

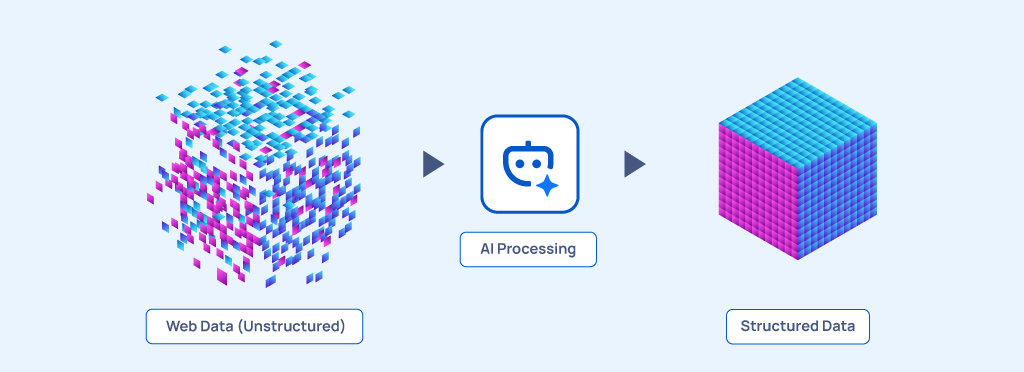
To develop effective Machine Learning (ML) models, organizations need more than just vast volumes of data-they need the right kind of data.
High-quality input-output pairs are essential to help models learn patterns, improve reasoning, and generalize effectively.
Techniques such as Retrieval-Augmented Generation (RAG) rely heavily on these structured examples to enhance model performance.
Much of this training data already exists across the public web, embedded in search interactions, product listings, customer reviews, and other dynamic content.
When harnessed correctly, this information can offer immense strategic value-without the need for manual labeling.
However, accessing this data at scale has become increasingly difficult. The proliferation of anti-bot technologies, including JavaScript-rendered content, CAPTCHAs, and aggressive rate-limiting, has significantly raised the technical barrier to web data extraction.
Even platforms like Google have taken active steps to make automated collection more difficult.
Yet these external defenses are only part of the challenge. The far more fundamental obstacle lies in the data itself: web data is messy, unstructured, and highly inconsistent.
Before it can be used to train any ML model, it must be cleaned, organized, and transformed into a format that models can understand.
And that’s where the real complexity begins.
Why Companies Struggle to Turn Raw Data into Usable Intelligence
Navigating anti-bot technologies requires more than just technical workarounds-it demands deep domain expertise.
With over a decade of experience and thousands of complex web data extraction scenarios behind us, Grepsr has built robust capabilities to operate effectively in high-friction environments.
While anti-bot defenses remain a key consideration, the greater challenge lies in the inherent chaos of the web itself.
For AI models to learn-or for businesses to extract meaningful insights-raw web data must first be transformed into structured, reliable formats.
At Grepsr, our core focus is on delivering data that’s immediately usable-clean, consistent, and tailored to your downstream needs.
But achieving that level of structure from unstandardized web content is a complex undertaking, one that requires more than basic scraping. It demands intelligent transformation at scale.
Problems with Accessing Web Data | How Additional Processing Makes it Worse |
|---|---|
Data Inconsistency | Additional transformations introduce more complexity, leading to errors and inconsistencies that slow down accurate decision-making. |
Data Quality Issues (Missing/Corrupted Data) | Cleaning and restructuring data consumes more resources, amplifying the risks of data corruption and increasing overall complexity. |
Legal and Compliance Issues | Adjusting processes to comply with regulations can make systems more rigid, increasing the legal risks as fragmented data handling creates inconsistencies. |
Data Volume and Scalability | Handling large datasets requires more infrastructure, slowing down access and making it harder to scale efficiently. |
Unstructured or Semi-Structured Data | Managing unstructured data often demands complex parsing, increasing the risks of errors and adding more overhead to the process. |
The emergence of transformer architectures-and their evolution into Large Language Models (LLMs) and Generative AI-has redefined what’s possible in data extraction and analysis.
We’ll explore specific applications in detail later in this article. For now, it’s worth noting that Grepsr has already integrated LLM capabilities into our crawling infrastructure, enhancing efficiency and significantly reducing upfront processing costs.
More importantly, our AI-powered data transformation modules are delivering measurable impact where it matters most-making raw web data cleaner, more structured, and instantly usable.
Based on hundreds of deployments across industries, these modules accelerate data readiness and shorten the path from collection to actionable insight.

How Does our Modular AI Enhance Data Quality for Enterprises?
At Grepsr, our mission is to simplify large-scale data access for modern enterprises. We deliver a continuous pipeline of high-quality web data-reliably, efficiently, and from virtually any online source.
But today, we go beyond just delivering raw datasets.
Our AI-driven transformation modules enrich and contextualize data before it enters your systems-reducing processing overhead and enabling faster, more informed decision-making.
These modules are designed to integrate seamlessly into your existing workflows. No complex configuration. Just plug in and gain immediate access to structured, intelligent data that’s ready for analysis, modeling, or action.
Without AI | With AI |
|---|---|
10M product reviews, raw | Same reviews, categorized by sentiment |
500 brand pages, HTML only | HTML + AI-tagged tone and topics |
Messy product listings across 4 sites | Unified catalog with matching SKUs |
PDFs with scattered info | Clean tabular output from unstructured content |
Manual QA required | AI checks for missing fields, anomalies, duplicates |
Each of these modules can be added on top of your current data pipeline:
1. Contextual Classification and Noise Filtration
Our AI models go beyond surface-level tagging. They interpret product reviews, search results, and customer feedback through the lens of your specific goals-filtering out noise and surfacing what truly matters.
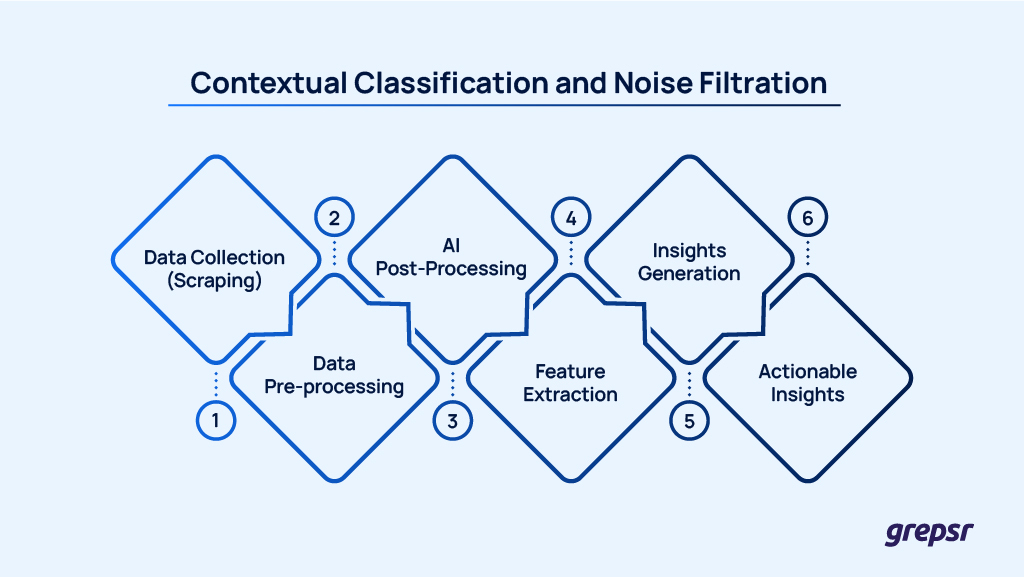
For example, in the context of an e-commerce business focused on smartwatches, we begin by extracting customer reviews, search engine results, and user feedback from relevant online platforms.
Then, our AI models enhance the raw data by filtering out irrelevant mentions and focusing on key insights, such as recurring customer complaints about screen brightness or praised features like waterproof design.
This ‘value-add’ ensures you only get the most relevant feedback to improve product offerings or customer communications, saving you time and energy.
2. AI-Powered Product Matching
AI-powered fuzzy logic and contextual embeddings allows us to identify, match, and track products across marketplaces-automatically resolving inconsistencies in names, SKUs, and attributes.
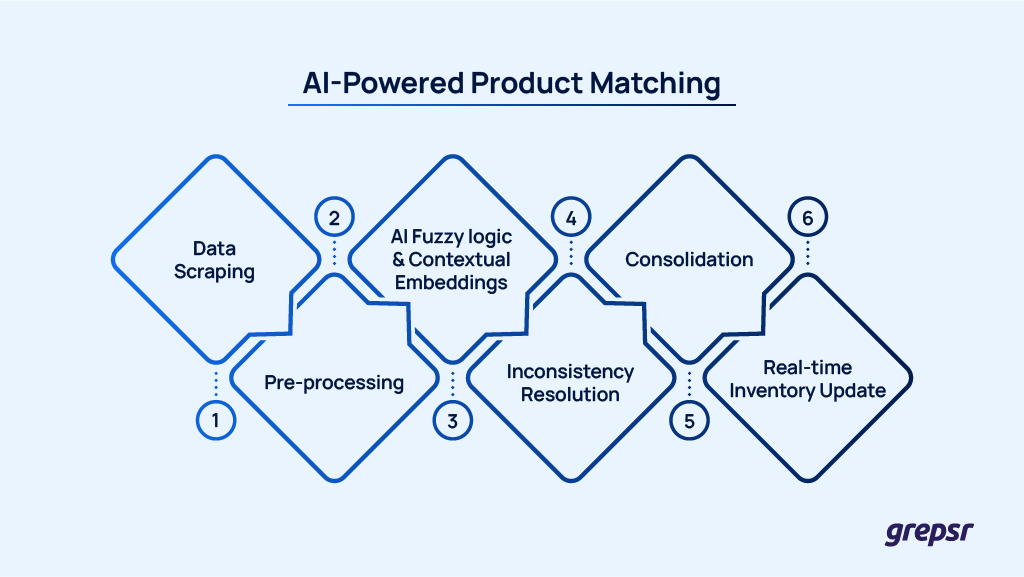
Take the case of an e-commerce retailer selling electronics across multiple marketplaces like Amazon, eBay, and Walmart.
These kinds of things happen quite frequently-the same smartphone might be listed as “iPhone 13 Pro Max” on one site, and as “Apple iPhone 13 Pro Max 128GB” on another.
The AI analyzes the scraped listings, resolves inconsistencies in names, SKUs, and attributes, and consolidates them into a single product record.
This process reduces manual oversight and ensures the retailer’s inventory is consistently updated across platforms in real-time.
3. Content Insights Extraction
Drop in thousands of articles, blogs, or landing pages. Our transformer models qualify each piece by asking the right contextual questions-then analyze the reasoning to filter out noise, surface meaningful insights, and flag risks like tone mismatch or potential copyright issues.

This functionality is particularly valuable for fact-checking organizations that require timely, verifiable data from diverse online sources.
For example, the same news event might be reported with slight variations – “Breaking: Vaccine approval in the US” on one site, and “FDA Approves Vaccine in the US” on another.
The AI analyzes these reports, resolves inconsistencies in phrasing, identifies key claims, and consolidates them into a single, verified report.
This reduces manual oversight, ensures content is verified against trusted sources, and enables faster fact-checking to maintain consistency across platforms.
4. PDF & Semi-structured Data Parsing
Extract structured data from PDFs, tables, and unstructured formats-without the need to manually define rules for every document variation.
Our AI modules interpret documents with human-like understanding and machine-scale efficiency.
For instance, a healthcare organization needing to extract patient data from diverse PDF formats-such as tabular reports, clinical forms, and fragmented sections-can deploy these modules to automate the extraction process.
This eliminates the need for custom logic per document type, significantly reducing development time and operational overhead.
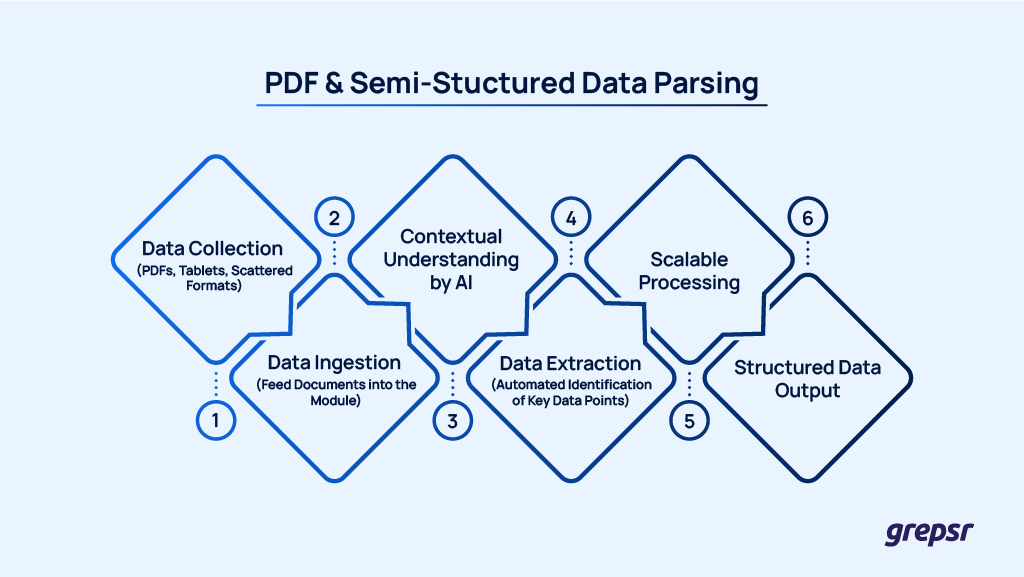
When you plug this AI module into your scraping workflow, it can understand the context of the documents like a human and can scale to process thousands of files quickly, ensuring consistency without the need for rule-building for every document variation.
5. Live AI Integration
We power downstream AI systems with structured, ready-to-use data; enriched upstream through intelligent transformations like classification, product matching, and content parsing.
Whether you’re building autonomous agents, analytics engines, or real-time decision tools, our pipelines ensure your AI runs on context-rich, decision-ready inputs.

Real-World Application: A logistics enterprise leverages AI agents to dynamically optimize delivery routes in real time.
The system ingests structured, pre-processed data from multiple sources-including live traffic feeds, delivery timetables, and weather forecasts. This data is further enhanced through intelligent transformation processes, such as location classification, route correlation, and weather pattern analysis.
With access to enriched, context-aware data, the AI agents autonomously adjust delivery routes in response to real-time conditions-improving operational efficiency, minimizing delays, and reducing overall logistics costs.
With AI, Without the Hassle
The explosion of user-generated content has fueled the rise of modern AI-transforming theoretical models into real-world applications. But with that scale came unprecedented complexity. Web data is more abundant than ever, but also more unstructured, inconsistent, and difficult to operationalize.
Today, it’s no longer just about extraction. The next competitive edge lies in transforming that raw data into structured, decision-ready intelligence-at speed, and at scale.
That’s precisely what our new data transformation modules are built to deliver: cleaner data, faster insights, and smarter outcomes.




































































































































































