

TL;DR:
- In this article, we’ll learn how you can crawl large websites without getting blocked. The fundamentals include following robots.txt, rotating residential IPs, and adding human-like pauses.
- You’ll also have to instrument every request and auto-throttle at the first hint of blocks or CAPTCHAs.
- When scale and upkeep get painful, outsource the crawling and scraping to Grepsr and focus on the data.
Not long ago, when I started messing around with scraping, I built a Python script to crawl basic sites. I believed the script was pretty good, and objectively, it was. Much to my disappointment, using my crawler was full of difficulty.
In your scraping journey, you must’ve shared my frustration.
And there’s a good reason behind that. 50 percent of web traffic today is automated, and a full third of that is “rogue” bots. Rogue because these bots don’t care about privacy and scraping rules, let alone its ethics.
Websites, naturally, are compelled to crank up their defenses. Now, “polite crawling” has become a valued skill. And I’ll share what I know about polite crawling today.
Below, you’ll learn how to scrape the web without getting blocked.
Pulling millions of pages without triggering a single 403 is still possible.
The Bot Battlefield in Numbers
Imperva’s 2024 Bad Bot Report estimates that automated traffic now accounts for half of all web requests, with malicious activity responsible for roughly one‑third.
This creates problems for actual humans trying to scrape the web for various purposes.
“Automated bots will soon surpass humans online, changing the way organizations build and protect their websites,” warns Nanhi Singh, Imperva’s GM of Application Security.
Security researchers at F5 Labs report a similar trend: across 200 billion protected requests analysed in 2024, 4.8 percent were still unwanted automation, most often price‑scraping or credential‑stuffing campaigns persistent enough to slip past first‑line controls.
At the same time, legitimate large‑scale crawls are booming: MIT’s Billion Prices Project once captured 500,000 price quotes every day in the US alone, dwarfing official data‑collection programs.
Web scraping itself isn’t “bad”; it’s simply an automated way to gather information that’s already publicly available. Search‑engine indexing, academic research, and archive projects are all powered by scrapers.
Problems start only when crawlers behave irresponsibly.
It reminds me that Sir Tim Berners‑Lee once famously advocated, “Raw data, now!”. The appetite for open (and not‑so‑open) data keeps rising; so do defenses. Let’s see how.

How Sites Sniff Out Scrapers
Modern bot‑management stacks layer multiple signals. The table below maps the most common tripwires to practical counter‑moves you’ll meet again in the next section.
| Detection signal | Typical trigger | Practical mitigation |
| IP reputation and velocity | Too many requests or ASN flagged as data‑center | Rotate residential and mobile proxies; distribute load geographically |
| User‑Agent or TLS fingerprint | Headless browser defaults, identical cipher suites | Randomize user agent strings; borrow real‑browser JA3 or TLS fingerprints |
| Cookie and session anomalies | Stateless hits, missing JS‑set tokens | Persist sessions; execute JS challenges in a headless browser |
| Timing and behavior | Millisecond‑perfect intervals, zero think‑time | Add human‑like jitter; respect crawl‑delay headers |
| Robots.txt violations | Ignoring disallow rules or crawl‑budget hints | Parse robots.txt; throttle high‑depth pages first |
| CAPTCHA or JS challenges | Suspicious behavior and failed proof‑of‑work | Pre‑solve CAPTCHAs via third‑party solvers; reduce challenge frequency by blending in |
How to Safely Crawl and Scrape the Web
I’ve distilled the methods used by teams that reliably harvest millions of pages per day without provoking bans or legal headaches.
Build credibility first
Respect robots.txt and X‑Robots‑Tag. Identify yourself in the From or Contact header where permitted. Cache aggressively; hit each URL only as often as content freshness demands.
Distribute the footprint
Residential or mobile proxy pools are much harder to blacklist than a /24 in a public cloud; F5 notes residential IPs are now the default for advanced scrapers.
Along with that, stagger requests across time zones and IP ranges to mimic genuine user diversity.
Blend in at the protocol layer
Rotate modern, real‑browser TLS ciphers and valid Accept‑Language strings. Execute site JavaScript in headless Chrome or Playwright to collect the cookies that anti‑bot scripts expect.
Throttle intelligently
Here, use adaptive concurrency: slow down on 4xx and 5xx bursts, and speed up when latency is low. Also, try inserting a Gaussian “think time” between actions; random, not fixed.
Defuse challenges
Integrate a solver marketplace (Anticaptcha, CapMonster, hCaptcha Enterprise, etc.) only after you’ve minimized triggers. Detect soft blocks, like blank pages and truncated HTML, and back off immediately.
Log and learn
Store every response header, status code, and challenge key. Patterns reveal themselves long before outright bans.
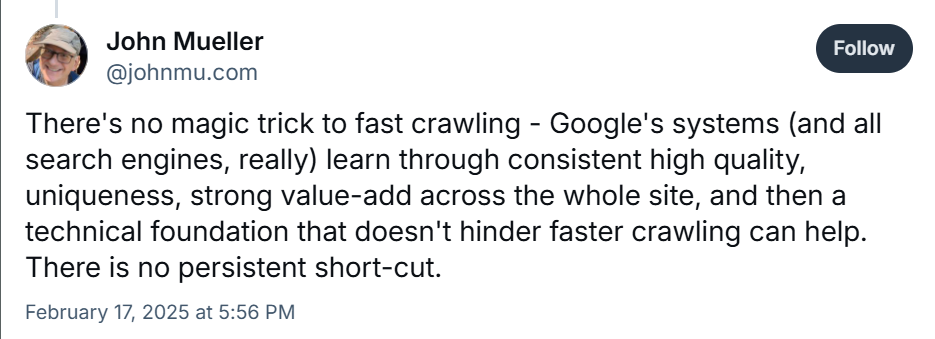
Via Bluesky
Google’s John Mueller reminds us that there’s “no magic trick to fast crawling.” Quality and patience beat brute force. The same ethos applies when you are the crawler.
Scaling Up Safely
Early‑stage crawlers often hammer away with a single script that fetches and parses inline. At scale, that model falls apart. So, how do you manage?
1. Architecture choices
Mature teams separate duties with a queue‑based architecture: fetchers stuff raw HTML into a message queue, parsers pop and process at their own pace.
If one domain starts soft‑blocking, you simply pause its queue while the rest of the pipeline hums along.
2. Headless browsing
JavaScript‑heavy targets demand headless‑browser farms. A Kubernetes or Nomad cluster running Playwright nodes sits behind a smart proxy router. Browser instances handle login flows, infinite‑scroll, and token‑setting challenges, while lightweight HTTP clients collect static pages at a fraction of the cost.
3. Smarter storage
Everything you fetch is worth saving twice: once as raw bytes in object storage, once as structured output. That checkpointable storage means schema tweaks trigger a re‑parse, not a re‑crawl. This way, you save both proxy bandwidth and goodwill.
4. Compliance and ethics
Compliance runs alongside engineering. Before unleashing a spider, run a Terms‑of‑Service audit (some sites flat‑out forbid automated access).
Strip personal data you never intended to collect to stay clear of GDPR/CCPA. Finally, wire in a global kill switch so that any unexpected 4xx attack can stop a domain in seconds instead of hours.
As Cloudflare engineers note, the bot arms race “isn’t sustainable,” and that’s for both sides; your long‑term success relies on how politely you crawl the web.
Observability and Self‑Healing: Spotting Blocks Before They Hurt
Even the most courteous crawler will eventually trigger some alarms. What separates pros from the rest is real‑time feedback.
- Treat 429s as telemetry, not failure. The HTTP 429 code means “Too Many Requests.” Modern servers often pair it with a Retry‑After header. Honor it, then back off exponentially with jitter to avoid “thundering herd” retries.
- Codify back‑off strategy. Both AWS and Google SDKs bake in exponential back‑off because it stabilises distributed systems. Borrow the pattern: double the wait after each failure up to a cap, sprinkle approximately 10 % randomness, and carry on.
- Stream metrics instead of logs. Emit counters for success, soft‑block (blank HTML), hard‑block (403/451), and CAPTCHA events. Pipe them into a tool like Grafana or DataDog and set alerts.
For instance, “>5 % CAPTCHA solves per minute” triggers an auto‑throttle.
- Autoscale thoughtfully. When latencies drop and error rates stay flat, let the orchestrator add workers, but cap per‑domain concurrency. Nothing torpedoes a brand relationship faster than an accidental 10x spike in fetch rate.
- Shadow‑test new tactics. Before rolling out an aggressive browser‑automation tweak, mirror 1 % of traffic through it and compare block rates. If the shadow channel gets clobbered, roll back silently.
Observability becomes your early‑warning radar when you do it right. Your problems will show up as a gentle slope on a chart, not an angry email from a legal team somewhere.
DIY vs Managed: When a Service Like Grepsr Makes Sense
We get it, building this web scraping system yourself is rewarding. But it’s also very expensive. Let’s see how much it costs:
| Hidden cost | Verified typical monthly spend at scale |
| Residential proxy bandwidth | Around $8,400 for 1 TB (at $8.4 / GB, mostly pay-as-you-go rate) |
| CAPTCHA solves | $500 to $3,000 for 1 to 3 million solves (at $0.50 to $1.00 per 1,000 solves via 2Captcha) |
| Headless browser infrastructure | $1,241 to $4,964 for a pool of 10 to 40 EC2 c5.xlarge instances |
| Ongoing maintenance (DevOps and anti-bot tweaks) | $9,650 per FTE, calculated from the average base salary of engineering roles |
When data extraction is necessary but engineering headcount is tight, a web scraping service provider like Grepsr is the most sensible option. Grepsr handles rotation, challenge‑solving, and quality checks, then returns clean scraped data in JSON or CSV.
Many readers will still prefer the DIY path, but Grepsr is a pragmatic option if you would rather focus on using the data than fighting captchas.
What Did We Learn? Here’s the Final Takeaway
Web crawling at scale isn’t won by force; it’s won by finesse. Keep these four moves front-of-mind:
- Listen to the signals. Status codes, latency spikes, and CAPTCHAs are feedback loops. Treat them like unit tests for your crawler.
- Show respect. Follow robots.txt, rotate residential IPs, and pace requests with human-style “think time.”
- Adapt quickly. Log everything, graph error rates,and auto-throttle at the first hint of a soft block.
- Measure, measure, measure. Keep track of success rates and other vital metrics from day one.
If you need the data but not the headaches, Grepsr is what you need.
Grepsr handles all the complexities of polite, mindful, and smart crawling, and handles you clean JSON so you can focus on using the data, for your AI models, your dynamic pricing engine, or whatever else.
When you’re ready to scale without limits, Grepsr will shoulder the fight.














































































































































