Most businesses (and people) today more or less understand the implications of data on their business.
ERP systems enable companies to crunch their internal data and make decisions accordingly.
Which would have been enough by and itself if the creation of web data did not rise exponentially as we speak. Some sources estimate it to be 328.77 million terabytes of data every day!
And, your business operated in a vacuum, of course.
Web scraping is the process of extracting data from the web to monitor various events that can impact your business.
If you run a logistics business, scraping climate data can help you make informed decisions. Think of information on upcoming hurricanes and storms from the news.
Some businesses generate most of their sales online. If you fall in that segment, collecting and monitoring social media data enables you to gauge customer sentiment.
For its part, Grepsr specializes in managed data acquisition from the web.
With over a decade of experience in the field we come with proven expertise to solve the most pesky data extraction use cases and enable businesses to ingest high-volume data in byte-sized pieces.
Read about data extraction with PHP here:

Data extraction with Python
In one of our older articles, we explained how you can build your own crawler and scrape the web using PHP.
This time, we will focus on data extraction with Python.
Python, much like PHP, is a programming language used worldwide for a variety of applications.
From simple scripting purposes to generating complex language models for artificial intelligence and machine learning (like ChatGPT and various other LLMs), developers often turn to Python for its simplicity.
Its syntax is easy to learn, beginner friendly and a robust community of plugins and libraries has helped it encroach every task relating to computers.
Web scraping is no different. We can most certainly carry out data extraction with Python.
In this lesson we will use Python to write a crawler to scrape IMDB’s top 250 movies and preserve the data in a CSV file.
We have divided this article into the following sections for effective navigation:
- Prerequisites
- Definitions
- Setup
- Writing the scraper
- Final words

Prerequisites to start web scraping with Python
Similar to the PHP article, before getting started, we will need certain tools and basic knowledge about a few terms. We will then set up a project directory, and install different packages and libraries that are of use in this project.
Since Python is a “Jack of all trades” language, all of its feature set is available on almost every platform.
After that, we will go through each line of the Python code and reflect on what it does and why it does that. At the end of this tutorial, you will have learned the basics of Python programming, at least when it comes to web scraping. You will generate a CSV file that you can use for data analysis and data processing.
Basics on Python
Libraries
These are pre-packaged python programs that are designed to carry out a small operation or function. You can find them distributed over the internet under a license, free of cost or with a proprietary right.
Package manager
The Package Managers help manage the libraries we use inside our Python program.
Bear in mind that recklessly installing Python packages by replacing or completely overriding current install can potentially bork your system, which is why we use a concept called ‘environment’.
Here are a few package managers you can use: pip, conda, pipenv, etc. You can also use OS package managers to install Python packages.
Environment
Most modern operating systems use Python in their core processes and applications. Uncontrolled installation of different packages can break one’s system and prevent it from booting or performing routine tasks.
To prevent this from happening we use a containerization logic known as environment. An environment is a sandbox container in a computer system where new versions of a particular file (or files) can be installed. The environment does not communicate with the installation but fulfills the requirements of a certain program.
Simply put, the environment is similar to a virtual machine. To prevent our system from disintegrating, we create a virtual machine and execute our program by installing packages to this virtual machine instead.
This way, the new packages cannot override the system, and the application gets all the packages it needs. Conda, venv, and pipenv are some examples of environment managers for Python.
Sandbox
We use the concept of sandboxing when we want to run an application without interference from other systems. It is a security measure, and we use it during Python programming to boost the security of our application. Which also helps in solidifying the overall security of our system.
Lxml
We use Lxml to parse HTML documents and generate a DOM of the HTML document. Creating a DOM is a matter of convenience. It helps us to search for the data we want.
Pandas
Pandas is another Python library used extensively in data science and data processing. It comes in handy when processing large rows of data and obtaining actionable insights. We will use this library to generate a CSV of the data we scrape from IMDB.
JSON
It enables our program to search through the HTML DOM using CSS selectors. They are an extension to the LXML library. You can use these together to quickly generate a searchable HTML DOM using CSS Selector.
Project setup for data extraction with Python
We create a directory where we house our main program and also the final output CSV file. To create a project directory we simply use our operating system to create a new folder and open a text editor in it. For this tutorial, we will be using Visual Studio Code from Microsoft.
Once this is done, we will install an environment manager to prevent new packages from interfering with our system.
Open the terminal in our text editor and type in the following:
pip install pipenv
This installs the environment manager called pipenv. We could have used conda and others but their setup is a bit more hasslesome compared to pipenv.
Now create a new file named requirements.txt.
We write down the name of the packages we are to install in this file. The contents of requirements.txt file will be:
pandasrequestsLxmlCssselect
Once this step is completed, write down the following command to install all of these in one go.
pipenv install -r requirements.txt
This command reads the requirements.txt file and installs each of the libraries after creating a Python environment with the same name as the folder. We generate two new files: Pipfile and Pipfile.lock.
This signals that our packages are installed and we are ready for the next step.
Now we need our program to know that we want to use the packages installed in the new environment rather than from the system so we run the following command to set the executable location.
pipenv shell
Now create a new file named imdb.py to finally start writing the program.
Writing the crawler in Python
Unlike the PHP crawler our scraping technique will be a bit different this time. Rather than stopping at the first 250 pages, we will go one step further and extract the movie summary for each of the listed 250 movies.
So our column names for this scraping session will be: Title, Rating, and Summary.
We want to extract IMDB’s top 250 movies of all time from this page. Please read our previous blog “How to Perform Web Scraping with PHP” to learn about the detailed structure of this page.
Here, we will only focus on the next page from where we are to extract the summary text for each of the 250 movies.
Once we click on one of the movie, we can see we reach a web page similar to this one:
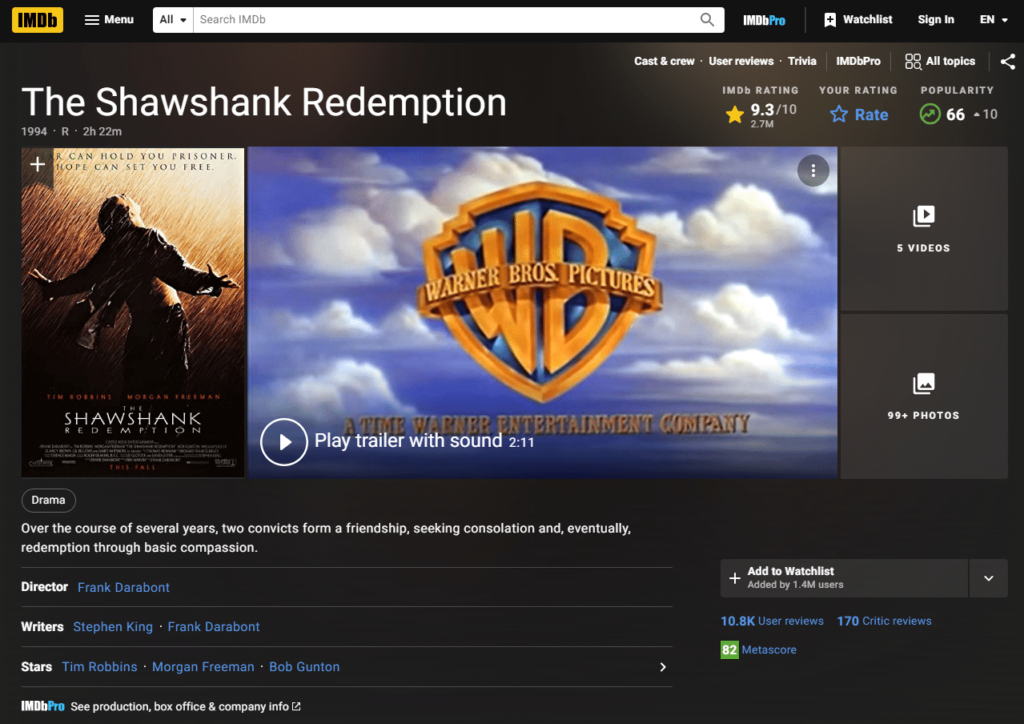
Here we can see our required summary lies at the bottom part of our webpage. Inspecting it through our developer console tool, we can see the exact CSS tag the summary exists in.
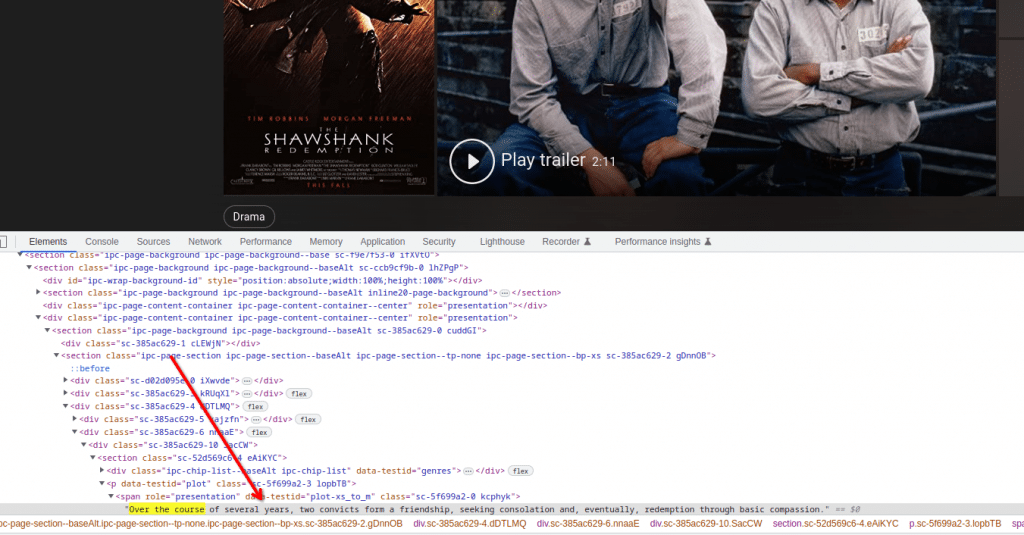
We can directly use this information during our scraping, but let us find out if there is an easier method of dealing with this information. Let’s search for the summary text for this movie in the page source.

Moreover, we find out that the summary text is being pulled from a script tag which contains data in a JSON format. It is a more desirable format because JSON will always have its content in a more expected format unlike HTML body which can change as the web page is updated.
Therefore, it’s best to extract the data from the JSON object. Once you get an idea of the scraper’s workflow, you can begin writing it.
Begin the python script by importing all the installed packages using the keyword import similar to:
import pandas as pd
import requests as re
import lxml.html as ext
import jsonTo start scraping, we define a header variable which contains all the required headers for the website.
The headers are important since they determine the format of handshakes the source website and our code will have, so that a smooth data transfer between the two agents can occur.
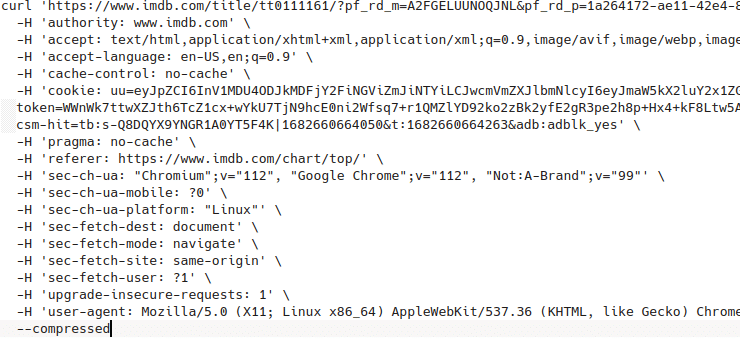
Resultantly, we can pull the respective headers from the developer console’s Network tab. Just search for your desired page and right click on the web page, then click and copy as cURL.
Paste the contents on another file temporarily to check all the headers.
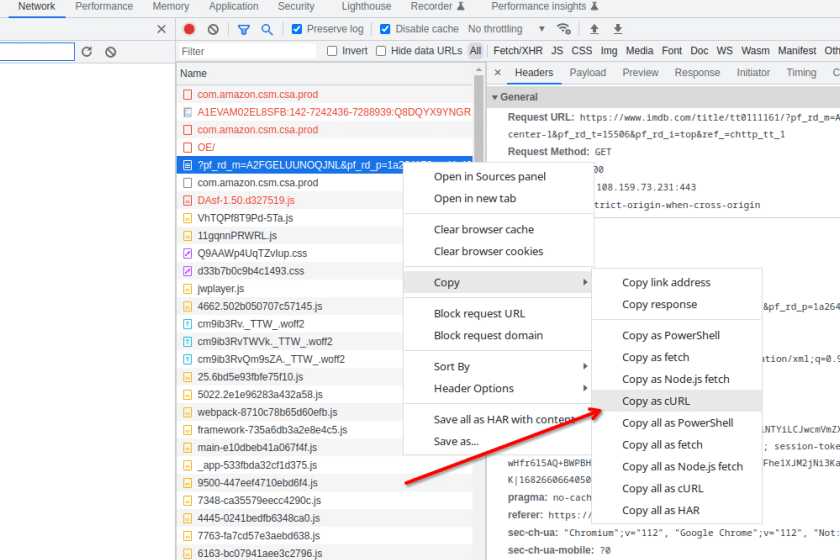
cURL headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.51',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'en-US,en;q=0.9'
}
With this defined, we use the requests library to send a get request to the website of IMDB containing the top 250 movies.
response = re.get(‘https://www.imdb.com/chart/top/?ref_=nv_mp_mv250’, headers=headers)It will put the response content body in the response variable. Now we will need to generate an HTML DOM document of the respective response so that we can easily use lxml and cssselect to search for our required data. Additionally, we can do that with the following line of code:
tree = ext.fromstring(response.text)
movies = [ext.tostring(x) for x in tree.cssselect('table[data-caller-name="chart-top250movie"] > tbody > tr')]Once this is done, all the information we need about the 250 movies is stored in the movies variable as a list. Now, it is only a matter of iterating over this variable to go further inside each movie’s web page and getting the summary. You can do that with the code block below:
url = 'https://www.imdb.com{}'.format(tree.cssselect('a')[1].get('href'))
response = req.get(url, headers=headers)Consequently, it will receive a web page that contains the movie summary for our movies. Now, as mentioned before, we will need to extract the JSON object from the script tag in this new web page. We can do that by using the JSON library as shown below:
script = json.loads(tree.cssselect('script[type="application/ld+json"]')[0].text_content())Further, this new script variable contains the JSON object from the website. Place the information in a neat array and you will get an appropriate row data for one movie. Do it this way:
row = {
'Title': script['name'],
'Rating': rating,
'Summary': script['description']
}Iterating this process over 250 times will get us our required data. However, without storing this data somewhere intermediary we can’t use the data for further processing and analysis, which is where our pandas library comes in.
During each iteration we store the row information in a dataframe row of our pandas object using the following code:
all_data = pd.concat([all_data, pd.DataFrame([row])], ignore_index=True)After the iterations are complete, we can export the pandas object to a CSV to send the data for downstream analysis.
Following is the entirety of the Python code:
import pandas as pd
import requests as req
import lxml.html as ext
import json
url = 'https://www.imdb.com/chart/top/?ref_=nv_mp_mv250'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.51',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'en-US,en;q=0.9'
}
response = req.get(url, headers=headers)
tree = ext.fromstring(response.text)
movies = [ext.tostring(x) for x in tree.cssselect('table[data-caller-name="chart-top250movie"] > tbody > tr')]
all_data = pd.DataFrame()
for idx, movie in enumerate(movies):
print('Processing {}'.format(idx))
tree = ext.fromstring(movie)
url = 'https://www.imdb.com{}'.format(tree.cssselect('a')[1].get('href'))
rating = tree.cssselect('td.ratingColumn.imdbRating strong')[0].text_content()
response = req.get(url, headers=headers)
tree = ext.fromstring(response.text)
script = json.loads(tree.cssselect('script[type="application/ld+json"]')[0].text_content())
row = {
'Title': script['name'],
'Rating': rating,
'Summary': script['description']
}
all_data = pd.concat([all_data, pd.DataFrame([row])], ignore_index=True)
all_data.to_csv('final_data.csv', index = False)
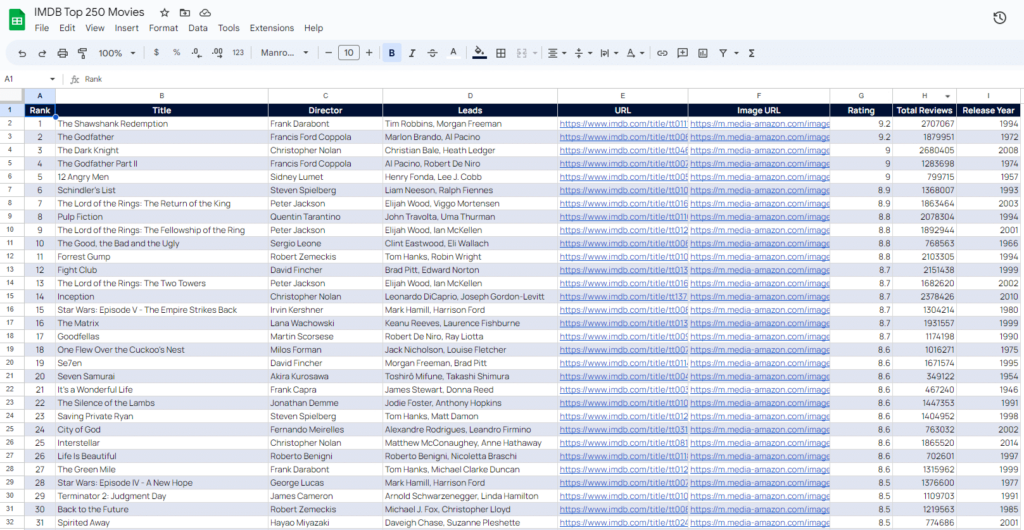
Use the following dataset as you see fit. Binge-watch over the weekend, maybe?
Final words
In Python, we enter each movies page and extract the summaries of the movies.
Unlink in PHP, we didn’t have to define headers in our code. Mainly because the internal page this time was a lot more trickier and further shelled by the web server.
In this article we used the basic of methods to access the data without causing needless errors.
Today, most websites on the internet have strict anti-bot measures in place. For any serious and long term data extraction projects, simple bypasses like these fail to work.
Therefore, companies relying on large-scale data extraction projects on a recurring frequency choose Grepsr for their needs.
Related reads: