


When it comes to sourcing web data, people tend to fall into two camps. One group takes on the burden of building the entire machinery themselves – not out of preference, but because they see no other option. The other focuses on getting the data they need, clean, structured, and ready to use.
The first group rolls up their sleeves and sketches out crawlers. They think in terms of sessions, retries, headless browsers, and parsing strategies. For them, building scrapers isn’t a passion project – it’s a necessary technical hurdle they have to clear to get to what really matters.
They pull together libraries like Playwright and BeautifulSoup, then wrestle with Docker, Airflow, and Kubernetes just to keep it from falling apart.
But for serious data-driven teams in analytics and AI, building an in-house crawling operation can quickly spiral into a drain on time, expertise, and budget.
Proxy management, evasion tactics, compliance, DevOps overhead — every layer adds complexity, and the costs pile up fast.
What starts as a “simple” scraper often grows into a permanent engineering burden.
The second group asks a sharper question: How can we get the data we need reliably, at scale, without losing focus on what really matters? They don’t want to worry about rotating proxies, shifting site structures, or maintenance issues.
They want the feed, not the headache.
For these teams, Grepsr offers a seamless pipeline where you specify your needs, and the data simply shows up — ready to power your models, dashboards, and decisions.
Ultimately, it’s not just about preference. It’s about where you want your team’s energy to go: solving engineering puzzles, or solving business problems.
And from there, everything else — speed, cost, reliability — naturally falls into place.
1. BeautifulSoup (HTML Parser)
BeautifulSoup is a Python library designed to help parse HTML and XML files, even when the markup is messy or poorly formatted.
It works by generating a structured parse tree, making it easier to locate and extract specific elements from a webpage — a key step in the web scraping task.
Originally developed by Leonard Richardson in 2004, the tool takes its name from the “Beautiful Soup” poem in Alice’s Adventures in Wonderland.
The name also playfully nods to the phrase “tag soup”, which refers to disorganized or invalid HTML.
A common web scraping process looks like this:

You initiate a programmatic HTTP request to the target website, and in response, you receive an HTML document — the raw content of the webpage — which may look something like this:

As you can see the product data are nested inside <div class=”product-list”>. Each product has:
- A name inside <h2 class=”product-name”>
- A price inside <span class=”price”>
- A description inside <p class=”description”>
What BeautifulSoup does is help you navigate and extract specific pieces of data from nested HTML structures. You don’t have to manually parse tags or worry about all the noise that comes with a full HTML document.
One of the advantages of using BeautifulSoup is that it works with several underlying HTML parsers such as html.parser, lxml, and html5lib, giving you flexibility and control over how the HTML is processed.

BeautifulSoup is a classic for quick, lightweight HTML parsing in Python. It’s solid when you need to scrape well-structured pages with minimal setup. I use it when there’s no JavaScript or dynamic content involved — just straightforward HTML. For anything more complex, like handling AJAX or SPAs, I’ll switch to some of our in-house tools (i.e. Maestro). It’s simple, but for scraping tasks, BeautifulSoup gets the job done every time.
2. Playwright (Browser Automation)
BeautifulSoup is great for scraping straightforward web pages — the kind where all the data you need is already present in the HTML response. For static content, it’s fast, lightweight, and efficient.
Many websites — even Google now for its SERPs — don’t serve all their content in the initial HTML. Instead, they use JavaScript to load data after the page has already been rendered in your browser.
If you send a standard HTTP request to these pages, you’ll only receive the bare structure — essentially a “shell” of the full content.
This is where Playwright comes in.
Playwright is a browser automation framework that simulates how a real user interacts with a website.
It launches a full browser instance under the hood (like Chrome or Firefox), waits for JavaScript to finish loading, and then gives you access to the complete, rendered HTML — just like what you’d see when opening the page in your own browser.

Despite so many browser automation tools in the market, only playwright has full compatibility with the major browsers. In addition to that, it has a more modern and stricter set of APIs which helps developers build more maintainable crawlers for the long run.
With Playwright, you can:
- Automatically scroll or click buttons to load more content
- Wait for elements to appear before scraping
- Handle login flows or dropdowns
- Interact with Single Page Application (SPAs) that load data via AJAX
Here’s how a typical dynamic scraping workflow might look like:

Here, Playwright fetches the live, rendered HTML after JavaScript has executed. Then, BeautifulSoup can be used to extract the product data from the DOM.
3. Cheerio
Just as BeautifulSoup is the go-to HTML parser for Python, Cheerio is the JavaScript equivalent — lightweight, efficient, and highly intuitive, especially for those with a jQuery background.
Cheerio is a fast and flexible library for parsing and manipulating HTML in Node.js. It strips out all the browser-related complexities of jQuery and focuses solely on server-side HTML parsing.
If you’re building a scraping workflow in JavaScript and don’t need a full browser engine like Playwright, Cheerio is an excellent first choice.
Like BeautifulSoup, Cheerio does not execute JavaScript. It works best when:
- You’re scraping static pages that don’t rely on JavaScript for data loading
- You want blazing-fast scraping performance
- You’re using Node.js and don’t need full browser simulation
Here’s how the product-parsing example we used with BeautifulSoup would look like using Cheerio:
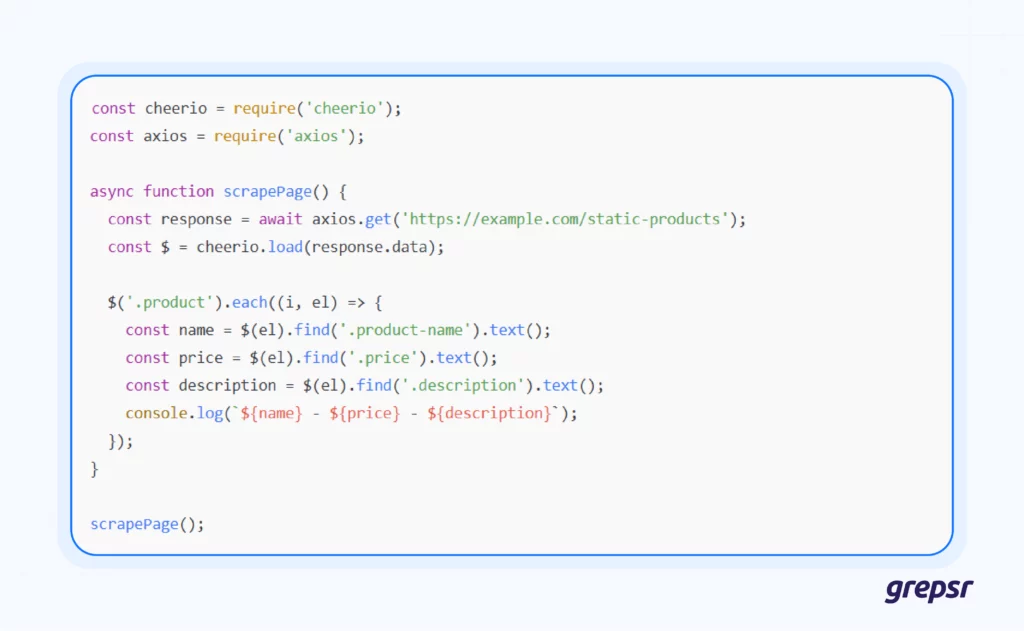
This is almost identical to jQuery syntax, which is what makes Cheerio so approachable for web developers coming from a front-end background.

4. Common Crawl
Up to this point, we’ve explored tools built for developers — people who enjoy setting up infrastructure, tweaking scripts, and building custom workflows to extract data from the web.
But at the beginning of this article, we talked about two kinds of people who go looking for web data:
- Those who love building the tools and pipeline themselves
- And those who don’t care how the data comes — as long as it’s usable
Common Crawl is made for the second group.
It provides a free, open archive of web data that anyone can access. Since launching in 2007, Common Crawl has amassed over 250 million pages, and its datasets have been cited in more than 10,000 research papers.
It’s a goldmine if your use case matches what they already have.
However, Common Crawl doesn’t provide custom data extraction. You can’t ask them to crawl a specific site for you or deliver new, on-demand data.
Another challenge is scale: while the data is freely available, working with it requires infrastructure.
You’ll need cloud storage, distributed computing (like Hadoop or Spark), and a good grasp of data engineering to filter and process what you need.
5. Grepsr
While Common Crawl is a powerful public archive, it only gives you what it has already collected. You can’t ask for something custom, and working with the data often requires significant infrastructure and technical expertise.
Grepsr fills that gap — and goes much further.
We offer a fully managed, platform-driven data extraction service that eliminates all the technical heavy lifting. No need to build scrapers, dodge CAPTCHAs, or handle IP rotation — we take care of it all.
At the core of our service is the Grepsr Data Management Platform, your command center for everything data extraction:
- Track progress and monitor performance in real time
- Schedule crawlers to run at your preferred frequency
- Collaborate seamlessly with your team
- Receive clean, structured data delivered to your system, ready for analysis or AI applications
Some of our salient features are:
- Built for Scale: Grepsr’s infrastructure is designed to extract millions of records per hour. Behind the scenes, we employ intelligent IP rotation, auto-throttling, and distributed crawling to deliver high-volume data efficiently.
- Quality at every step: We combine people, processes, and technology to ensure clean, reliable, and deduplicated datasets — whether you’re tracking SKUs across ecommerce platforms or mining insights from forums and reviews.
- Collaborative by design: Your project gets a private communication channel within the platform, making it easy to submit change requests or coordinate with our engineering team — without lengthy email threads.
- Seamless integration: We’re one of the first managed services to offer automation and custom scheduling through a self-serve platform. From CSV and JSON to API and cloud storage delivery (S3, GCS, Azure) — your data flows exactly where it needs to go.
- Web Scraping Veterans: Our engineering team brings deep technical skill and a problem-solving mindset, working closely with you to navigate complex data requirements and deliver results that align with your goals.
6. Pline
While tools like Beautiful Soup and Playwright require coding expertise to configure and run, Pline was developed for users who want to be hands-on with their data collection but don’t have programming skills.
Pline provides an intuitive Graphical User Interface (GUI) that lets users visually select the data they need and automate the extraction process.
This way, you can engage directly with the web scraping process, without needing to learn how to code.
Key features of Pline
- Automation: Set up workflows to automatically extract data from multiple pages.
- Browse and Capture: Capture data as you browse, defining the fields you want to extract along the way.
- Inner Page Data Extraction: Extract both listings and detailed pages simultaneously in a single workflow.
- Adaptive Selector: Easily adjust to unexpected changes in page structure without interrupting the extraction.
- Multi-Tab Extraction:Run workflows across multiple tabs on the same site to collect data more efficiently.
7. Maestro (Bonus)
Playwright and Puppeteer are excellent — for most use cases.
But at Grepsr’s scale, where we deploy hundreds of thousands of crawlers daily, evading anti-bot defenses demands more.
So we built our own browser automation framework: Maestro.
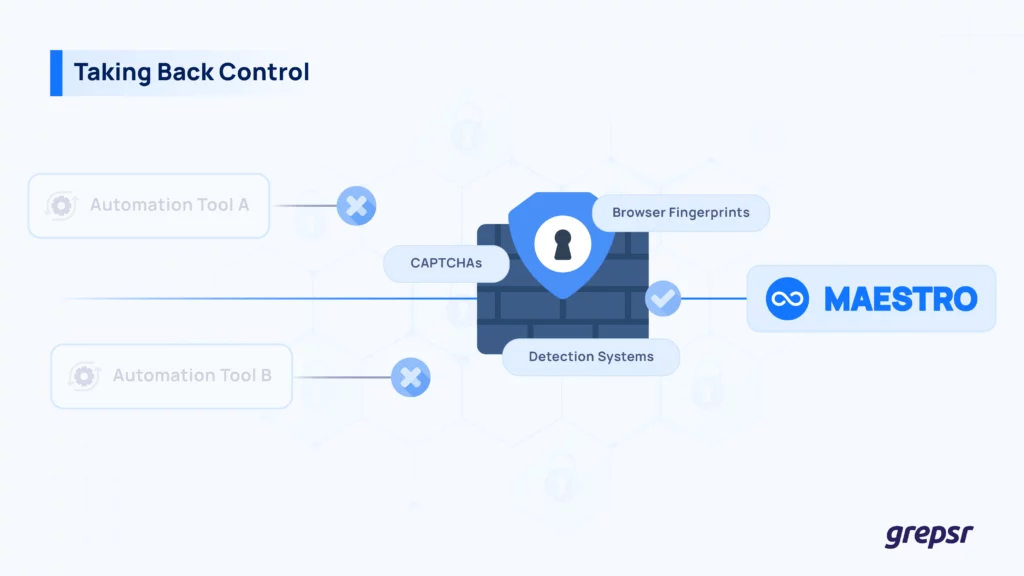
Maestro is a lean, powerful tool crafted from years of battling CAPTCHAs, browser fingerprints, and detection systems.
Where Playwright and Puppeteer hit walls, Maestro cuts through — delivering a significantly higher success rate against anti-bot systems.
What makes Maestro different?
Unlike conventional tools that operate through browser-level websockets — a higher abstraction that’s easier for websites to detect — Maestro communicates directly with page-level websockets.
This low-level access gives us granular control over browser actions while minimizing detectable signatures.
By speaking natively with the browser’s devtools protocol and stripping away unnecessary layers of abstraction, Maestro offers a lightweight, highly customizable environment.
Developers can extend only the features they need — making it lean for performance and flexible for complex challenges.
It also natively handles CAPTCHA detection and avoidance, supports multiple browser versions, and improves stealth, speed, and stability across our infrastructure.
Why build Maestro when others exist?

Playwright and Puppeteer got us far, but at Grepsr’s scale, we kept hitting walls. Every fix felt like a band-aid. After a lot of late nights and dead ends, we realized we needed to get closer to the metal. Maestro came out of that — a leaner, lower-level approach that finally gave us the control we needed.
Because operating at Grepsr’s scale means navigating territory few others reach.
Off-the-shelf tools weren’t enough. We needed a solution tuned for uncharted terrains — purpose-built to thrive where others falter.
Today, Maestro is a critical part of how we push the limits of what’s possible in data extraction — and a foundation for the next generation of AI-driven browser agents.
It’s proprietary, built for internal use.
And we’re just getting started.
To Build or To Buy, That is The Question
Paul Graham once compared programming to architecture rather than natural science.
You don’t stumble upon a new element in programming — you design systems, just as architects design structures meant to stand the test of time.
Building an enterprise-grade web scraping system is no different.
To extract data reliably — and avoid detection — you need a full team:
- DevOps engineers to deploy Kubernetes clusters and manage intelligent proxy rotation.
- Delivery engineers to conduct feasibility studies and ensure ethical, low-impact scraping.
- Scalability experts to design systems that can grow seamlessly with your data needs.
This is only the tip of a mighty iceberg.
Are you an architect looking to build and maintain your own city?
Or an explorer focused on reaching new frontiers?
If you have the resources to build from scratch — with tools like BeautifulSoup, Cheerio, and Playwright — the journey can be rewarding, but it’s just the beginning.
But if your real goal is to extract insights, not build infrastructure, Grepsr is your answer.
We deliver custom, scalable data extraction — so you can focus on discovery, not detours.






















































































































































