Bad news: financial fraud is industrializing.
From synthetic identities to coordinated account takeovers, fraudsters now use automation, AI, and the open web to stay one step ahead. And the numbers back it up: the cost of fraud for U.S. financial services firms has surged to $4.23 for every $1 lost.
Traditional defenses, like rules, thresholds and internal data can’t keep up. What’s needed now is smarter detection powered by richer context.
And it starts with web data. Let’s learn how it all works out using powerful scraping services like Grepsr.
But first, ask the important questions…
What’s the Problem with Legacy Rule-Based Systems?
Fraud in finance has come a long way from forged checks and fake IDs. Today, you’re up against a fast-moving, technically sharp army of fraudsters exploiting weaknesses.
Financial crime now shows up in many forms such as identity theft, account takeovers, loan fraud, and synthetic identities. It is getting smarter, more subtle, and increasingly difficult to catch with outdated methods.
These are the more common types of financial fraud we are dealing with
- Identity theft: When someone uses stolen personal info to commit fraud.
- Account takeover: Fraudsters gain access to and exploit legitimate accounts.
- Payment fraud: Unauthorized or manipulated transactions.
- Loan fraud: Fake or manipulated applications to secure credit.
- Synthetic identity fraud: Real and fake data mixed to create new, convincing identities.
- Money laundering: Concealing the origin of illicit funds.
So why don’t traditional fraud detection systems cut it anymore?
Because rule-based systems are predictable and rigid. They rely on predefined if-this-then-that rules that are easy for fraudsters to reverse-engineer. When new fraud patterns emerge, rules need to be manually updated constantly.
Plus, these systems struggle with nuance. Subtle, unusual behavior often slips through because these systems can’t handle anomalies well.
Internal data shows you what’s happening inside your walls. It won’t catch fraud rings operating across multiple institutions. Moreover, synthetic identities might look clean when viewed in isolation, but patterns become clear only when you bring in external signals.
This is where AI helps. AI-powered systems, especially those using ML, can
- Recognize complex patterns across massive datasets.
- Adapt and learn from new fraud attempts without manual reprogramming.
- Spot anomalies through unsupervised techniques like clustering and anomaly detection.
- Cut down on false positives

The Web Knows More About Fraud Than Your Database
For fraud detection, web data means the massive pile of publicly available information: social media profiles, forum posts, news articles, business directories, public records, online marketplaces, and even product review sites.
It’s noisy, messy, and often unstructured, but also rich with context that traditional data just doesn’t capture.
Why does this matter? Because fraud rarely happens in a vacuum.
Let’s say you’re reviewing a loan application. Internally, everything checks out: income, address, credit score. But externally? A quick scrape of web data might reveal that the applicant’s supposed employer doesn’t exist, or their name shows up on scam alert forums. This kind of contextual enrichment makes or breaks your fraud model.
Web data also helps with identity verification. Matching names to active LinkedIn or GitHub profiles, checking if a business is registered and has a digital footprint, all help validate that the people (and companies) behind transactions are who they say they are.
PwC’s 2022 Global Economic Crime and Fraud Survey highlights that 43% of the most disruptive or serious fraud incidents experienced by organizations were perpetrated by external actors. The urgency of monitoring external sources for threats could not be more obvious.
Internal data tells you what’s happening. Web data tells you why it might be happening.
What Kind of Web Data Helps in Catching Fraud?
Not every source is relevant for every type of fraud. Different kinds of online information offer valuable signals that boost the accuracy of AI models.
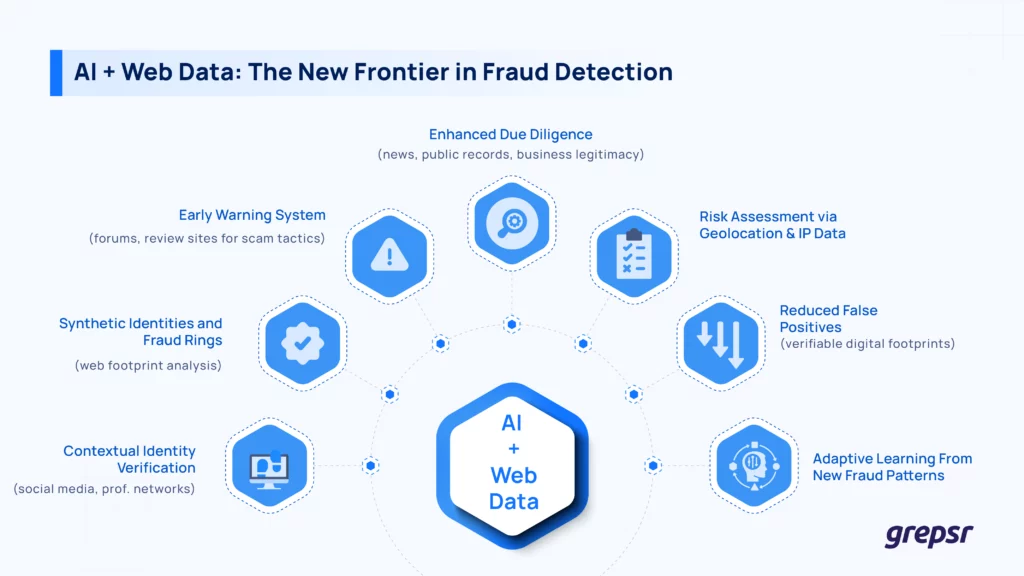
Social media and professional networks
Platforms like LinkedIn, Facebook, etc. help verify whether someone’s identity checks out. Does their LinkedIn show a consistent employment history? Does the location on their profile match their claimed address? Are their connections plausible? This is also valuable for KYC and synthetic ID detection.
Forums and review sites
Online chatter is often where fraud shows up first. People post about sketchy sellers, scam tactics, or leaked info on Reddit, TrustPilot, and the like. These signals help spot fraud trends before they hit your systems.
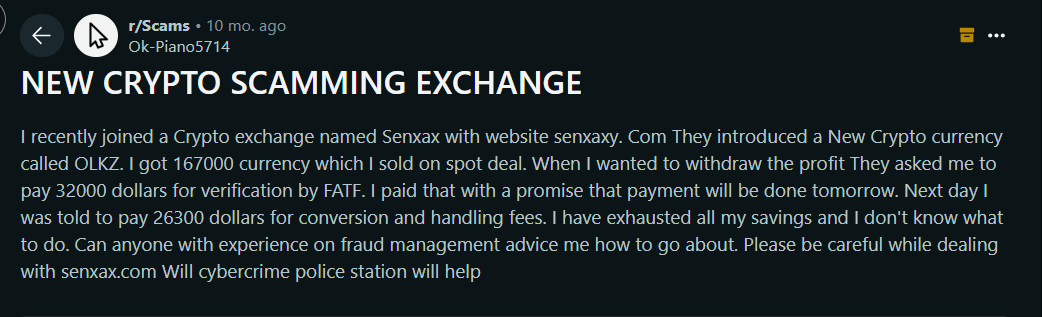
Via Reddit
News outlets and public channels
Adverse media mentions, like in bankruptcies, legal charges, and regulatory sanctions, flag high-risk individuals or businesses. This data adds another layer of due diligence.

Via Reuters
E-commerce and marketplace data
Sellers with inconsistent listings, fake reviews, or recently registered domains might be trying to pull a fast one. Patterns here indicate everything from small-scale scams to organized fraud rings.
IP address and geolocation data.
If someone logs in from a flagged IP or a location that doesn’t match their normal behavior, that’s a red flag. Threat intel feeds online often share risky IPs that can be cross-checked in real time.
The Underworld of the Internet: Leaked Financial Data on the Dark Web
Dark web marketplaces are also a major pipeline for leaked financial data, including credit card numbers, CVVs, bank logins, account balances, fullz (full identity kits), and even session cookies.
Hackers and fraudsters get these assets via credential stuffing, infostealers, man-in-the-middle attacks, or third-party breaches, then aggregate them into structured datasets to sell in bulk.
Much of this data is machine-parseable: dumped JSON, CSV, or plaintext for easy ingestion into bots and scripts. A standard listing might include credit card metadata alongside fraud scores, balance range estimates, or usage history.
Advanced fraud detection models are capable of ingesting threat intelligence from dark web monitoring. For example, such a model could flag accounts whose email appears in recent breach dumps, or link BINs (Bank Identification Numbers) and IP geos to known compromise clusters.
Keep in mind that dark web data is curated and operational. Ignoring it is a big no-no.
But what happens after you have the data, from whatever source?
How to Insert Web Signals Into Your Fraud-Detecting AI Models?
So, how does all of this web data power smarter fraud detection?
It starts with feature engineering: the process of transforming raw web data into structured, machine-readable signals. Web content is scraped, normalized, and then parsed into features like
- Entity validation signals
- Domain age (like days_since_domain_registration)
- Profile consistency (name, location, and employment history should match across platforms)
- Business legitimacy (should have verified registration number, active online footprint)
- Reputation and risk indicators
- Frequency of negative mentions across forums and review sites
- Presence in scam databases or regulatory watchlists
- Connections to high-risk keywords or flagged entities
Once these features are extracted, they’re combined with internal transaction and behavioral data inside supervised or unsupervised learning models.
For example
- In supervised models, labeled fraud or non-fraud cases are used to train classifiers (like XGBoost or Random Forests) that assign risk scores to new events based on patterns observed in both internal and external features.
- In unsupervised setups, clustering and anomaly detection techniques (Isolation Forest, DBSCAN) highlight outliers, like a new account that looks nothing like your baseline customer population, based on online signals.
This dual view (internal behavior + external context) sharpens the model’s judgment.
It also reduces false positives. Suppose a transaction triggers a basic velocity rule. The model will assign a lower risk tier without manual intervention if the associated identity has a well-established, verifiable digital footprint across the web.
And when it comes to sophisticated fraud, like synthetic identities or coordinated fraud rings, web data is often what exposes the cracks. These actors may pass internal checks but fall apart under external scrutiny. For instance
- Their email domain might have been registered just days before.
- Their social media presence may be thin, bot-like, or eerily identical to others in a cluster.
- They might be tied to other flagged accounts via shared contact details or reused identity fragments.
The bottom line is that web data gives fraud-catching models the missing half of the puzzle.
What Can Go Wrong with Web Data?
Integrating web data into AI models isn’t plug-and-play, unless you’re using Grepsr to scrape.
While the benefits are significant, so are the challenges.
Volume and velocity
Web data is massive and constantly in flux. New content is posted every second. AI models need fresh, timely context to be effective, but keeping up with that flow of information in real time is a real engineering feat.
Data quality and noise
And it’s not just the quantity, it’s the quality. Web data is messy: unstructured text, duplicated content, misinformation, fake profiles… It’s all in there.
Making that data useful means building pipelines that can clean, filter, and standardize it. Otherwise, you’re feeding your model noise.
Acquiring the data
Of course, none of that matters if you can’t even get the data in the first place. Crawling and scraping the web at scale is complex. Sites change structure, have bot defenses, and limit access.
Managing proxies, maintaining scrapers, and ensuring compliance is resource-intensive and often outside the scope of most security teams.
The easy way is Grepsr. Grepsr takes care of the entire extraction process, from handling rotating proxies to adapting to site changes, and delivers clean, structured datasets (in CSV or Excel) that are ready for training.
It’s a practical way to close the gap between raw data and usable data.
Web Data Is Messy, But It’s Your Best Defense

In the fight against financial fraud, web data is your first step. It fills in the gaps, catches what internal systems miss, and gives AI the context it needs to make smarter calls.
But turning the chaotic data into clean, actionable insight? That’s the hard part.
Grepsr earns its keep, not just by scraping data, but by structuring it, scaling it, and making it usable without the technical mess.