You might be losing the full potential of utilizing the data for your business growth because of limited web data pipelines. Data Pipelines play an essential role and behave as a central point of business data architecture.
How to make sure you have an efficient and smooth flow of data? Well, that’s by having scalable web data pipelines.
Think of it as an invisible plumbing that continuously pulls data in from the web and APIs, cleans and enriches it, and lands it where your teams can use it.
Having a scalable web data pipeline for your organization ensures that you have all the infrastructure necessary for big data scraping, a data ingestion pipeline, and automated ETL operations to harness vast amounts of information seamlessly.
In this blog, we will guide you on scalable web data pipelines, what it is, best practices, and how you can integrate smoothly into your business.
Understanding Scalable Web Data Pipelines
Before moving to “Scalable”, let’s first understand what web data pipelines are. Data pipelines are a series of processes that collect data from multiple sources and transfer it to a destination, where it can be analyzed and utilized according to business needs.
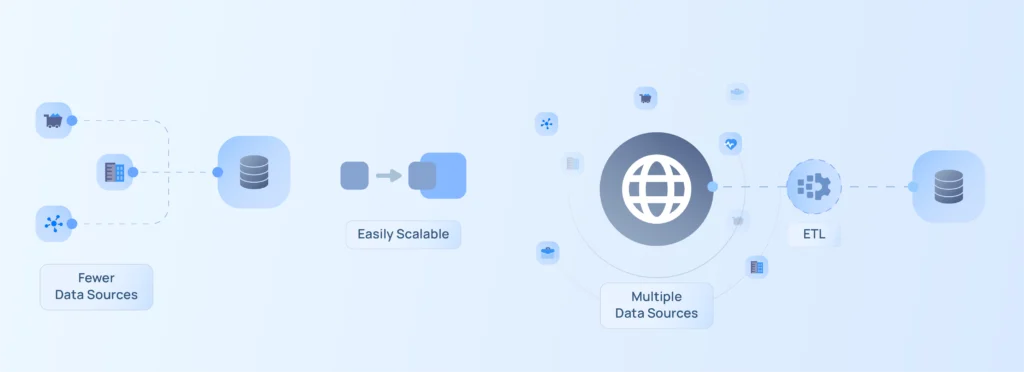
Now, when we say scalable web data pipelines, it means the ability to handle large or growing data as it continues to increase every second. Handling the volume efficiently and smoothly without compromising performance is the concept of scalable web data pipelines.
For many enterprises, building these pipelines is not just about managing large volumes of data, but also about ensuring that the processes are resilient, adaptable, and cost-effective. Let’s dive into the components crucial for building an effective pipeline.
The Role of Data Ingestion Pipelines
Consider data ingestion pipelines as the first step of a scalable web data system. It’s where all the raw signals from the outside world enter your organization; those signals can be from anywhere via web scraping jobs, third-party APIs, event streams, partner SFTP (Secure File Transfer Protocol), or direct reads from external databases.
If done correctly, data ingestion is limited to just “data collection”; it also stabilizes them, ensuring the records are complete, trustworthy, secure, and ready for further use cases.
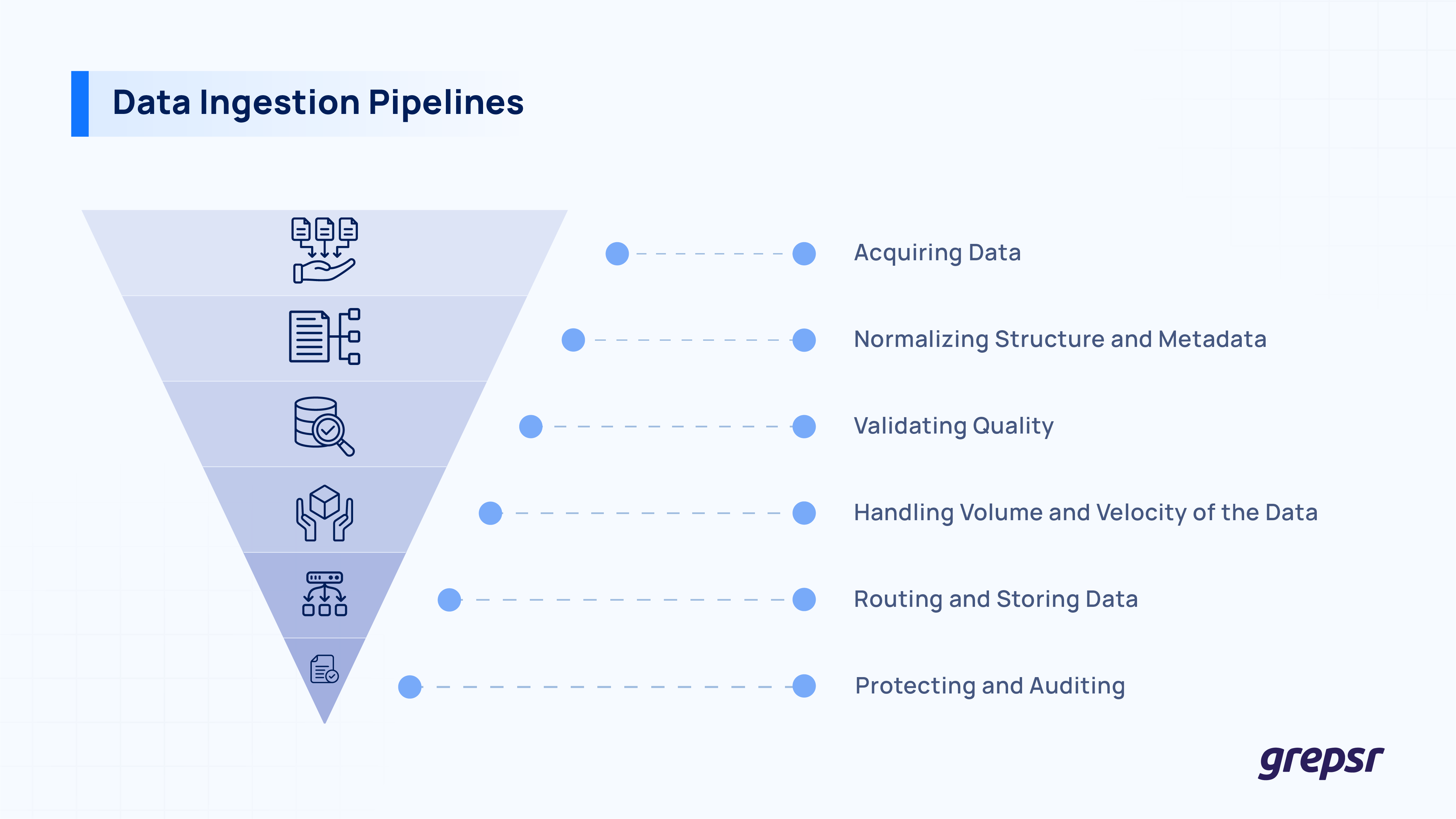
In short, Data ingestion pipelines are responsible for:
- Acquiring Data
- Normalizing structure and metadata
- Validating quality
- Handling volume and velocity of the data
- Routing and storing data
- Protecting and auditing.
Key Considerations for Data Ingestion
Assume data ingestion as the first door you encounter for data pipelines, like any door, data ingestion also has hinges and locks to keep it going smoothly! Let’s discuss some of the key points for data ingestion.
Source Diversity: Most of the organization’s data pipelines don’t pull all of the data from a single source; instead, they mix web pages, public and partner APIs, S3/SFTP file drops, event streams, and even change-data-capture from external databases.
The pipelines should be able to normalize and standardize the data to ensure smooth flow and accommodate any future changes.
Real-Time Data: Many industries rely on real-time data, which they use for analytics and making business decisions quickly. Therefore, the pipeline should ingest data in real-time, minimizing delays as much as possible, thereby helping businesses create strategic insights.
Reliability & Fault Tolerance: No one wants pipeline failures. Any loss in the data directly depended on the potential loss to the company. Ensuring the pipeline is reliable and robust to failures, latency, and errors is an essential part of data ingestion.
Embracing Big Data Scraping
Big data scraping is the step where you collect a lot of valid public data from the web. Think of it as gathering all the signals you need, such as prices, reviews, product details, or news. The goal is to capture large datasets quickly, correctly, and in a way that follows laws and ethical rules.
If your team is copy-pasting data by hand, you are already scraping, just in a slow and risky way. Automating this work saves time and reduces mistakes.
Let’s see some of the efficient big data scraping practices.
Efficient Big Data Scraping Practices
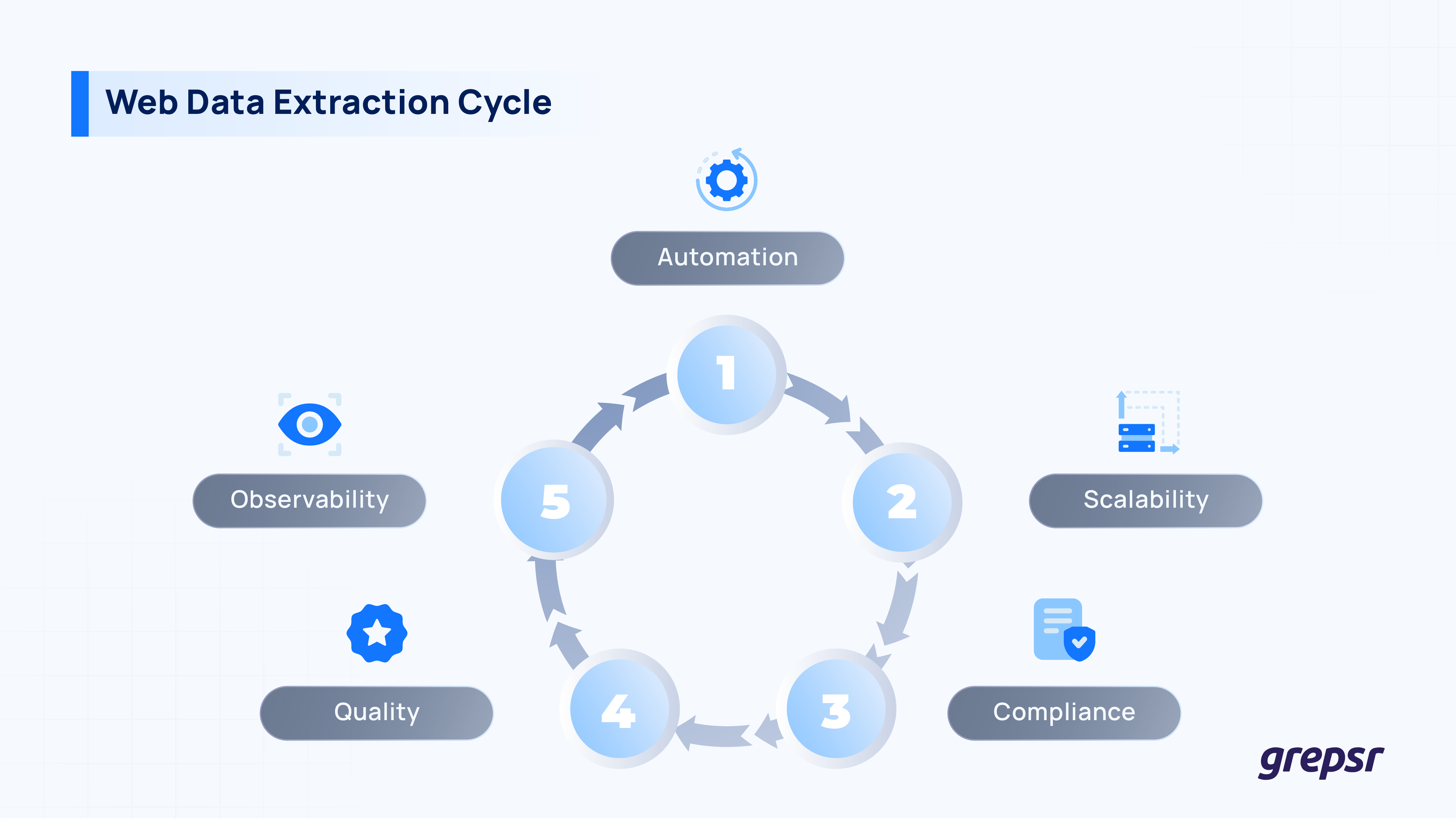
1. Automation: Set up scheduled crawlers to fetch data on a regular timeline. Automated retries help when a page fails to load. This keeps your pipeline running without manual effort.
2. Scalability: Use tools that can handle more pages as you grow. Support for headless browsers is particularly beneficial for modern, JavaScript-heavy websites. Incremental crawls (only fetching what changed) keep costs and time low.
3. Compliance: Follow site terms, robots.txt, rate limits, and privacy laws. Do not collect personal data without a valid reason. Keep logs of where and when each record was collected so audits are easy.
4. Quality: Add simple checks at the source. For example, make sure a record has a name, price, and currency, and that dates are valid. Catch problems early so bad data does not reach your dashboards.
5. Observability: Track coverage, freshness, accuracy, and cost. Set alerts for sudden drops or spikes so you can fix issues fast.
If you prefer not to build all of this in-house, platforms like Grepsr provide managed, compliant web data collection that scales with your needs while giving you clean, analysis-ready outputs and audit trails.
Automated ETL Pipelines: Transforming Data for Analysis
Once data is collected, it moves into ETL (Extract, Transform, Load) pipelines, the “make it useful” phase. Think of this as a car wash: raw, messy input goes in; clean, structured, labeled data comes out ready for your warehouse and BI tools.
A simple mental model:
- Raw (staging): exact copies of the scraped data.
- Refined: cleaned, de-duplicated, and standardized formats.
- Analytics-ready: business rules applied and fields documented, ready for reporting.
Best Practices for ETL Pipelines
#1 Data Cleaning:
Remove duplicates, fix types and formats, and align units and currencies. Use nulls when you do not have a safe default.
#2 Transformation Rules:
Websites change often. Write small, modular steps so you can adjust quickly. Version your logic so you can reproduce older reports.
#3 Scalable Load Processes:
Partition tables by date or source to speed up loads and backfills. Use idempotent writes and upserts to handle late-arriving data without creating duplicates.
#4 Orchestration & SLAs:
Use a workflow tool to set job orders and alerts. Define clear deadlines for your most important tasks, for example, “available by 8:00 AM IST.”
#5 Testing & Data Contracts:
Add unit tests for code and data tests for values. Publish a short data contract that lists fields, freshness, and quality expectations for users.
#6 Governance & Security:
Tag sensitive fields, control access by role, and keep audit logs. This protects users and speeds up compliance reviews.
The Power of Scalable Web Data Pipelines for Enterprises
A scalable pipeline is not only about handling more data. It is about turning that data into actions that help the business grow. When your pipeline can scale, you can add new sources, answer new questions, and support more teams without starting from scratch.
Simple example: You collect competitor prices, normalize currencies, and push the results to your warehouse by 8:00 AM. Pricing, sales, and marketing all see the same view before their morning stand-up. Prices get adjusted, campaigns get updated, and stock is reordered on time.
Key Considerations for Enterprises
- Invest in Scalability
Plan for more data and more users. Choose tools that support parallel processing, partitioning, and incremental loads. Keep costs visible so you can scale up or down as needed. - Prioritize Security and Compliance
Protect personal and sensitive data. Set clear roles, encrypt in transit and at rest, and keep audit trails. Review high-risk tables on a regular schedule to stay in control. - Leverage Expertise
Bring in specialists where it saves time. Partners like Grepsr can manage data collection and integrations, while your team focuses on modeling, metrics, and business impact.
What “good” looks like: clear SLAs for freshness, a few trusted “gold” tables, documented logic, and alerts that reach the right owner before stakeholders notice an issue.
Takeaway
Strong data pipelines turn raw inputs into reliable decisions. Collect clean data, turn it into well-modeled tables, and integrate it into the tools your teams already use.
Start simple, automate the repeatable parts, and add quality checks as you grow. With the correct setup, your data stays accurate, compliant, and ready for action.
If you want to see how Grepsr can support your pipeline with compliant data collection and smooth integrations, explore our solutions or connect with our team.
FAQs – Scalable Web Data Pipelines
1. What factors determine the scalability of a data pipeline?
Capacity to handle higher volume, variety, and velocity without slowing down or breaking. Support for parallel processing, partitioned storage, and incremental loads. Clear cost controls so you can scale efficiently.
2. How does real-time data integration benefit enterprises?
It keeps dashboards and tools current, which helps with time-sensitive actions such as pricing, inventory management, fraud checks, and customer support. Teams respond faster and reduce revenue loss from delays.
3. Why is compliance important in web data scraping?
Compliance reduces legal risk and builds trust. It ensures you collect data within terms of use and privacy laws, and that sensitive fields are protected or removed when required.
4. How can automated ETL processes enhance data pipelines?
Automation cleans and transforms data the same way every time. It reduces manual errors, speeds up delivery, and makes issues easier to identify, trace, and resolve.
5. What role does Grepsr play in building scalable data pipelines?
Grepsr manages compliant data collection and provides integrations to common warehouses and tools. This helps you stand up reliable pipelines faster and with less maintenance.