

Diseases don’t wait for quarterly reports. Outbreaks, drug reactions, and patient sentiment float online long before being visible in formal datasets.
Smart scraping lets public health systems keep up by converting online chatter into real-time, structured signals.
Let’s see how web scraping for healthcare gets the work done.
But first, care for a refresher?
The ABC of Web Scraping
Fundamentally, web scraping automates the retrieval of data from websites, much like a person would do manually, but only faster and at scale. The process starts with sending HTTP or HTTPS requests, typically GET to retrieve page content or POST when simulating form submissions. These requests return the raw HTML of a page.
Once you have that HTML, you have to make sense of it. Every web page is structured as a Document Object Model, or DOM: a tree of elements like <div>, <span>, <a>, etc. To parse this structure, you must rely on libraries like BeautifulSoup or lxml in Python, or Cheerio if working with Node.js. These tools let you manipulate the DOM.
To pull the right data, you need selectors
- CSS Selector example: div.article h2.title targets <h2> tags with class title inside a div with class article.
- XPath example: //div[@class=’article’]//h2[@class=’title’] does the same thing, using path-like syntax.
Then there’s the extraction logic: looping through those elements, pulling text or grabbing attribute values like href from links or src from images.
Some websites complicate things by rendering content client-side with JavaScript. For these, static HTML won’t be enough. You’ll need headless browsers to simulate user interactions and fully render the page. They’re heavier and slower, but necessary.
Finally, there’s the issue of raw vs. usable data. What you scrape isn’t clean. Expect chaotic HTML, inconsistent formats, and missing values. Cleaning and structuring the output becomes part of the process before any AI model can digest it.
Now, how does all of this play out in the medical field?
High-Impact Uses of Web Scraping in Healthcare
Web scraping is already being used to drive targeted public health efforts and inform care for high-risk groups. It turns disparate, publicly available data into useful healthcare information.
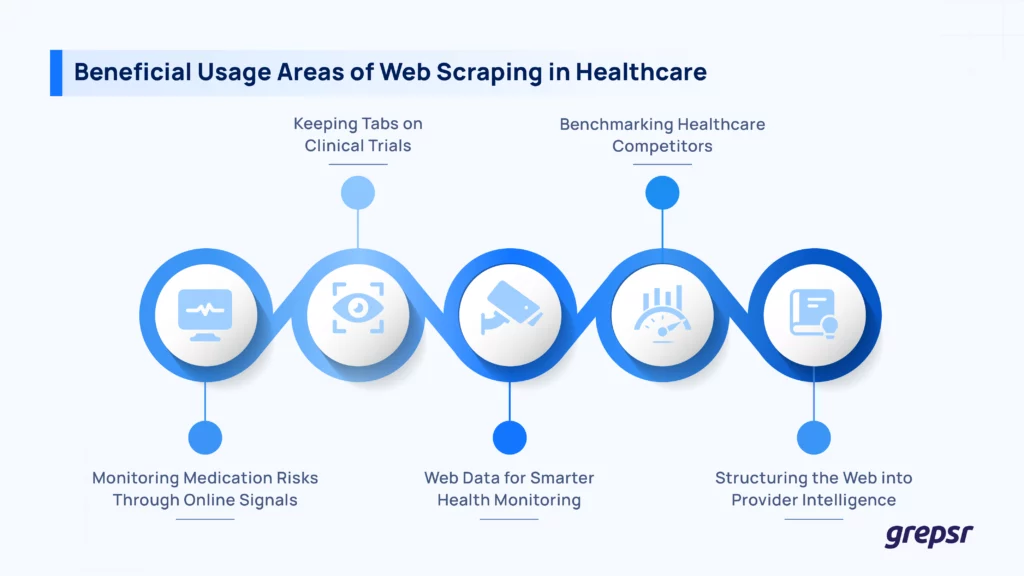
Here’s how web scraping for healthcare proves beneficial.
Pharmacovigilance and drug safety
Scraping patient forums, Reddit threads, and social media helps in identifying adverse drug reactions (ADRs) that haven’t yet triggered formal alerts. Patterns in tone and frequency signals real-world treatment risks, particularly for newer medications.
For example, integrating scraped sentiment data with pharmacological profiles guides post-marketing surveillance before regulators step in.
Clinical research and trial monitoring
Automating data collection from sources like Clinicaltrials.gov or research repositories helps researchers monitor enrollment status, intervention types, and geographic patterns at scale.
This is useful for mapping clinical research activity against disease burden or funding flows. Scraping publication databases also eases citation mapping and tracking how fast new findings disseminate.
Public health surveillance
An interesting case from North Carolina involved scraping daily inmate rosters from 29 jail websites, covering over 200,000 incarcerated individuals annually. Researchers created a de-identified dataset that improved HIV surveillance and care continuity for justice-involved populations by linking jail data with court records and state HIV registries.
This system could even support real-time alerts to health departments when HIV-positive individuals enter jail for timely engagement and treatment.
Competitive intelligence and market research
Scraping provider websites and supplier portals helps healthcare companies benchmark device pricing and track service availability. It’s not rare for hospitals to scrape peer facilities to compare telehealth offerings or understand how competitors are marketing to specific patient groups.
Patient review data is also scraped to detect recurring pain points that product teams or clinical operations otherwise miss.
Building healthcare directories and knowledge bases
Scraping allows aggregation of physician lists, clinic locations, and insurance networks into clean, searchable directories. These datasets become the base for provider-finder tools, telemedicine routing systems, and even insurance plan integrations.
The takeaway is clear: scraping links is turning public data into a system that drives medical outcomes. However, ethical handling is very important when individual-level identifiers are involved, especially in vulnerable populations.
But, you must be wondering, what about AI in healthcare? Doesn’t web scraping have a hand in that? Sure.

Feeding AI Medical Models with Web Data
AI systems in healthcare need contextual, current, and clean data. Web scraping brings together static clinical datasets and the real-world information that medical AI learns from.
1. Real-world input for training models
Scraped data from health forums, news sites, and patient reviews is needed to train NLP models on unstructured medical text. Unlike clinical notes locked behind EHR systems, these sources capture how patients talk about symptoms, treatments, and side effects.
One could, for instance, train a symptom-checking chatbot using posts from Reddit’s r/AskDocs or Drugs.com discussions to improve understanding of layperson language.
2. Dynamic medical knowledge updates
Clinical AI models must adapt as medical knowledge improves. Web scraping makes sure that AI pipelines ingest the latest trial results, drug recalls, or disease alerts by pulling structured data from:
- Clinicaltrials.gov and WHO ICTRP (trial outcomes, recruitment updates)
- FDA recall feeds and medical news outlets
- Health agency dashboards (like CDC COVID updates)
Real-time ingestion supports model fine-tuning and keeps recommendations relevant.
3. Building weak supervision pipelines
Labeling medical data manually is expensive. But you can use scraped data to build weak supervision sources, where rules or heuristics generate labels for training at scale.
A good example in healthcare is using scraped patient reviews to auto-label satisfaction levels, which in turn trains sentiment models for healthcare feedback analysis.
4. Powering multimodal AI systems
Web scraping also grabs visual content like diagrams, radiology images, and anatomy visuals from open educational resources. These are currently being used to develop multimodal models that combine text and images, particularly medical visual question answering (VQA) systems.
5. Keeping LLMs grounded in truth
LLMs tuned for medical use benefit from structured web data during retrieval-augmented generation (RAG). For instance, scraping up-to-date medical guidelines or publications lets the system cite real sources and not generate fluent guesses.
These sound great, but is it easy? Definitely not.
Challenges of Using Web-Scraped Data in Medical AI
Scraped data is powerful, but it’s not plug-and-play. The margin for error is thin in healthcare, especially when regulatory stakes are high. Before AI models ever see this data, teams face a series of hard problems.
The big roadblocks
The biggest challenge is that healthcare data online isn’t standardized. One clinic would list MD, Oncology, while another writes Dr. Jane Smith – Cancer Specialist. Websites vary a lot in structure, terminology, and update frequency.
You need to apply normalization techniques to standardize scraped outputs like job titles, specialties, and medication names into unified taxonomies.
Add to that the fact that a lot of relevant health data is hidden behind JavaScript rendering, logins, or paginated views. For example, many hospital pricing pages or trial databases use dynamic loading, which basic scrapers miss.
In such cases, it’s better to rely on dedicated web scraping service providers like Grepsr. Grepsr uses headless browsers and automation frameworks, so it captures exactly what a human sees, regardless of page complexity or load logic.
Some other issues to note
In projects like the UNC HIV surveillance study, scraped jail and health data raised concerns around consent, re-identifiability, and the blending of research with surveillance. Even if the data is public, its use in downstream AI requires review and sometimes IRB approval.
Once again, a service like Grepsr offers scraping plans that respect robots.txt, avoid PII unless explicitly authorized, and include flags for sensitive fields.
That’s all good, but what about data cleaning? HTML tags, typos, broken links, outdated info, or duplicated records ruin training pipelines or inflate compute costs.
With Grepsr, every dataset comes pre-processed with deduplication, null-handling, encoding fixes, and optional enrichment. You get datasets that are model-ready.
Web Scraping is Pushing Healthcare into the Future
The healthcare industry is moving on from siloed systems to adaptive, data-driven infrastructure. In this process, web scraping is the connective tissue.
Be it accelerating drug safety analysis or tracking care gaps across populations, scraping brings insights that used to take months in minutes.
But speed without precision is a liability. Medical AI needs trustworthy pipelines and compliance baked in from the start. The right data partner makes the difference.
If your team is exploring how to integrate web-scraped data into clinical tools, public health platforms, or AI models, let’s talk.






































































































































































