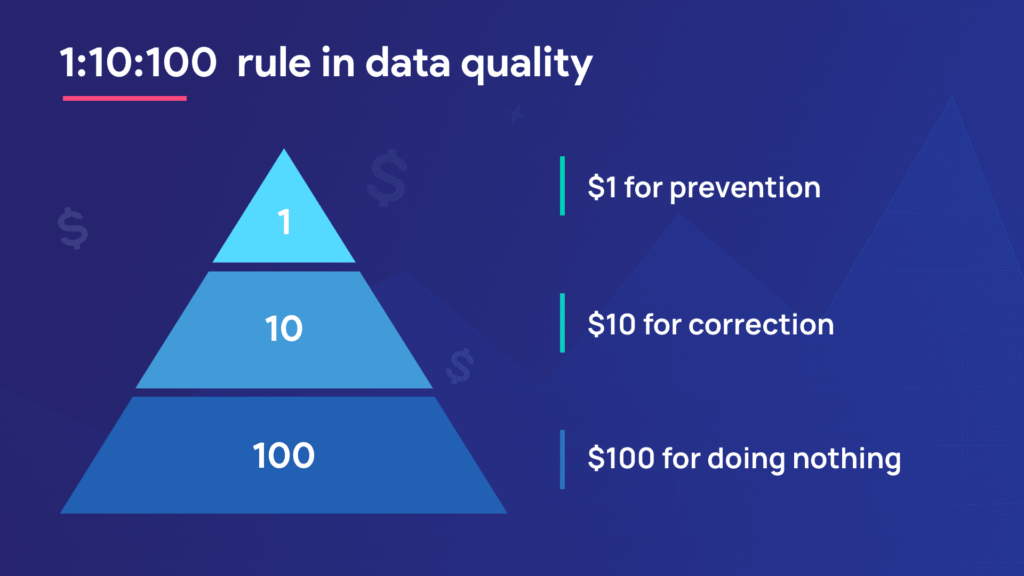
$1 for prevention
This way of dealing with faulty data takes the problem head-on. The errors are immediately dealt with so they can create no more nuisance.
$10 for correction
Mel Netzhammer, the second chancellor of Washington State University, Vancouver was not kidding when he stated that “Bad data is no better than no data.” Furthermore, when this bad data goes out to be used to deliver tangible results, it has a way of adding several more layers of corruption to the whole process.
According to the 1:10:100 rule, when you rectify your data after getting feedback, you lose $10 for every $1 due to your reactive approach to data quality.
$100 for doing nothing
You didn’t take the problem head-on, and neither did you take the time to listen to feedback. What’s worse? You plan on doing nothing about it and let fate do your bidding. This is when you lose $100. Considering the ripple effect failure has, especially more so in this industry, the negative impacts go a long way. Bad data is equivalent to bad brand rep which leads to low ROI and whatnot!
To summarize
The 1:10:100 rule is not a tool to rectify bad data but rather a way of understanding the negative impacts bad data has on your business. It takes into account the butterfly effect of one misleading data that can multiply many folds over time. The immediate result can be something as simple as customers getting irritated, or the staff having to work overtime for a pointless reason. In the long term, it can lead to detrimental customer reviews and bad brand reputation. And, if not checked in time, can even pave the way for the undoing of the company.
Nipping bad data in the bud!
The QA team at Grepsr runs quality tests every day on millions of records to ensure the data’s integrity. Our automated systems fix the errors at the source, stopping future blunders in its track! We make sure bad data never sees the light of day here, so you can focus on other important matters. Hence, leave the worrying part about the quality of your data to us!
Read about the QA protocols at Grepsr here:

Related reads: