

We humans are on our way to producing 175 zettabytes of digital information in 2025: that’s enough data to stream every movie ever produced hundreds of millions of times.
Raw bits, however, don’t teach machines much on their own. The knowledge that powers autonomous, decision-making AI agents have to be collected, cleaned, and structured before a model can reason over it.
That job falls to web scraping: the quietly industrious layer of bots and pipelines that copy public web pages, product listings, social posts, research papers, and every other shard of open-web text into machine-friendly form.
Let’s understand how web scraping collects and supplies the data behind the scenes that power the AI systems we use every day.
TL;DR
- In this article, we trace how web scraping gathers, cleans, and de-duplicates billions of pages so AI agents always work with fresh, structured knowledge.
- You’ll see how pipelines embed text into vectors, build knowledge graphs, and feed retrieval-augmented generation for accurate, real-time decisions.
- We explain why clean, well-labeled data is the critical bottleneck, and how X removes it by delivering export-ready JSON, Excel, or CSV.
How Web Scraping Feeds the Brains of AI Agents
AI agents differ from traditional ML models because they act. They perceive the outside world, decide, and execute tasks with minimal human oversight. To do that well, they need a continuous feed of structured, real-time knowledge, which is exactly what large-scale web scraping delivers.
- Fresh context on demand: Agents that book travel, monitor competitors, or find breaking news can’t rely on a model snapshot frozen a year ago. Scrapers pull the latest fares, filings, and headlines, pipe them through lightweight parsers, and hand the agent up-to-the-minute facts it can reason over.
- Breadth across domains: Open-web crawls reach governmental PDFs, GitHub repos, support forums, and SaaS changelogs in a single pass. This diversity lets a planning agent cross-reference regulations, code examples, and user feedback in one reasoning chain.
- Fine-grained signals for specialized tasks: Sentiment, price, schema, and microformat data scraped from e-commerce pages or social feeds give agents the structured vectors they need for ranking, summarization, or anomaly detection.
- Self-healing knowledge graphs: As pages change and links rot, scrapers recrawl, diff, and update entity relationships. Agents consume those deltas to avoid hallucinating on stale data.
How Does Web Scraping Sync With AI Agents (Behind the scenes)
Behind the scenes, a typical pipeline looks like this:
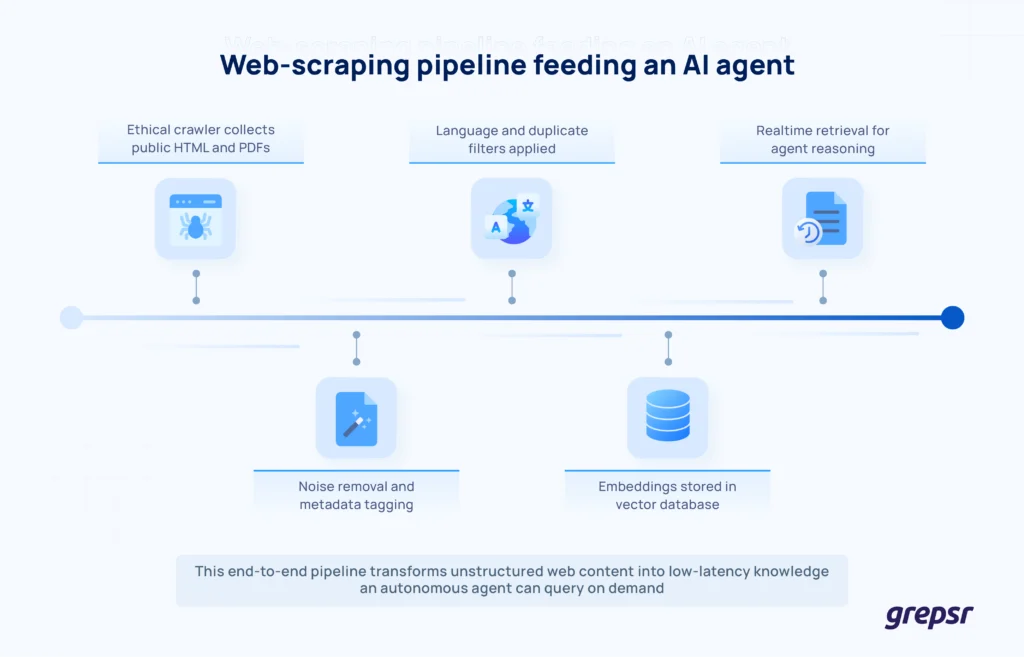
- Collection: Headless browsers or polite HTTP clients fetch HTML, PDFs, and JSON feeds.
- Parsing and normalization: CSS selectors, XPath, and ML-based content extractors strip boilerplate and leave clean text plus metadata.
- Filtering and quality checks: Language ID, duplicate detection, and profanity filters keep the corpus usable.
- Vectorization and storage:Tokenizers convert text to embeddings or chunked documents in a vector DB or object store.
- Streaming to agents: Retrieval APIs deliver context windows, RAG documents, or feature tensors to the agent at inference time.
Why does this matter now?
A 2025 IDC survey found that four out of five enterprises view AI agents as the “new enterprise apps,” and more than 20% already embed fully autonomous agents in their software portfolio. Those agents thrive, or fail, based on the freshness and scope of the data we feed them.
Web scraping, once a back-office script, has moved to the critical path of AI product engineering. Without it, even the smartest agent becomes a sophist, arguing confidently from outdated premises.
How Raw Data Turns to AI-ready Knowledge
Even the cleanest website hides a tangle of <div> mess, duplicate boilerplate, and out-of-date snippets. A modern scraping stack turns that into something an AI agent can actually reason with. Here’s how it pans out:
Step 1: Headless browsers rotate IPs and respect robots.txt while harvesting terabytes from news sites, docs, APIs, and PDFs. Common Crawl alone captures 3 to 5 billion new pages every month and keeps a 250-billion-page public corpus current for researchers and builders
Step 2: Content extractors (trafilatura, Readability clones, GROBID for scientific PDFs) remove navigation bars, ads, and footers and leave clean main text with just time stamps, author names, and canonical URLs.
Step 3: Language detection, deduplication, profanity filters, and lightweight NER tag entities. HTML becomes tidy JSON; PDFs become markdown chunks; prices become numbers. Everything gets timestamps so agents can compare versions.
Step 4: Tokenizers split long passages into 512-token chunks, then embedding models turn each chunk into a high-dimensional vector. That representation lets downstream agents do fast semantic search without re-reading the whole document.
Step 5: Vectors live in services such as Weaviate, Pinecone, or open-source Milvus, while the raw text rides alongside in object storage. A hash of each chunk prevents re-ingesting the same paragraph tomorrow.
Step 6: REST or gRPC endpoints let an agent send a natural-language query and get back the top-k chunks, usually in < 200 ms, fast enough to stay in the model’s context window.
These steps feel nitty-gritty and too technical, but they’re the refinery that turns raw HTML into the data fuel an autonomous agent needs.

How Agents Use Scraped Data in Real Time
Most production agents use retrieval-augmented generation (RAG) systems so they can consult fresh facts instead of hallucinating. A typical flow, mirrored by open-source projects such as RAGFlow and NVIDIA’s enterprise blueprint, works like this:
- An offline job pushes new scrapes through the pipeline above. Online, the agent embeds the user’s question, grabs the nearest neighbors from the vector DB, and feeds both query and context into its LLM head. (The NVIDIA “RAG 101” guide breaks down these two loops in detail and is a great place to learn more about the process.)
- Some teams connect Kafka topics to the crawler so anything with a status-code 200 gets diffed and re-indexed within minutes. Agents that monitor pricing or policy changes no longer drift on stale data.
- After generating an answer, the agent may trigger follow-up scrapes, write to a CRM, or come up with another micro-agent; each step logs provenance so humans can audit what source supported which claim.
- Frameworks like RAGFlow offer plug-and-play ingestion, chunking, and reranking modules, while NVIDIA’s blueprint shows how to scale the same pattern across GPUs and multimodal archives. A start-up can stitch these pieces together in days instead of months.
The result is a virtuous circle: scrapers feed clean, timestamped knowledge into vector stores; agents pull that knowledge at inference time; their actions and user feedback highlight fresh pages to crawl next.
How AI Systems Make Sense of Scraped Data
Once the crawler finishes its work, the real work begins.
First, text, images, and tables are embedded, i.e., converted into high-dimensional vectors that capture meaning rather than surface keywords. A vector database then clusters similar ideas so an agent can retrieve “all mentions of hydrogen subsidies” as easily as you search your inbox. Recent guides on agent architecture call vector DBs the long-term memory that keeps decisions grounded in facts.
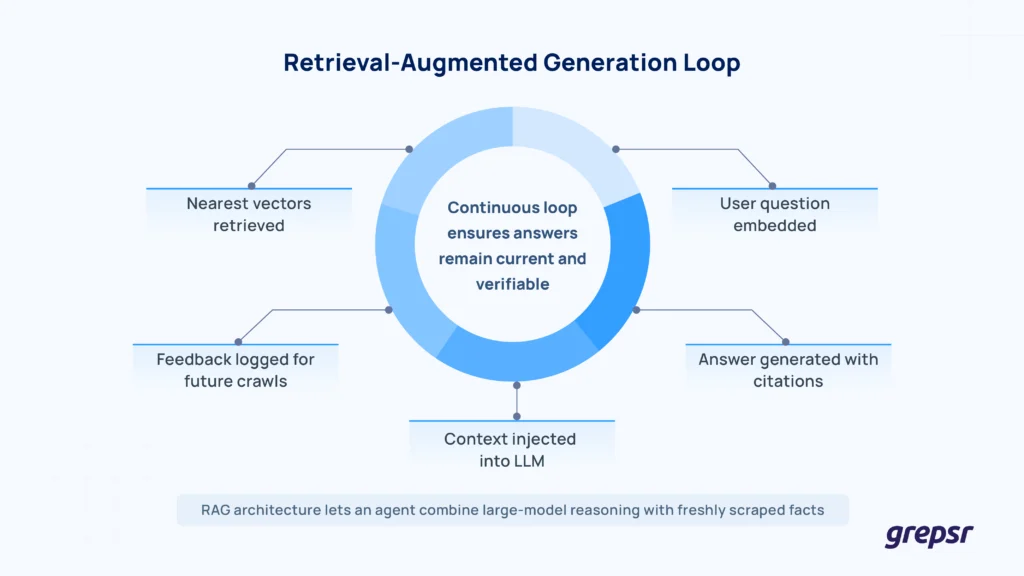
The next layer is retrieval-augmented generation (RAG). When a user asks a question, the agent embeds that query, pulls the closest vectors, and feeds both prompt and context into its language model. SiliconANGLE notes that this loop gives agents “situational awareness and on-demand memory,” and lets them plan multi-step tasks with confidence.
Finally, knowledge graphs add guardrails. By linking entities like people, products, regulations into a typed network, graphs help models resolve pronouns, spot contradictions, and cite sources.
A 2024 survey of 28 papers shows the field converging on LLM-KG hybrids for better accuracy and traceability.
The result: scraped pages become structured facts, vectors give those facts recall, and graphs keep them logical: three layers that turn raw HTML into agent-ready intelligence.
Put Your Data Pipeline on Autopilot with Grepsr
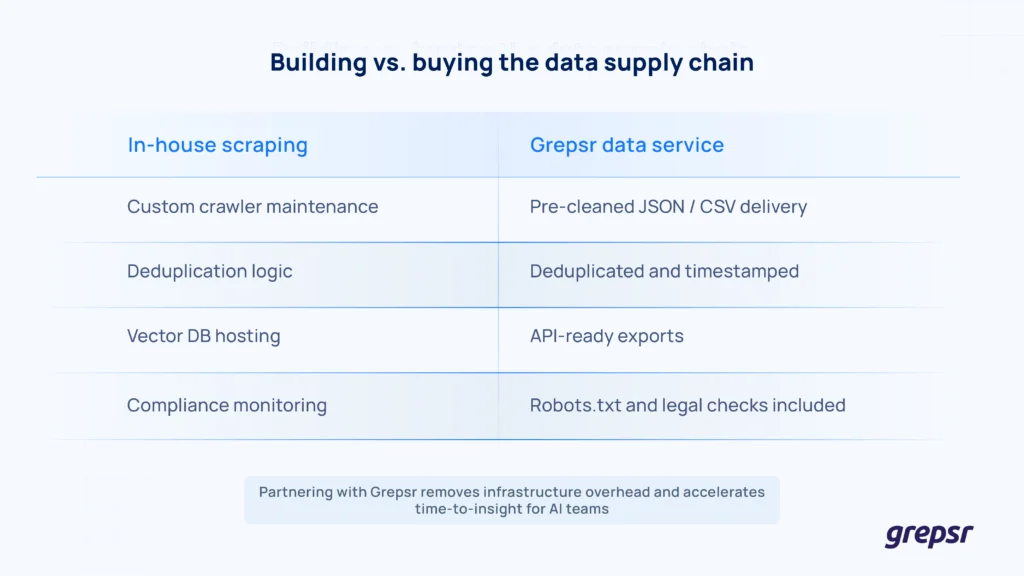
Building this stack is easier when you start with clean, right-sized inputs.
Grepsr handles the grunt work by crawling the open web on your behalf; Grepsr respects site policies, de-duplicates content, and exports the result as JSON, Excel, or CSV files ready for direct ingestion.
You could be fine-tuning an LLM, seeding a vector store, or bulking up a knowledge graph,
Grepsr gives you structured data that drops straight into the system you already have.
Book an appointment with Grepsr today.










































































































































