Big Data has become an internet buzz lately. Not a day goes by without a mention of Big Data in many articles published by media or tech companies around the world.

But what exactly is Big Data? Why is Big Data a valuable asset for many businesses? And, how important is web crawling in the field of Big Data? This post will deal with these topics.
Big Data is a term used to describe enormous volumes of data generated by interaction of businesses, government agencies and individuals across private and public networks such as the Internet. It includes data from many sources such as surveys, web pages, social networks, search engines and mobile devices. Some of world’s most thriving companies owe their success, in part, to their ability to scrutinize this massive amount of information and use it to their advantage.
Fortune 500 companies like Google and Facebook have been leveraging Big Data to identify opportunities, enhance customer experiences, and maximize profits. Take Google for example. Google has been collecting massive volume of data by crawling billions of web pages from all around the world. Using this huge amount of data in combination with other data they gather from their search engine queries, they have been able to increase the effectiveness of Google Adwords, and also increase the search experience of their users at the same time. By continuing to do so, Google have been generating more profits for themselves and their Adwords customers, and also keeping their search users happy.
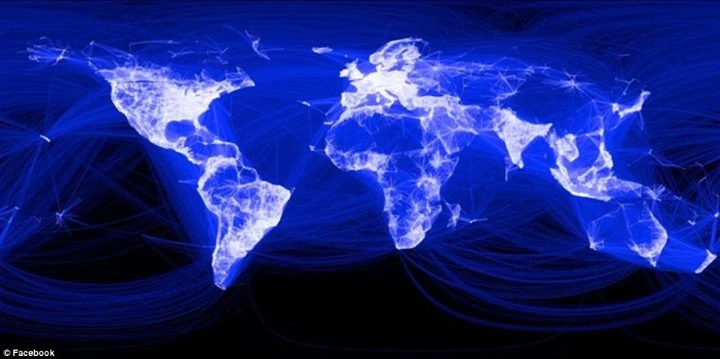
Similarly, Facebook and LinkedIn have also been doing significantly well by leveraging the massive amount of information they collect. Facebook and LinkedIn advertisements have become more effective than before. They now have so much data about their users that they can easily target advertisements and recommend products to potential buyers. Moreover, Big Data can also be used to present your data visually. Facebook in December 2010, showcased a map (as shown below) of how people are connected via Facebook around the world. This kind of data visualization makes your users or customers more attached to your product and thereby making your product more successful.
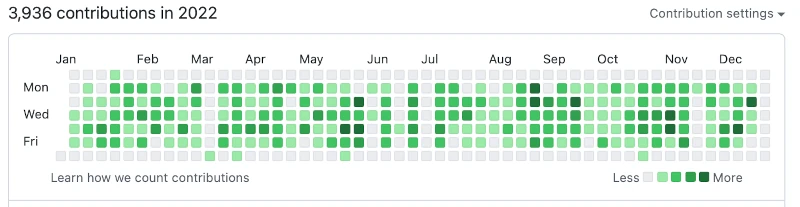
Likewise, GitHub, an online code hosting and collaboration platform for developers, has a feature that visually presents data to you and lets you know when your developers are more productive as shown in the picture below.
To build a massive data-driven business of this scale requires lots of time, effort and money. Even to start a small data-driven startup product is not easy. One of the reasons why it is difficult to build a data-driven product is primarily due to significant amount of data that you have to collect before you can launch your product. Most of the data you collect come from the following sources:
- Direct User Input (survey, search form, etc.)
- Third Party APIs (Twitter, Facebook, etc)
- Server Logs (logs from web servers like Apache and Nginx)
- Web Crawling or Scraping
And, of all the above sources, most data-driven companies crawl web pages to collect data because most of the data that these companies need are in the form of web page with no API access. However, crawling web pages is also not an easy task.
Web is a sea of information with billions of web pages created every single day. Most of the data these web pages contain are unstructured and messy. Collecting and organizing these messy data is not easy. While creating any data-driven product, you will be spending almost 90% of your time collecting, cleaning and filtering data. And, when it comes to crawling web pages, you have to have good programming and database skills.None of the data in the web pages are conveniently handed to you. Sometimes, scraping web pages gets even worse when you have to scrape data from difficult source such as a PDF file. But, ultimately you will even have to scrape data from these sources to benefit your business.
Many companies these days hire skilled programmers and data scientists for data extraction and analytics purposes which cost them huge sum of money.But, with the advent of online data crawling services like Grepsr, data acquisition has become a breeze. No longer do you have to spend time and money crawling web pages and hiring skilled data scientists. All you have to do is hand your extraction tasks over, and what you get back is a nice organized structured data in XLSX, CSV or XML file formats that you can easily use for your business the way you want.
Final thoughts
In coming years, we will be hearing lots of news about Big Data and new data-driven startup companies. Companies with better understanding of Big Data will be able to provide better experience to their customers, find potential customers and generate more profits.
The importance of web scraping cannot be underestimated, so much so that web crawling is already a significant part of building most data-driven products. It requires lots of time, effort and money. By choosing to use an online data crawling service like Grepsr, you can save your time and money.